You might also like
- Seminar Data MiningDocument10 pagesSeminar Data MiningSreedevi KovilakathNo ratings yet
- Data Science Training Institute in HyderabadDocument14 pagesData Science Training Institute in HyderabadkellytechnologiesNo ratings yet
- Mc9280 Data Mining and Data WarehousingDocument1 pageMc9280 Data Mining and Data WarehousingannamyemNo ratings yet
- Data Science Course in Hyderabad - InnomaticsDocument10 pagesData Science Course in Hyderabad - Innomaticscharitha LNo ratings yet
- MM Final ReadyDocument59 pagesMM Final ReadySai Biplab BeheraNo ratings yet
- Sharda Dss10 PPT 08 STDocument14 pagesSharda Dss10 PPT 08 STamalr.dawodNo ratings yet
- Data Warehousing and Data MiningDocument7 pagesData Warehousing and Data MiningDeepti SinghNo ratings yet
- System AnalysisDocument2 pagesSystem Analysisholylike88No ratings yet
- About The Company: 1.1.1. Integrated SolutionsDocument16 pagesAbout The Company: 1.1.1. Integrated SolutionsNANDISH AARYANo ratings yet
- Big Data: Presented by J.Jitendra KumarDocument14 pagesBig Data: Presented by J.Jitendra KumarJitendra KumarNo ratings yet
- Data Mining With Oracle Database 11g Release 2: Competing On In-Database AnalyticsDocument26 pagesData Mining With Oracle Database 11g Release 2: Competing On In-Database AnalyticsArul prakashNo ratings yet
- Introduction To Data Mining: Dr. Dipti Chauhan Assistant Professor SCSIT, SUAS IndoreDocument16 pagesIntroduction To Data Mining: Dr. Dipti Chauhan Assistant Professor SCSIT, SUAS IndoreroochinNo ratings yet
- Data Warehousing and Data Mining TechniquesDocument142 pagesData Warehousing and Data Mining Techniquesmustafa100% (2)
- Data GeneralizationDocument3 pagesData GeneralizationMNaveedsdkNo ratings yet
- Data Mining TutorialsDocument52 pagesData Mining TutorialsxyzNo ratings yet
- Data Analyst SyllabusDocument25 pagesData Analyst SyllabussagarNo ratings yet
- Introduction to Machine Learning FundamentalsDocument26 pagesIntroduction to Machine Learning FundamentalsAkhil SinghNo ratings yet
- PGP in Big Data Analytics and OptimizationDocument16 pagesPGP in Big Data Analytics and Optimizationjprakash0205No ratings yet
- Course Plan - Data MiningDocument3 pagesCourse Plan - Data MiningTushar LangerNo ratings yet
- Introduction To Big Data & Basic Data AnalysisDocument47 pagesIntroduction To Big Data & Basic Data Analysissuyashdwivedi23No ratings yet
- Chapter 1Document35 pagesChapter 1Ipsita PriyadarshiniNo ratings yet
- BT9001: Data Mining - AssignmentDocument6 pagesBT9001: Data Mining - AssignmentPawan MallNo ratings yet
- Business IntelligenceDocument41 pagesBusiness IntelligenceCarlo SerioNo ratings yet
- Big Data Analytics: Challenges and Applications For Text, Audio, Video, and Social Media DataDocument11 pagesBig Data Analytics: Challenges and Applications For Text, Audio, Video, and Social Media DataijscaiNo ratings yet
- Mining Comlex Types of DataDocument19 pagesMining Comlex Types of DataxyzkingNo ratings yet
- Understanding Data MiningDocument21 pagesUnderstanding Data MiningYah yah yahhhhhNo ratings yet
- Advertisement Project (Economics)Document17 pagesAdvertisement Project (Economics)murali muraliNo ratings yet
- 4 Data Science-Big DataDocument22 pages4 Data Science-Big DataAnonymous xmpvkkc8mNo ratings yet
- Big Data Analytics and Its Application in ECommerce GiantsDocument12 pagesBig Data Analytics and Its Application in ECommerce GiantsMohitNo ratings yet
