You might also like
- Statistical Inference in Financial and Insurance Mathematics with RFrom EverandStatistical Inference in Financial and Insurance Mathematics with RNo ratings yet
- Empirical IODocument33 pagesEmpirical IOChris JaccariniNo ratings yet
- Demand Analysis - SiegDocument126 pagesDemand Analysis - SiegRundong WangNo ratings yet
- Homothetic PreferencesDocument34 pagesHomothetic PreferencesvgdasaNo ratings yet
- Demand Analysis & Forecasting: Unit 2Document44 pagesDemand Analysis & Forecasting: Unit 2Khanal NilambarNo ratings yet
- Empirical Models of Firms and IndustriesDocument49 pagesEmpirical Models of Firms and Industriesrandomly1249No ratings yet
- 1-s2.0-S0022053115000824-mainDocument15 pages1-s2.0-S0022053115000824-main小田勇一No ratings yet
- Lecture Notes On Industrial Organization (I)Document118 pagesLecture Notes On Industrial Organization (I)DavidNo ratings yet
- Competitive Markets in Economics 121Document26 pagesCompetitive Markets in Economics 121Matteo GodiNo ratings yet
- BLP Demand EstimationDocument38 pagesBLP Demand EstimationMadhur BhatiaNo ratings yet
- Lecture notes on discrete-choice models of demandDocument19 pagesLecture notes on discrete-choice models of demandHikmah MulyadiNo ratings yet
- Firm Heterogeneity, Endogenous Markups, and Factor EndowmentsDocument24 pagesFirm Heterogeneity, Endogenous Markups, and Factor EndowmentsHector Perez SaizNo ratings yet
- Part 2, Demand AnalysisDocument66 pagesPart 2, Demand AnalysisBereket KidaneNo ratings yet
- Dixit Stiglitz Model OverviewDocument33 pagesDixit Stiglitz Model OverviewNiall DevittNo ratings yet
- Economics ReviewerDocument14 pagesEconomics ReviewerJeeNo ratings yet
- Dixit Stiglitz Explained PDFDocument15 pagesDixit Stiglitz Explained PDFRuhi SonalNo ratings yet
- Dixit Stiglitz BasicsDocument6 pagesDixit Stiglitz BasicssomeoneinnycNo ratings yet
- General Equilibrium Theory: Partial vs General ModelsDocument14 pagesGeneral Equilibrium Theory: Partial vs General ModelsChariza Jane Margallo BaqueroNo ratings yet
- A Simple Model of Demand and SupplyDocument10 pagesA Simple Model of Demand and SupplyJames OwenNo ratings yet
- Lecture 2 Demand Theory, Estimation and ForecastingDocument84 pagesLecture 2 Demand Theory, Estimation and Forecastingrecious44joshkNo ratings yet
- Hedonic pricing methods for cost benefit analysisDocument6 pagesHedonic pricing methods for cost benefit analysisEllaNo ratings yet
- ECO206 Handout Topic 1 Budget ConstraintsDocument16 pagesECO206 Handout Topic 1 Budget Constraintszeyuan liNo ratings yet
- Business (Managerial) EconomicsDocument264 pagesBusiness (Managerial) EconomicsTanya VermaNo ratings yet
- Elmar Wolfstetter. Topics in Microeconomics Industrial Organization, Auctions, and Incentives. 21-150Document130 pagesElmar Wolfstetter. Topics in Microeconomics Industrial Organization, Auctions, and Incentives. 21-150Mafe Espinosa0% (1)
- M E Final 3 de ELaDocument27 pagesM E Final 3 de ELaNikhil LathiyaNo ratings yet
- 10-Demand Models PDFDocument9 pages10-Demand Models PDFWilfrido CalleNo ratings yet
- Consumer Equilibrium and Demand AnalysisDocument8 pagesConsumer Equilibrium and Demand AnalysisabdanNo ratings yet
- Lecture 5Document32 pagesLecture 5ackimNo ratings yet
- Exercises Part2Document9 pagesExercises Part2christina0107No ratings yet
- Demand FunctionDocument50 pagesDemand FunctiongipaworldNo ratings yet
- Funciones de Precios Hedonicos Lars NesheimDocument28 pagesFunciones de Precios Hedonicos Lars NesheimmhonorioaNo ratings yet
- Micro Problem SetDocument5 pagesMicro Problem SetAkshay JainNo ratings yet
- Decomposing Market Channel Profits: The Case of Ready-to-Eat Cereals in BostonDocument28 pagesDecomposing Market Channel Profits: The Case of Ready-to-Eat Cereals in BostonplinjenNo ratings yet
- Econ160 Weeks1 2Document56 pagesEcon160 Weeks1 2milad mozafariNo ratings yet
- Lie Theory Applications To Problems in Mathematical Finance and EconomicsDocument16 pagesLie Theory Applications To Problems in Mathematical Finance and EconomicssggtioNo ratings yet
