You might also like
- ITNE3006 Design Network Infrastructure: AssignmentDocument12 pagesITNE3006 Design Network Infrastructure: Assignmentqwerty100% (1)
- Heat TreatmentsDocument14 pagesHeat Treatmentsravishankar100% (1)
- Powerpoint Presentation R.A 7877 - Anti Sexual Harassment ActDocument14 pagesPowerpoint Presentation R.A 7877 - Anti Sexual Harassment ActApple100% (1)
- Week 7 Apple Case Study FinalDocument18 pagesWeek 7 Apple Case Study Finalgopika surendranathNo ratings yet
- Evaluation of NOC Using Tightly Coupled Router Architecture: Bharati B. Sayankar, Pankaj AgrawalDocument5 pagesEvaluation of NOC Using Tightly Coupled Router Architecture: Bharati B. Sayankar, Pankaj AgrawalIOSRjournalNo ratings yet
- A Simple Self-Timed Implementation of A Priority Queue For Dictionary Search ProblemsDocument6 pagesA Simple Self-Timed Implementation of A Priority Queue For Dictionary Search ProblemsSahilYadavNo ratings yet
- 6.automation, Virtualization, Cloud, SDN, DNADocument23 pages6.automation, Virtualization, Cloud, SDN, DNAHoai Duc HoangNo ratings yet
- IJECE - Design and Implementation of An On CHIP JournalDocument8 pagesIJECE - Design and Implementation of An On CHIP Journaliaset123No ratings yet
- An Efficient Folded Architecture For Lifting-Based Discrete Wavelet TransformDocument5 pagesAn Efficient Folded Architecture For Lifting-Based Discrete Wavelet Transformcheezesha4533No ratings yet
- Abcdplace Tcad2020 LinDocument13 pagesAbcdplace Tcad2020 LinEric WangNo ratings yet
- Efficient Priority Queue Data Structure For Hardware ImplementationDocument16 pagesEfficient Priority Queue Data Structure For Hardware ImplementationFaisal IrfanNo ratings yet
- DivyasriDocument21 pagesDivyasrivenkata satishNo ratings yet
- 16 Dynamic FullDocument14 pages16 Dynamic FullTJPRC PublicationsNo ratings yet
- Lab 1 Identifying Network Architectures and EquipmentsDocument17 pagesLab 1 Identifying Network Architectures and EquipmentsFarisHaikalNo ratings yet
- A Review-Analysis of Network Topologies For MicroenterprisesDocument7 pagesA Review-Analysis of Network Topologies For MicroenterprisesLionaFerIvanNo ratings yet
- Routing and Multicast in Multihop, Mobile Wireless NetworksDocument6 pagesRouting and Multicast in Multihop, Mobile Wireless NetworksrishikarthickNo ratings yet
- Q S O M: Karol MolnárDocument6 pagesQ S O M: Karol MolnárMinhdat PtitNo ratings yet
- Topological Sorting of Large NetworksDocument5 pagesTopological Sorting of Large NetworksPepeNo ratings yet
- Gap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarDocument7 pagesGap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarSunil ChaluvaiahNo ratings yet
- Huawei RTN A Modo Transparente RTN910Document10 pagesHuawei RTN A Modo Transparente RTN910julu paezNo ratings yet
- A Novel Algorithm For Distribution Netwo PDFDocument6 pagesA Novel Algorithm For Distribution Netwo PDFmunnakumar1No ratings yet
- Topology: Computer Network (Module 1) (DPP)Document26 pagesTopology: Computer Network (Module 1) (DPP)anup03_33632081No ratings yet
- Segment-Based Routing: An Efficient Fault-Tolerant Routing Algorithm For Meshes and ToriDocument10 pagesSegment-Based Routing: An Efficient Fault-Tolerant Routing Algorithm For Meshes and ToriDivyesh MaheshwariNo ratings yet
- Router Level Load Matching Tools in WMN - A SurveyDocument2 pagesRouter Level Load Matching Tools in WMN - A SurveyIJRAERNo ratings yet
- 2019 - ASA-routing A-Star Adaptive Routing Algorithm For Network-on-Chips 18th ASA-routing A-Star Adaptive Routing Algorithm For NetwDocument13 pages2019 - ASA-routing A-Star Adaptive Routing Algorithm For Network-on-Chips 18th ASA-routing A-Star Adaptive Routing Algorithm For NetwHypocrite SenpaiNo ratings yet
- Rethinking The Service Model: Scaling Ethernet To A Million NodesDocument6 pagesRethinking The Service Model: Scaling Ethernet To A Million Nodesbalachandran99No ratings yet
- 10 - Cloud-Based OLAP Over Big Data Application Scenarious and Performance AnalysisDocument7 pages10 - Cloud-Based OLAP Over Big Data Application Scenarious and Performance AnalysisSourabhNo ratings yet
- MSME CI AnalysisNoteDocument5 pagesMSME CI AnalysisNoteArif Nur HidayatNo ratings yet
- Wingz Technologies 9840004562: A Scalable and Modular Architecture For High-Performance Packet ClassificationDocument10 pagesWingz Technologies 9840004562: A Scalable and Modular Architecture For High-Performance Packet ClassificationReni JophyNo ratings yet