- Web Mining Techniques and ApplicationsDocument13 pagesWeb Mining Techniques and ApplicationsSunil Kr Pandey100% (2)
- Data Warehousing and Data MiningDocument4 pagesData Warehousing and Data MiningRamesh YadavNo ratings yet
- Data Visualization Using Seaborn - Towards Data ScienceDocument31 pagesData Visualization Using Seaborn - Towards Data ScienceudaNo ratings yet
- Unit II-Database Design, Archiitecture - ModelDocument23 pagesUnit II-Database Design, Archiitecture - ModelAditya ThakurNo ratings yet
- Lesson 4 Big Data EcosystemDocument26 pagesLesson 4 Big Data EcosystemNeerom BaldemoroNo ratings yet
- Intorduction To Business - AnalyticsDocument40 pagesIntorduction To Business - AnalyticsAbhimanyu ParmarNo ratings yet
- Machine Learning GuideDocument31 pagesMachine Learning GuideSana AkramNo ratings yet
- Machine LearningDocument21 pagesMachine LearningRachit Joshi100% (1)
- Data Science Talent Gap EmergesDocument6 pagesData Science Talent Gap EmergesDebasishNo ratings yet
- Anomaly Detection SurveyDocument72 pagesAnomaly Detection Surveymath_mallikarjun_sapNo ratings yet
- Data Mining Course Learn Analytics RDocument5 pagesData Mining Course Learn Analytics RAntonio AlvarezNo ratings yet
- Data ScienceDocument52 pagesData Sciencekarthik rs100% (2)
- Stair Reynolds Is Essentials PPT Chapter 9Document59 pagesStair Reynolds Is Essentials PPT Chapter 9Robinson MojicaNo ratings yet
- Applications of Data Mining in The Banking SectorDocument8 pagesApplications of Data Mining in The Banking SectorGunjan JainNo ratings yet
- Clustering Methods for Data MiningDocument60 pagesClustering Methods for Data MiningSuchithra SalilanNo ratings yet
- Unit VIII - Query Processing and SecurityDocument29 pagesUnit VIII - Query Processing and SecurityI SNo ratings yet
- 772s Data - Mining.concepts - And.techniques.2nd - EdDocument239 pages772s Data - Mining.concepts - And.techniques.2nd - EdFaisalJameelNo ratings yet
- CCW331 Business Analytics Material Unit I Type2Document43 pagesCCW331 Business Analytics Material Unit I Type2ultra BNo ratings yet
- Data MiningDocument30 pagesData MiningHarminderSingh Bindra100% (1)
- IBM Q1 Technical Marketing ASSET2 - Data Science Methodology-Best Practices For Successful Implementations Ov37176 PDFDocument6 pagesIBM Q1 Technical Marketing ASSET2 - Data Science Methodology-Best Practices For Successful Implementations Ov37176 PDFxjackxNo ratings yet
- 04 - Functional and NonfunctionalDocument22 pages04 - Functional and Nonfunctionalasroni asroniNo ratings yet
- Public Key Cryptography MathematicsDocument26 pagesPublic Key Cryptography MathematicsK ManeeshNo ratings yet
- Semester: 3 Course Name: Marketing Analytics Course Code: 18JBS315 Number of Credits: 3 Number of Hours: 30Document4 pagesSemester: 3 Course Name: Marketing Analytics Course Code: 18JBS315 Number of Credits: 3 Number of Hours: 30Lipson ThomasNo ratings yet
- Data MiningDocument27 pagesData MiningTestingAccNo ratings yet
- UNIT-1 Introduction To Data MiningDocument29 pagesUNIT-1 Introduction To Data MiningVedhaVyas MahasivaNo ratings yet
- Introduction To Data MiningDocument643 pagesIntroduction To Data MiningDong-gu Jeong100% (1)
- Data Science and AnalyticsDocument3 pagesData Science and Analyticsarbaz khanNo ratings yet
- Computer Skills PDFDocument9 pagesComputer Skills PDFBarham HasoNo ratings yet