- Utility Maximization and ChoiceDocument40 pagesUtility Maximization and ChoiceBella Novitasari100% (1)
- B0ae PDFDocument24 pagesB0ae PDFMainak GhosalNo ratings yet
- Mon CompetDocument9 pagesMon CompetsettiNo ratings yet
- Exercises 3Document3 pagesExercises 3dabuliemeiyoudianNo ratings yet
- Review of Econ 203Document73 pagesReview of Econ 203api-235832666No ratings yet
- Master EPP, International Trade ModelsDocument9 pagesMaster EPP, International Trade ModelsMasha KovalNo ratings yet
- Slide-3.-Demand-related-and-Consumer-Behavior (1) - Copy - CopyDocument44 pagesSlide-3.-Demand-related-and-Consumer-Behavior (1) - Copy - Copyminhln16.sicNo ratings yet
- Module 3 Lecture 11Document7 pagesModule 3 Lecture 11Swapan Kumar SahaNo ratings yet
- Microeconomic Theory - Review For Final ExamDocument6 pagesMicroeconomic Theory - Review For Final ExamKhanh LuuNo ratings yet
- MEC 604 LecturesDocument40 pagesMEC 604 LecturesRoshan KCNo ratings yet
- Elasticity of Demand and Supply - SynthesisDocument6 pagesElasticity of Demand and Supply - SynthesisPrincess GonzalesNo ratings yet
- Exercises ElasticityDocument4 pagesExercises ElasticityAA BB MMNo ratings yet
- Econ 301 MT 1 NotesDocument24 pagesEcon 301 MT 1 NotesNicolle YhapNo ratings yet
- Journal IDocument17 pagesJournal Iqzm74lNo ratings yet
- Macro Questionss12Document8 pagesMacro Questionss12paripi99No ratings yet
- ME Chapter3Document14 pagesME Chapter3HarlinniNo ratings yet
- The Nonparametric Approach To Applied Welfare Analysis: Donald J. Brown Caterina Calsamiglia February 2006Document8 pagesThe Nonparametric Approach To Applied Welfare Analysis: Donald J. Brown Caterina Calsamiglia February 2006elrodrigazoNo ratings yet
- Cobb Douglas FunctionDocument49 pagesCobb Douglas FunctionVikash KumarNo ratings yet
- Mathemathical economics ch -1Document31 pagesMathemathical economics ch -1kasahun tilahunNo ratings yet
- Model ExplainedDocument6 pagesModel Explainedchiki chikitaNo ratings yet
- Demand & Utility: David LevinsonDocument62 pagesDemand & Utility: David LevinsonFrancisco GranadosNo ratings yet
- Written Report Bor Grp6Document17 pagesWritten Report Bor Grp6arrisAlyssaNo ratings yet
- Basic Plumbing PrinciplesDocument6 pagesBasic Plumbing PrinciplesRolii VargasNo ratings yet
- Unit 3 Market and Demand Analysis: ObjectivesDocument11 pagesUnit 3 Market and Demand Analysis: ObjectivesAhmed SalihNo ratings yet
- Ecotourism ManualDocument254 pagesEcotourism ManualJeavelyn CabilinoNo ratings yet
- Architectural Design 9 (Ar 511D4) Thesis Grading Sheet Architectural Programming DefenseDocument2 pagesArchitectural Design 9 (Ar 511D4) Thesis Grading Sheet Architectural Programming DefenseJeavelyn CabilinoNo ratings yet
- 2010 Census of Population and Housing in Batangas ProvinceDocument120 pages2010 Census of Population and Housing in Batangas ProvinceJeavelyn Cabilino0% (2)
- Labor Supply/Demand Analysis Approaches and ConcernsDocument14 pagesLabor Supply/Demand Analysis Approaches and ConcernsJeavelyn CabilinoNo ratings yet
- Basic Plumbing PrinciplesDocument6 pagesBasic Plumbing PrinciplesRolii VargasNo ratings yet
- Architectural Design 9 (Ar 511D4) Thesis Grading Sheet Architectural Programming DefenseDocument2 pagesArchitectural Design 9 (Ar 511D4) Thesis Grading Sheet Architectural Programming DefenseJeavelyn CabilinoNo ratings yet
- PICC Delegation Building Ground Floor Layout 1:600 Scale PlanDocument1 pagePICC Delegation Building Ground Floor Layout 1:600 Scale PlanJeavelyn CabilinoNo ratings yet
- JHHJHDocument17 pagesJHHJHJeavelyn CabilinoNo ratings yet
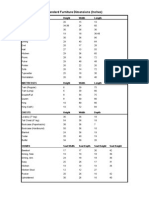
- Standard Furniture DimensionsDocument1 pageStandard Furniture DimensionsIana LeynoNo ratings yet
- Strategic Planning HLURB Vol 4Document123 pagesStrategic Planning HLURB Vol 4Abbey RoadNo ratings yet
- 1 STDocument10 pages1 STJeavelyn CabilinoNo ratings yet
- Just GotDocument40 pagesJust GotJeavelyn CabilinoNo ratings yet