- On The Extreme Parallelism Inside Next-Generation Network ProcessorsDocument9 pagesOn The Extreme Parallelism Inside Next-Generation Network ProcessorsNaser AlshafeiNo ratings yet
- Optimizing Routing Rules Space Through Traffic Engineering Based On Ant Colony Algorithm in Software Defined NetworkDocument7 pagesOptimizing Routing Rules Space Through Traffic Engineering Based On Ant Colony Algorithm in Software Defined NetworkTibebu Xibe TeNo ratings yet
- Written by Jun Ho Bahn (Jbahn@uci - Edu) : Overview of Network-on-ChipDocument5 pagesWritten by Jun Ho Bahn (Jbahn@uci - Edu) : Overview of Network-on-ChipMitali DixitNo ratings yet
- Clock Tree Synthesis Under Aggressive Buffer Insertion: Ying-Yu Chen, Chen Dong, Deming ChenDocument4 pagesClock Tree Synthesis Under Aggressive Buffer Insertion: Ying-Yu Chen, Chen Dong, Deming ChenSudheer GangisettyNo ratings yet
- Rethinking The Service Model Scaling Ethernet To A Million Nodes2004 PDFDocument6 pagesRethinking The Service Model Scaling Ethernet To A Million Nodes2004 PDFChuang JamesNo ratings yet
- Core Techniques On Designing Network For Data Centers: A Comparative AnalysisDocument4 pagesCore Techniques On Designing Network For Data Centers: A Comparative AnalysisBeliz CapitangoNo ratings yet
- Computer Generation of Streaming Sorting NetworksDocument9 pagesComputer Generation of Streaming Sorting Networksdang2327No ratings yet
- Coordinated Network Scheduling: A Framework For End-to-End ServicesDocument11 pagesCoordinated Network Scheduling: A Framework For End-to-End ServiceseugeneNo ratings yet
- Basis For Comparison Synchronous Transmission Asynchronous TransmissionDocument31 pagesBasis For Comparison Synchronous Transmission Asynchronous TransmissionDev SharmaNo ratings yet
- Cost-Effective Resource Allocation of Overlay Routing Relay NodesDocument8 pagesCost-Effective Resource Allocation of Overlay Routing Relay NodesJAYAPRAKASHNo ratings yet
- High-Speed and Energy-Efficient Carry Skip Adder Operating Under A Wide Range of Supply Voltage LevelsDocument8 pagesHigh-Speed and Energy-Efficient Carry Skip Adder Operating Under A Wide Range of Supply Voltage LevelsTechnos_IncNo ratings yet
- Modelling and Simulation of Load Balancing in Computer NetworkDocument7 pagesModelling and Simulation of Load Balancing in Computer NetworkAJER JOURNALNo ratings yet
- Cisco Spine LeafDocument5 pagesCisco Spine LeafMasih FavaNo ratings yet
- 10 1 1 70Document14 pages10 1 1 70Sanjeev Naik RNo ratings yet
- Energy-And Performance-Aware Mapping For Regular Noc ArchitecturesDocument12 pagesEnergy-And Performance-Aware Mapping For Regular Noc ArchitecturespnrgoudNo ratings yet
- Joint Scheduling and Resource Allocation in Uplink OFDM Systems For Broadband Wireless Access NetworksDocument9 pagesJoint Scheduling and Resource Allocation in Uplink OFDM Systems For Broadband Wireless Access NetworksAnnalakshmi Gajendran100% (1)
- Run PP07 02Document11 pagesRun PP07 02MangoNo ratings yet
- Design of A Reconfigurable Switch Architecture For Next Generation Communication NetworksDocument6 pagesDesign of A Reconfigurable Switch Architecture For Next Generation Communication Networkshema_iitbbsNo ratings yet
- A Novel Distributed Call Admission Control Solution Based On Machine Learning Approach - PRESENTATIONDocument11 pagesA Novel Distributed Call Admission Control Solution Based On Machine Learning Approach - PRESENTATIONAli Hasan KhanNo ratings yet
- How To Choose A Motion BusDocument7 pagesHow To Choose A Motion BussybaritzNo ratings yet
- The Research of Load Balancing Technology in Server Colony: - Gao Yan, Zhang Zhibin, and Du WeifengDocument9 pagesThe Research of Load Balancing Technology in Server Colony: - Gao Yan, Zhang Zhibin, and Du WeifengNguyen Ba Thanh TungNo ratings yet
- Applying Time-Division Multiplexing in Star-Based Optical NetworksDocument4 pagesApplying Time-Division Multiplexing in Star-Based Optical NetworksJuliana CantilloNo ratings yet
- Khoaluan HoangTuanHungDocument6 pagesKhoaluan HoangTuanHungHoàng Tuấn HùngNo ratings yet
- On The Interaction of Multiple Routing AlgorithmsDocument12 pagesOn The Interaction of Multiple Routing AlgorithmsLee HeaverNo ratings yet
- What Is A Network Operating SystemDocument8 pagesWhat Is A Network Operating SystemJay-r MatibagNo ratings yet