- Fundamentals of Information Systems, Seventh Edition: Electronic and Mobile Commerce and Enterprise SystemsDocument71 pagesFundamentals of Information Systems, Seventh Edition: Electronic and Mobile Commerce and Enterprise SystemsTawanda MahereNo ratings yet
- Data Warehousing & Data Mining Syllabus Subject Code:56055 L:4 T/P/D:0 Credits:4 Int. Marks:25 Ext. Marks:75 Total Marks:100Document52 pagesData Warehousing & Data Mining Syllabus Subject Code:56055 L:4 T/P/D:0 Credits:4 Int. Marks:25 Ext. Marks:75 Total Marks:100hanmanthNo ratings yet
- Data Warehouse and Data Mining SyllabusDocument5 pagesData Warehouse and Data Mining SyllabusAltamashNo ratings yet
- HTML MCQDocument7 pagesHTML MCQmannanabdulsattarNo ratings yet
- Data Mining Notes1Document5 pagesData Mining Notes1mannanabdulsattarNo ratings yet
- Server Operating System Windows Hand BookDocument12 pagesServer Operating System Windows Hand BookmannanabdulsattarNo ratings yet
- Unit 6Document29 pagesUnit 6mannanabdulsattarNo ratings yet
- Write An ALP For All Arithematic Operations and Write ALP For Product of Two Numbers Withoutusing MUL OperationDocument3 pagesWrite An ALP For All Arithematic Operations and Write ALP For Product of Two Numbers Withoutusing MUL OperationmannanabdulsattarNo ratings yet
- Associion Rule MiningDocument19 pagesAssociion Rule MiningmannanabdulsattarNo ratings yet
- ACA Unit 3Document58 pagesACA Unit 3mannanabdulsattarNo ratings yet
- Advanced Computer Architecture FundamentalsDocument29 pagesAdvanced Computer Architecture FundamentalsmannanabdulsattarNo ratings yet
- Gate 2009 CS Answer KeysDocument4 pagesGate 2009 CS Answer KeysmannanabdulsattarNo ratings yet
- AcaDocument1 pageAcamannanabdulsattarNo ratings yet
- Memory Hierarchy Design UNIT-V - Reducing Cache Miss Penalty and Rate via ParallelismDocument54 pagesMemory Hierarchy Design UNIT-V - Reducing Cache Miss Penalty and Rate via ParallelismmannanabdulsattarNo ratings yet
- Windows XP Short KeysDocument4 pagesWindows XP Short KeysmaheshrvrNo ratings yet
- CS1993Document15 pagesCS1993anon-810642No ratings yet
- CS1994Document14 pagesCS1994inaylakNo ratings yet
- CS1991Document13 pagesCS1991mannanabdulsattarNo ratings yet
- Network Directory Has Been Removed: - For HP Workstations (Aegis, Intrepid) - RecommendedDocument3 pagesNetwork Directory Has Been Removed: - For HP Workstations (Aegis, Intrepid) - RecommendedmannanabdulsattarNo ratings yet
- PMR5406 Redes Neurais e Lógica Fuzzy: Aula 3 Single Layer PercetronDocument20 pagesPMR5406 Redes Neurais e Lógica Fuzzy: Aula 3 Single Layer PercetronYatin BajajNo ratings yet
- Operating Systems Lab Manual JNTUDocument9 pagesOperating Systems Lab Manual JNTUmannanabdulsattar100% (1)
- OS2Document2 pagesOS2mannanabdulsattarNo ratings yet
- Software Quality Assurance and TestingDocument1 pageSoftware Quality Assurance and TestingmannanabdulsattarNo ratings yet
- Computer Graphics JNTU Question PaperDocument4 pagesComputer Graphics JNTU Question PapermannanabdulsattarNo ratings yet
- Operating Systems BasicsDocument1 pageOperating Systems BasicsmannanabdulsattarNo ratings yet
- IT 103 Presentation 1 Lesson1Document31 pagesIT 103 Presentation 1 Lesson1Zed DeguzmanNo ratings yet
- Public Key Cryptography: S. Erfani, ECE Dept., University of Windsor 0688-558-01 Network SecurityDocument7 pagesPublic Key Cryptography: S. Erfani, ECE Dept., University of Windsor 0688-558-01 Network SecurityAbrasaxEimi370No ratings yet
- Centos - SELinux Preventing Apache From Writing To A File - Server FaultDocument3 pagesCentos - SELinux Preventing Apache From Writing To A File - Server FaultSerban-Alexandru UriciucNo ratings yet
