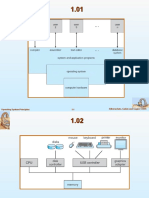
You might also like
- Unit No.7 Crash Recovery & BackupDocument17 pagesUnit No.7 Crash Recovery & BackupPadre BhojNo ratings yet
- 4. DB Backup and RecoveryDocument7 pages4. DB Backup and RecoveryAbhishek SisodiyaNo ratings yet
- Crash RecoveryDocument5 pagesCrash RecoveryRam NathNo ratings yet
- Back Up and RecoveryDocument14 pagesBack Up and RecoveryNavreet SinghNo ratings yet
- Recovery Techniques and Backup OptionsDocument8 pagesRecovery Techniques and Backup OptionssukhbirvirkNo ratings yet
- GNR-18 DBMS Unit-5Document22 pagesGNR-18 DBMS Unit-5Y HarikaNo ratings yet
- Database Presentation SlidesDocument52 pagesDatabase Presentation Slidestanyah LloydNo ratings yet
- .Chapter 5 - 1659084080000Document16 pages.Chapter 5 - 1659084080000Natinale EliasNo ratings yet
- Stages of TransactionDocument6 pagesStages of TransactionsureshkumarmtechNo ratings yet
- A207710262 16469 13 2018 Dbms Data RecoveryDocument3 pagesA207710262 16469 13 2018 Dbms Data RecoverySohel ShaikNo ratings yet
- SecurityDocument6 pagesSecurityyuvrajNo ratings yet
- DBMS II Chapter 3Document11 pagesDBMS II Chapter 3Awoke AdaneNo ratings yet
- Database Recovery:: The Need For RecoveryDocument5 pagesDatabase Recovery:: The Need For Recoverygopi9966957145No ratings yet
- Database Recovery TechniquesDocument46 pagesDatabase Recovery TechniquesFiraol BonsaNo ratings yet
- DP SS2 Week 9 PDFDocument14 pagesDP SS2 Week 9 PDFsophiaNo ratings yet
- ProjoDocument2 pagesProjoChrispine OtienoNo ratings yet
- DBMS Data Recovery TechniquesDocument4 pagesDBMS Data Recovery Techniquesjeti dhawanNo ratings yet
- Chapter FourDocument15 pagesChapter FourDemsew TesfaNo ratings yet
- Firewalls and Database Recovery: A Firewall Can Serve The Following FunctionsDocument13 pagesFirewalls and Database Recovery: A Firewall Can Serve The Following Functionsbhanu pratap singhNo ratings yet
- Chapter 3 - Transaction ManagementDocument46 pagesChapter 3 - Transaction ManagementLegesse SamuelNo ratings yet
- Chapter - 5 Database RecoverytechniquesDocument31 pagesChapter - 5 Database RecoverytechniquesdawodyimerNo ratings yet
- DB BKPDocument14 pagesDB BKPM1No ratings yet
- Database Recovery TechnequesDocument25 pagesDatabase Recovery Technequesusman saleem100% (1)
- Backup and RecoveryDocument35 pagesBackup and RecoverySanjana GargNo ratings yet
- Recovery SystemDocument8 pagesRecovery SystemVivek BhoiNo ratings yet
- Chapter - 5 Database RecoverytechniquesDocument18 pagesChapter - 5 Database RecoverytechniquesdawodNo ratings yet
- Set-B: - A Single Unit of WorkDocument12 pagesSet-B: - A Single Unit of WorkRami ReddyNo ratings yet
- Advanced Database MS 5Document8 pagesAdvanced Database MS 53d nat natiNo ratings yet
- Chapter Three: Transaction Processing ConceptsDocument29 pagesChapter Three: Transaction Processing ConceptsZo ZoNo ratings yet
- ADB Chapter 3Document54 pagesADB Chapter 3anwarsirajfeyeraNo ratings yet
- 2.1 Computer-System OperationDocument20 pages2.1 Computer-System OperationHasib PeyalNo ratings yet
- DBMS Unit-4Document19 pagesDBMS Unit-4Abhishek BhallaNo ratings yet
- Recovery SystemDocument55 pagesRecovery SystemPav TechnicalsNo ratings yet
- ADMS - Chapter FiveDocument34 pagesADMS - Chapter Fiveking hiikeyNo ratings yet
- Chapter 3Document42 pagesChapter 3bilisedejene63No ratings yet
- Module V: Data Recovery and Protection TechniquesDocument47 pagesModule V: Data Recovery and Protection TechniquesIshika SinghalNo ratings yet
- ACID PropertiesDocument26 pagesACID Properties21IF102 Tanvi ArgadeNo ratings yet
- 18Cs53: Database Management Systems: Introduction To Transaction Processing Concepts and TheoryDocument37 pages18Cs53: Database Management Systems: Introduction To Transaction Processing Concepts and TheoryChandan SubramanyaNo ratings yet
