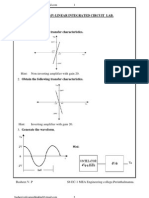
You might also like
- cs3362 Foundations of Data Science Lab ManualDocument53 pagescs3362 Foundations of Data Science Lab ManualJegatheeswari ic3772183% (6)
- Agni College PSPP Questions: Python Programming EssentialsDocument4 pagesAgni College PSPP Questions: Python Programming Essentialsjayanthikrishnan100% (3)
- Computer Concepts and C Programming Unit 12310CCP13 by Sushma Shetty PDFDocument130 pagesComputer Concepts and C Programming Unit 12310CCP13 by Sushma Shetty PDFDivya ShriNo ratings yet
- Computer Network Gate MCQ QuesDocument40 pagesComputer Network Gate MCQ QuesAMAN RAJNo ratings yet
- Question BankDocument22 pagesQuestion Bankshalika booma100% (3)
- AVR Microcontroller Question BankDocument2 pagesAVR Microcontroller Question BankmadhurithkNo ratings yet
- Python For Data Science PDFDocument30 pagesPython For Data Science PDFpdrpatnaik100% (5)
- Questions On Arithmetic CircuitsDocument32 pagesQuestions On Arithmetic Circuitskibrom atsbha0% (1)
- Web - Technology (Questions & Answers For Lab Viva)Document18 pagesWeb - Technology (Questions & Answers For Lab Viva)Tejaswi Maligireddy67% (3)
- Computer Networks Lab Viva QuestionsDocument22 pagesComputer Networks Lab Viva Questionssiva kumaar0% (1)
- Digital Logic Design and Computer OrganizationDocument227 pagesDigital Logic Design and Computer OrganizationRadhika Rani100% (2)
- Coa Viva QuestionsDocument15 pagesCoa Viva QuestionsSaif100% (1)
- Data Communications and Networks Lab ManualDocument69 pagesData Communications and Networks Lab ManualAkkonduru Kumar100% (3)
- Introduction To Digital Design Module1Document24 pagesIntroduction To Digital Design Module1Dhananjaya100% (2)
- Microprocessor & Microcontroller (Book)Document179 pagesMicroprocessor & Microcontroller (Book)manish kumar50% (2)
- Data Structures and Algorithms QuestionsDocument8 pagesData Structures and Algorithms QuestionsDeepa V.VNo ratings yet
- Códigos de Error MicroMotionDocument2 pagesCódigos de Error MicroMotionCarlos Zamyr GonzalezNo ratings yet
- L298N Motor DriverDocument7 pagesL298N Motor DrivercerenautaNo ratings yet
- Data Types in CDocument19 pagesData Types in CEr. Sunali Sharma100% (1)
- Gitam Data Communication Semester End Question PaperDocument2 pagesGitam Data Communication Semester End Question Paper121710304013 CH V ANJANI SAI JAISHEELNo ratings yet
- Question Bank Solutions (Module-2-IAT 1) - IOT - 15CS81Document12 pagesQuestion Bank Solutions (Module-2-IAT 1) - IOT - 15CS81Shobhit Kushwaha100% (1)
- Infosys SP(9.5LPA) & DSP(6.25LPA) Exam QuestionsDocument27 pagesInfosys SP(9.5LPA) & DSP(6.25LPA) Exam QuestionsDigvijay SinghNo ratings yet
- Data Structures and Applications Questions From Old VTU Question PapersDocument4 pagesData Structures and Applications Questions From Old VTU Question PapersAbubaker SiddiqueNo ratings yet
- Data Structures Using Java - Lab ManualDocument48 pagesData Structures Using Java - Lab Manualkishore kumar80% (5)
- OS Viva Expected QuestionsDocument7 pagesOS Viva Expected Questionsaamer_shahbaazNo ratings yet
- Microcontroller Lab Viva Questions & AnswersDocument29 pagesMicrocontroller Lab Viva Questions & AnswersAmbika Narayan73% (15)
- CAO AssignmentDocument44 pagesCAO AssignmentAbhishek Dixit40% (5)
- Digital Electronics Lab Viva QuestionsDocument2 pagesDigital Electronics Lab Viva Questionspramodrp200750% (8)
- DCN Viva QuestionsDocument14 pagesDCN Viva QuestionsSerena VascoNo ratings yet
- PPS Important Questions Computer ProgrammingDocument2 pagesPPS Important Questions Computer Programmingpradeep100% (3)