- Oracle9I (9.2.0.4.0) Installation On Redhat Advanced Server 3.0 LinuxDocument5 pagesOracle9I (9.2.0.4.0) Installation On Redhat Advanced Server 3.0 Linuxhieptrung01No ratings yet
- Database Security - FullPaperDocument6 pagesDatabase Security - FullPaperЛюбовь ТарановаNo ratings yet
- 17.the Three-Tier Security Scheme in Wireless Sensor Networks With Mobile SinksDocument8 pages17.the Three-Tier Security Scheme in Wireless Sensor Networks With Mobile SinksDipali AkhareNo ratings yet
- Asap Vs Activate MethodologyDocument1 pageAsap Vs Activate MethodologykrishnakishoregaddamNo ratings yet
- HANA Administration and Operations PTDocument8 pagesHANA Administration and Operations PTFarheen MDNo ratings yet
- Install and Use BlenderAe AddonDocument4 pagesInstall and Use BlenderAe AddonD'MarinhoNo ratings yet
- Thasaamah Technology Profile - Dubai, UAEDocument10 pagesThasaamah Technology Profile - Dubai, UAEAvcom TechnologiesNo ratings yet
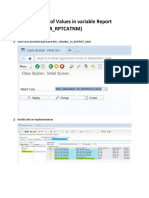
- Restricting List of Values in Variable Report CategoryDocument7 pagesRestricting List of Values in Variable Report CategoryGandhi GoditiNo ratings yet
- Radeon Software Command Line Installation User GuideDocument5 pagesRadeon Software Command Line Installation User GuideSigitNo ratings yet
- Technical Bulletin - GPS ROLLOVER: Furuno Sat-C / Mini-CDocument3 pagesTechnical Bulletin - GPS ROLLOVER: Furuno Sat-C / Mini-CNgoHai100% (1)
- Summer Internship 2019: Reculta Solutions, GurgaonDocument6 pagesSummer Internship 2019: Reculta Solutions, GurgaonAbhishek KujurNo ratings yet
- Sybase Unwired Platform1Document3 pagesSybase Unwired Platform1Kai KonsapNo ratings yet
- Q1 - Chapter 1-AnswerkeyDocument3 pagesQ1 - Chapter 1-AnswerkeyGet BurnNo ratings yet
- CEW Network Project TemplateDocument2 pagesCEW Network Project TemplateSuravi DuttaNo ratings yet
- EdYoda Data Scientist Program CurriculumDocument20 pagesEdYoda Data Scientist Program Curriculummohd. zahid asnariNo ratings yet
- DB 2 CCC 1Document1,133 pagesDB 2 CCC 1Tony LiaoNo ratings yet
- Java Beans: Web Technologies - Unit-4Document7 pagesJava Beans: Web Technologies - Unit-4Jyoti SukhijaNo ratings yet
- Installation, Configuration, and Administration Guide SAP NetWeaver Single Sign-On SP1 - Secure Login Client PDFDocument60 pagesInstallation, Configuration, and Administration Guide SAP NetWeaver Single Sign-On SP1 - Secure Login Client PDFcarlosmallebreraNo ratings yet
- Aldi PDFDocument20 pagesAldi PDFRoselia AjpacajaNo ratings yet
- ScriptingSiebelDocument69 pagesScriptingSiebelanishkrai100% (1)
- A Study of Erlang ETS TableDocument13 pagesA Study of Erlang ETS Tableapi-3771339100% (1)
- 60.college Event Management SystemDocument5 pages60.college Event Management SystemArpit TyagiNo ratings yet
- Hijra Bank Installation Guide For Kaspersky Security CenterDocument54 pagesHijra Bank Installation Guide For Kaspersky Security Centermohammed JundiNo ratings yet
- Wallstreet Financial Trading SystemDocument9 pagesWallstreet Financial Trading SystemJustout BeiberNo ratings yet
- Linux commands file operationsDocument9 pagesLinux commands file operationsso gupta0% (1)
- Hotel Management System Minor ProjectDocument26 pagesHotel Management System Minor ProjectRachit GuptaNo ratings yet
- Case Study On Cloud SecurityDocument11 pagesCase Study On Cloud SecurityJohn Singh100% (1)