- Data Recovery TechniquesDocument21 pagesData Recovery TechniquessamakshNo ratings yet
- Module 5 - Part 1Document72 pagesModule 5 - Part 1Inraj MorangNo ratings yet
- 7 Database RecoveryDocument3 pages7 Database Recoverypeter njugunaNo ratings yet
- Swap Space Explained: How Operating Systems Use Disk Storage as Virtual MemoryDocument4 pagesSwap Space Explained: How Operating Systems Use Disk Storage as Virtual MemoryPrasad DasuvaramNo ratings yet
- COSC 266 Advanced Database Recovery TechniquesDocument35 pagesCOSC 266 Advanced Database Recovery TechniquesAtaklti TekaNo ratings yet
- Unit 4-PagingDocument20 pagesUnit 4-PagingBarani KumarNo ratings yet
- Chapter Six - Backup and Recovery of The Data Warehouse: SATA Technology and Business CollageDocument4 pagesChapter Six - Backup and Recovery of The Data Warehouse: SATA Technology and Business Collagetigistu wogayehu tigeNo ratings yet
- Unit 4-DBMSDocument20 pagesUnit 4-DBMSG KalaiarasiNo ratings yet
- DATABASE RECOVERY SYSTEM PRESENTATIONDocument12 pagesDATABASE RECOVERY SYSTEM PRESENTATIONVirendra SinghNo ratings yet
- Database Security & RecoveryDocument17 pagesDatabase Security & RecoveryAnchal MishraNo ratings yet
- Engine 2018Document45 pagesEngine 2018AloyceNo ratings yet
- Unit 4: Database Backup and Recovery: Non Media FailureDocument15 pagesUnit 4: Database Backup and Recovery: Non Media FailureDhiraj JhaNo ratings yet
- BackupDocument14 pagesBackupmulugetaNo ratings yet
- 7-Chapter Seven Database Recovery TechniquesDocument39 pages7-Chapter Seven Database Recovery TechniquessewasewtadeleNo ratings yet
- Database Lecture11Document30 pagesDatabase Lecture11Watanabe KisekiNo ratings yet
- Memory ManagementDocument42 pagesMemory ManagementmutayebNo ratings yet
- A. Functional Components of A DBMSDocument6 pagesA. Functional Components of A DBMSVipul SharmaNo ratings yet
- 10 DBMSDocument21 pages10 DBMSSK MunafNo ratings yet
- Chapter 3 ADBMSDocument65 pagesChapter 3 ADBMSking hiikeyNo ratings yet
- Unit - IiiDocument15 pagesUnit - Iiisathya priyaNo ratings yet
- Unit-2 OS Ch-1 CompleteDocument18 pagesUnit-2 OS Ch-1 CompleteVaibhavNo ratings yet
- Distributed DBMS Reliability - 3 of 3 (Good)Document35 pagesDistributed DBMS Reliability - 3 of 3 (Good)Lakhveer Kaur0% (1)
- 3 Tier Architecture (Nice)Document9 pages3 Tier Architecture (Nice)Lakhveer KaurNo ratings yet
- Transaction and SQLDocument35 pagesTransaction and SQLLakhveer KaurNo ratings yet
- Indexing and Hashing: B.RamamurthyDocument24 pagesIndexing and Hashing: B.RamamurthyLakhveer KaurNo ratings yet
- A To Z PPT NotesDocument62 pagesA To Z PPT NotesKarthikeyan RamajayamNo ratings yet
- PLSQL Lecture 1 (Nice)Document5 pagesPLSQL Lecture 1 (Nice)Lakhveer KaurNo ratings yet
- PLSQLDocument11 pagesPLSQLAnita AcharyaNo ratings yet
- Lec - PL - SQL (Nice)Document14 pagesLec - PL - SQL (Nice)Lakhveer KaurNo ratings yet
- PL SQLDocument41 pagesPL SQLmeetravi007No ratings yet
- Distributed DBMS (Good)Document58 pagesDistributed DBMS (Good)Lakhveer KaurNo ratings yet
- 2nd UnitDocument3 pages2nd UnitLakhveer KaurNo ratings yet
- 10 1 1 107Document35 pages10 1 1 107Lakhveer KaurNo ratings yet
- CH 01Document11 pagesCH 01Lakhveer KaurNo ratings yet
- 1.9 Scheduling CriteriaDocument7 pages1.9 Scheduling CriteriaLakhveer KaurNo ratings yet
- Explain About Distributed SystemsDocument24 pagesExplain About Distributed SystemsLakhveer KaurNo ratings yet
- Fundamentals of DBMSS, Elmsari and NavatheDocument33 pagesFundamentals of DBMSS, Elmsari and NavatheLakhveer Kaur100% (1)
- 1.10 Scheduling AlgorithmsDocument5 pages1.10 Scheduling AlgorithmsLakhveer KaurNo ratings yet
- 1.7 Process ConceptsDocument2 pages1.7 Process ConceptsLakhveer KaurNo ratings yet
- Lossless DecompositionDocument25 pagesLossless DecompositionLakhveer KaurNo ratings yet