- Vtu 3RD Sem Cse Data Structures With C Notes 10CS35Document64 pagesVtu 3RD Sem Cse Data Structures With C Notes 10CS35EKTHATIGER63359075% (24)
- Assignment 2 (SPOS) EditedDocument12 pagesAssignment 2 (SPOS) EditedOmkar Thange100% (1)
- DBMS-Super Important questions-18CS53Document4 pagesDBMS-Super Important questions-18CS53Death WarriorNo ratings yet
- Cs3351 Digital Principles and Computer Organization Lab Record PDFDocument45 pagesCs3351 Digital Principles and Computer Organization Lab Record PDFSachin Svs100% (2)
- Communication Round - HexawareDocument4 pagesCommunication Round - Hexawarearjun allu100% (2)
- C# .NET Question Bank for RTM Nagpur UniversityDocument16 pagesC# .NET Question Bank for RTM Nagpur UniversitySara RaiNo ratings yet
- System Software Notes 5TH Sem VtuDocument27 pagesSystem Software Notes 5TH Sem VtuNeha Chinni100% (3)
- Code MigrationDocument8 pagesCode MigrationNazmus Sadat Shaiekh67% (3)
- Computer Organization and Architecture (18EC35) - Input/Output Organization (Module 3)Document82 pagesComputer Organization and Architecture (18EC35) - Input/Output Organization (Module 3)Shrishail Bhat50% (2)
- Pe Lab Viva QuestionsDocument15 pagesPe Lab Viva Questionssujithmrinal100% (5)
- Computer Organization and Architecture - Basic Processing Unit (Module 5)Document76 pagesComputer Organization and Architecture - Basic Processing Unit (Module 5)Shrishail BhatNo ratings yet
- SBL Part 1 Viva QuestionsDocument11 pagesSBL Part 1 Viva QuestionsRitesh Sonawane100% (1)
- CN Lab Viva QuestionsDocument4 pagesCN Lab Viva QuestionsChetan Raj100% (1)
- Introduction To Electronics and Communication (BESCK104C/BESCK204C) - Embedded Systems (Module 4)Document79 pagesIntroduction To Electronics and Communication (BESCK104C/BESCK204C) - Embedded Systems (Module 4)Shrishail Bhat100% (1)
- Transmission Lines and Waveguides by Dhananjayan PDFDocument2 pagesTransmission Lines and Waveguides by Dhananjayan PDFRemigild Peter0% (3)
- DCCN Unit-5 Application LayerDocument27 pagesDCCN Unit-5 Application LayersuneelkluNo ratings yet
- Algorithms Quiz AnswersDocument3 pagesAlgorithms Quiz Answersajay negi100% (1)
- String Handling in C PDFDocument3 pagesString Handling in C PDFsairam bijuNo ratings yet
- Data Structures and Application QP VtuDocument9 pagesData Structures and Application QP VtuFazal KhanNo ratings yet
- OS Question Bank Module 1-4Document8 pagesOS Question Bank Module 1-4Vamshidhar Reddy100% (1)
- Microprocessor Viva Questions and AnswersDocument9 pagesMicroprocessor Viva Questions and Answersdhiliban198971% (7)
- Specification of TokensDocument17 pagesSpecification of TokensSMARTELLIGENTNo ratings yet
- 8086 and Memory Interfacing - FinalDocument28 pages8086 and Memory Interfacing - FinalAnushkaSinha100% (2)
- Choosing Hardware Components for Wireless Sensor NodesDocument43 pagesChoosing Hardware Components for Wireless Sensor NodesRavi AnnepakaNo ratings yet
- Data Handling Using Pandas-1: Long Answer QuestionsDocument1 pageData Handling Using Pandas-1: Long Answer Questionsvikas_2No ratings yet
- 21EC44 SyllabusDocument3 pages21EC44 SyllabusManjunathNo ratings yet
- Algorithm and Data Structures for a Linker LoaderDocument13 pagesAlgorithm and Data Structures for a Linker Loaderqwdfgh100% (1)
- EC8381 Fundamentals of Data Structures in C LaborataryDocument88 pagesEC8381 Fundamentals of Data Structures in C LaborataryVive Kowsal Yaniss100% (3)