- Jecet: Journal of Electronics and Communication Engineering & Technology (JECET)Document6 pagesJecet: Journal of Electronics and Communication Engineering & Technology (JECET)IAEME PublicationNo ratings yet
- Abstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aDocument6 pagesAbstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aVidvek InfoTechNo ratings yet
- Core Selection TechniquesDocument5 pagesCore Selection TechniquesNabil Ben MazouzNo ratings yet
- 603 PaperDocument6 pages603 PaperMaarij RaheemNo ratings yet
- Very High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic DevicesDocument5 pagesVery High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic Devices8148593856No ratings yet
- Improving Delivery Ratio For Application - Layer Multicast Using IrpDocument5 pagesImproving Delivery Ratio For Application - Layer Multicast Using Irpsurendiran123No ratings yet
- Cisco Data Center Spine-And-Leaf Architecture - Design Overview White Paper - CiscoDocument32 pagesCisco Data Center Spine-And-Leaf Architecture - Design Overview White Paper - CiscoSalman AlfarisiNo ratings yet
- 7Document101 pages7Navindra JaggernauthNo ratings yet
- Question Paper: Hygiene, Health and SafetyDocument2 pagesQuestion Paper: Hygiene, Health and Safetywf4sr4rNo ratings yet
- Prevalence of Peptic Ulcer in Patients Attending Kampala International University Teaching Hospital in Ishaka Bushenyi Municipality, UgandaDocument10 pagesPrevalence of Peptic Ulcer in Patients Attending Kampala International University Teaching Hospital in Ishaka Bushenyi Municipality, UgandaKIU PUBLICATION AND EXTENSIONNo ratings yet
- Syed Hamid Kazmi - CVDocument2 pagesSyed Hamid Kazmi - CVHamid KazmiNo ratings yet
- Go Ask Alice EssayDocument6 pagesGo Ask Alice Essayafhbexrci100% (2)
- EASY DMS ConfigurationDocument6 pagesEASY DMS ConfigurationRahul KumarNo ratings yet
- Understanding Consumer and Business Buyer BehaviorDocument47 pagesUnderstanding Consumer and Business Buyer BehaviorJia LeNo ratings yet
- Donation Drive List of Donations and BlocksDocument3 pagesDonation Drive List of Donations and BlocksElijah PunzalanNo ratings yet
- Economies and Diseconomies of ScaleDocument7 pagesEconomies and Diseconomies of Scale2154 taibakhatunNo ratings yet
- BPL-DF 2617aedrDocument3 pagesBPL-DF 2617aedrBiomedical Incharge SRM TrichyNo ratings yet
- Design of Flyback Transformers and Filter Inductor by Lioyd H.dixon, Jr. Slup076Document11 pagesDesign of Flyback Transformers and Filter Inductor by Lioyd H.dixon, Jr. Slup076Burlacu AndreiNo ratings yet
- LT1256X1 - Revg - FB1300, FB1400 Series - EnglishDocument58 pagesLT1256X1 - Revg - FB1300, FB1400 Series - EnglishRahma NaharinNo ratings yet
- STM Series Solar ControllerDocument2 pagesSTM Series Solar ControllerFaris KedirNo ratings yet
- Sacmi Vol 2 Inglese - II EdizioneDocument416 pagesSacmi Vol 2 Inglese - II Edizionecuibaprau100% (21)
- Assessment 21GES1475Document4 pagesAssessment 21GES1475kavindupunsara02No ratings yet
- SPC Abc Security Agrmnt PDFDocument6 pagesSPC Abc Security Agrmnt PDFChristian Comunity100% (3)
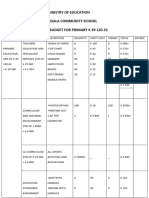
- Ministry of Education Musala SCHDocument5 pagesMinistry of Education Musala SCHlaonimosesNo ratings yet
- Home Guaranty Corp. v. Manlapaz - PunzalanDocument3 pagesHome Guaranty Corp. v. Manlapaz - PunzalanPrincess Aliyah Punzalan100% (1)
- Historical DocumentsDocument82 pagesHistorical Documentsmanavjha29No ratings yet
- Engagement Letter TrustDocument4 pagesEngagement Letter Trustxetay24207No ratings yet
- Outage Analysis of Wireless CommunicationDocument28 pagesOutage Analysis of Wireless CommunicationTarunav SahaNo ratings yet
- Department of Labor: 2nd Injury FundDocument140 pagesDepartment of Labor: 2nd Injury FundUSA_DepartmentOfLabor100% (1)
- Writing Task The Strategy of Regional Economic DevelopementDocument4 pagesWriting Task The Strategy of Regional Economic DevelopementyosiNo ratings yet
- YeetDocument8 pagesYeetBeLoopersNo ratings yet
- Chapter 3 Searching and PlanningDocument104 pagesChapter 3 Searching and PlanningTemesgenNo ratings yet
- Kicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonDocument8 pagesKicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonYudyChenNo ratings yet
- Review of Accounting Process 1Document2 pagesReview of Accounting Process 1Stacy SmithNo ratings yet