- 1.3 Distributed OsDocument1 page1.3 Distributed OsLakhveer KaurNo ratings yet
- Lossless DecompositionDocument25 pagesLossless DecompositionLakhveer KaurNo ratings yet
- Basic File Handling in CDocument33 pagesBasic File Handling in CUbaid_Ullah_Fa_1194No ratings yet
- Wakanda Studio Ref Guide v1 BetaDocument249 pagesWakanda Studio Ref Guide v1 Betarnbd12No ratings yet
- Module 16 - BACKUP and RECOVERYDocument35 pagesModule 16 - BACKUP and RECOVERYGautam TrivediNo ratings yet
- Critical Heat Flux PDFDocument32 pagesCritical Heat Flux PDFahmadstNo ratings yet
- 2023 Release Platform SpecificationsDocument13 pages2023 Release Platform SpecificationsgyuregabiNo ratings yet
- Angular 6 CRUD Example - MEAN Stack TutorialDocument39 pagesAngular 6 CRUD Example - MEAN Stack TutorialEstebanRodriguezNo ratings yet
- Preliminary InvestigationDocument48 pagesPreliminary InvestigationJay ChauhanNo ratings yet
- Database Security V1 1Document43 pagesDatabase Security V1 1Siva AjayNo ratings yet
- Web3: The Next Internet RevolutionDocument12 pagesWeb3: The Next Internet RevolutionClaudioNo ratings yet
- SMS Messaging Server Administrators ManualDocument40 pagesSMS Messaging Server Administrators ManualOlascholarNo ratings yet
- Pile Group Tool DocumentationDocument30 pagesPile Group Tool DocumentationzomungNo ratings yet
- Microsoft Dynamics SL Release 2018 CU1 Release NotesDocument6 pagesMicrosoft Dynamics SL Release 2018 CU1 Release NotesAlex ChimalNo ratings yet
- 1.1 Problem Statement: Laundry Management SystemDocument42 pages1.1 Problem Statement: Laundry Management SystemShravan J PoojaryNo ratings yet
- M.tech 1st Year SyllabusDocument13 pagesM.tech 1st Year SyllabusarshiNo ratings yet
- SMU DATABASE MANAGEMENT SYSTEM ASSIGNMENTDocument27 pagesSMU DATABASE MANAGEMENT SYSTEM ASSIGNMENTsirishkhNo ratings yet
- LibraryDocument217 pagesLibraryAvinash SinghNo ratings yet
- INFORMATION MANAGEMENT 1 | LABORATORY MANUALDocument92 pagesINFORMATION MANAGEMENT 1 | LABORATORY MANUALBermelita Domingo100% (1)
- Ahmeduddin ResumeDocument10 pagesAhmeduddin Resumeabhay.rajauriya1No ratings yet
- Fti Reference GuideDocument170 pagesFti Reference Guidepankaj1986pankNo ratings yet
- Effects of Television On Youth - Group DiscussionDocument19 pagesEffects of Television On Youth - Group DiscussionVivekNo ratings yet
- PostgreSQL TutorialDocument13 pagesPostgreSQL TutorialSjsns100% (1)
- Maintenance Data Documentation: 15 NOVEMBER 2009Document202 pagesMaintenance Data Documentation: 15 NOVEMBER 2009hankthedogNo ratings yet
- Enhanced Microsoft Office 2013 Illustrated Introductory First Course 1st Edition Beskeen Solutions ManualDocument12 pagesEnhanced Microsoft Office 2013 Illustrated Introductory First Course 1st Edition Beskeen Solutions Manualedwardscotttqyxsjzcnb100% (16)
- Dell Wyse Device Manager 5.7 Administrator's GuideDocument259 pagesDell Wyse Device Manager 5.7 Administrator's GuideChampignolNo ratings yet
- A Global Laboratory Informatics Company Making Labs Digital - Electronic Lab Notebook SoftwareDocument25 pagesA Global Laboratory Informatics Company Making Labs Digital - Electronic Lab Notebook SoftwareAgaram TechnologiesNo ratings yet
- 5 6176815269806081614Document11 pages5 6176815269806081614Hiren KumarNo ratings yet
- Futsal Management Report PDFDocument37 pagesFutsal Management Report PDFJUNU CHAULAGAIN100% (1)
- Capstone IBM ProjectDocument131 pagesCapstone IBM ProjectusuariodenewsNo ratings yet
- Overview OracleDocument27 pagesOverview OracleJoão SousaNo ratings yet
- Assess Project Performance DatabaseDocument13 pagesAssess Project Performance DatabaseNur AdilahNo ratings yet
- Informatica Powercenter 7 Level I Developer: Education ServicesDocument289 pagesInformatica Powercenter 7 Level I Developer: Education Servicesnagaaytha100% (1)