- VTU Exam Question Paper With Solution of 18EE52 Microcontrollers Feb-2021-Ranjitha RDocument30 pagesVTU Exam Question Paper With Solution of 18EE52 Microcontrollers Feb-2021-Ranjitha RSupritha100% (5)
- PipeliningDocument8 pagesPipeliningManoj Reddy GudaNo ratings yet
- CAO-II Module 2 CompleteDocument32 pagesCAO-II Module 2 CompleteAsim Arunava Sahoo100% (1)
- Chapter 5 - CO - BIM - IIIDocument7 pagesChapter 5 - CO - BIM - IIIAnkit ShresthaNo ratings yet
- IBM System x3650 M5Document2 pagesIBM System x3650 M5wingNo ratings yet
- 4CS015Week6CPUArchitecture 90180Document39 pages4CS015Week6CPUArchitecture 90180np03cs4a230235No ratings yet
- Unisight Enterprise ManualDocument35 pagesUnisight Enterprise ManualLeLouch LamperougeNo ratings yet
- 64 BitsDocument8 pages64 BitsTatyanazaxarova2No ratings yet
- Atmel Q TouchDocument12 pagesAtmel Q TouchbbooggaarrttNo ratings yet
- Richland College Engineering Technology Digital Fundamentals Lab 8 Asynchronous Counter ApplicationsDocument6 pagesRichland College Engineering Technology Digital Fundamentals Lab 8 Asynchronous Counter ApplicationsAlasnuyoNo ratings yet
- Kenwood KRF v5200d S SMDocument40 pagesKenwood KRF v5200d S SMpriyanthaNo ratings yet
- 4 Phase ULN2003 Stepper Motor Driver PCB: A B C D V+Document3 pages4 Phase ULN2003 Stepper Motor Driver PCB: A B C D V+ZadidNo ratings yet
- MC74HC14A Hex Schmitt Trigger Inverter: High Performance Silicon Gate CMOSDocument7 pagesMC74HC14A Hex Schmitt Trigger Inverter: High Performance Silicon Gate CMOSСтефан ТасиќNo ratings yet
- DEL Lab ManualDocument68 pagesDEL Lab ManualMohini AvatadeNo ratings yet
- Motherboard Manual Ga-7ixe4 eDocument67 pagesMotherboard Manual Ga-7ixe4 ebulkanoNo ratings yet
- P89V51RD2Document45 pagesP89V51RD2ashwini_mathapati255100% (1)
- STLD - 1st ShauryaDocument19 pagesSTLD - 1st ShauryaMudit PandeyNo ratings yet
- Datasheet IR - 4427SDocument12 pagesDatasheet IR - 4427SmazinswNo ratings yet
- Bde Unit IVDocument21 pagesBde Unit IVVoice NftNo ratings yet
- EE 595 Simulation and Timing in VHDLDocument15 pagesEE 595 Simulation and Timing in VHDLbijoiuuNo ratings yet
- Blueprint For Control EngineringDocument23 pagesBlueprint For Control Engineringyisakabera123No ratings yet
- Computer Science & Its Application in DefenceDocument200 pagesComputer Science & Its Application in DefenceRitankar MandalNo ratings yet
- Android Based Message Conveying System Using Bluetooth PDFDocument2 pagesAndroid Based Message Conveying System Using Bluetooth PDFElins JournalNo ratings yet
- ATtiny13, ATtiny2313, Instruction SetDocument19 pagesATtiny13, ATtiny2313, Instruction SetMihai PaunNo ratings yet
- Lic Lab Model QuestionsDocument13 pagesLic Lab Model QuestionsbasheervpNo ratings yet
- VivA QuestionS MPDocument9 pagesVivA QuestionS MPG yugandhar srinivasNo ratings yet
- Hardware Manual: REJ09B0261-0100Document1,692 pagesHardware Manual: REJ09B0261-0100Ferdinand KlautNo ratings yet
- Dynamic Cache Management TechniqueDocument15 pagesDynamic Cache Management Technique185G1 Pragna KoneruNo ratings yet
- Hyper TransportDocument23 pagesHyper TransportJAYESHTRIV0% (1)
- Dell TFT-LCD Color Monitor 1503FP Service ManualDocument8 pagesDell TFT-LCD Color Monitor 1503FP Service Manualsakho1No ratings yet
- MSP430F543xA, MSP430F541xA Mixed-Signal Microcontrollers: 1 Device OverviewDocument115 pagesMSP430F543xA, MSP430F541xA Mixed-Signal Microcontrollers: 1 Device OverviewJerson Andres QuinteroNo ratings yet
- DDI0406B Arm Architecture Reference Manual Errata Markup 8 0Document2,158 pagesDDI0406B Arm Architecture Reference Manual Errata Markup 8 0Sarojini GovindanNo ratings yet