- CMDocument4 pagesCMJeavelyn CabilinoNo ratings yet
- 1 Why Demand Analysis/estimation?: P MC PDocument33 pages1 Why Demand Analysis/estimation?: P MC PJeavelyn CabilinoNo ratings yet
- Draft Ecotourism Guidelines 2 JuneDocument15 pagesDraft Ecotourism Guidelines 2 JuneJeavelyn CabilinoNo ratings yet
- Strategic Planning HLURB Vol 4Document123 pagesStrategic Planning HLURB Vol 4Abbey RoadNo ratings yet
- CLUPDocument146 pagesCLUPJeavelyn CabilinoNo ratings yet
- Ecotourism ManualDocument254 pagesEcotourism ManualJeavelyn CabilinoNo ratings yet
- Unit 3 Market and Demand Analysis: ObjectivesDocument11 pagesUnit 3 Market and Demand Analysis: ObjectivesAhmed SalihNo ratings yet
- Adobe Photoshop Shortcut KeysDocument25 pagesAdobe Photoshop Shortcut KeysJeavelyn CabilinoNo ratings yet
- Angat Water Sports ComplexDocument3 pagesAngat Water Sports ComplexJeavelyn CabilinoNo ratings yet
- Arrival Income Jan-Dec 2006consol With MedianDocument12 pagesArrival Income Jan-Dec 2006consol With MedianJeavelyn CabilinoNo ratings yet
- Arrival Income Jan-Dec 2006consol With MedianDocument12 pagesArrival Income Jan-Dec 2006consol With MedianJeavelyn CabilinoNo ratings yet
- Trade Fair ObjectivesDocument3 pagesTrade Fair ObjectivesJeavelyn CabilinoNo ratings yet
- MiceDocument4 pagesMiceJeavelyn CabilinoNo ratings yet
- Assimilaion Reviewer For ArchitectureDocument35 pagesAssimilaion Reviewer For ArchitectureJeavelyn Cabilino100% (1)
- Adobe Photoshop Shortcut KeysDocument25 pagesAdobe Photoshop Shortcut KeysJeavelyn CabilinoNo ratings yet
- Can't Hurt Me by David Goggins - Book Summary: Master Your Mind and Defy the OddsFrom EverandCan't Hurt Me by David Goggins - Book Summary: Master Your Mind and Defy the OddsRating: 4.5 out of 5 stars4.5/5 (381)
- Summary of Bad Therapy by Abigail Shrier: Why the Kids Aren't Growing UpFrom EverandSummary of Bad Therapy by Abigail Shrier: Why the Kids Aren't Growing UpRating: 5 out of 5 stars5/5 (1)
- Summary: Atomic Habits by James Clear: An Easy & Proven Way to Build Good Habits & Break Bad OnesFrom EverandSummary: Atomic Habits by James Clear: An Easy & Proven Way to Build Good Habits & Break Bad OnesRating: 5 out of 5 stars5/5 (1631)
- Summary of Atomic Habits by James ClearFrom EverandSummary of Atomic Habits by James ClearRating: 5 out of 5 stars5/5 (168)
- Summary of Slow Productivity by Cal Newport: The Lost Art of Accomplishment Without BurnoutFrom EverandSummary of Slow Productivity by Cal Newport: The Lost Art of Accomplishment Without BurnoutRating: 1 out of 5 stars1/5 (1)
- Summary of The Anxious Generation by Jonathan Haidt: How the Great Rewiring of Childhood Is Causing an Epidemic of Mental IllnessFrom EverandSummary of The Anxious Generation by Jonathan Haidt: How the Great Rewiring of Childhood Is Causing an Epidemic of Mental IllnessNo ratings yet
- The One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsFrom EverandThe One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsRating: 4.5 out of 5 stars4.5/5 (708)
- The War of Art by Steven Pressfield - Book Summary: Break Through The Blocks And Win Your Inner Creative BattlesFrom EverandThe War of Art by Steven Pressfield - Book Summary: Break Through The Blocks And Win Your Inner Creative BattlesRating: 4.5 out of 5 stars4.5/5 (273)
- The Body Keeps the Score by Bessel Van der Kolk, M.D. - Book Summary: Brain, Mind, and Body in the Healing of TraumaFrom EverandThe Body Keeps the Score by Bessel Van der Kolk, M.D. - Book Summary: Brain, Mind, and Body in the Healing of TraumaRating: 4.5 out of 5 stars4.5/5 (266)
- How To Win Friends and Influence People by Dale Carnegie - Book SummaryFrom EverandHow To Win Friends and Influence People by Dale Carnegie - Book SummaryRating: 5 out of 5 stars5/5 (555)
- The Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessFrom EverandThe Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessRating: 5 out of 5 stars5/5 (456)
- Summary of 12 Rules for Life: An Antidote to ChaosFrom EverandSummary of 12 Rules for Life: An Antidote to ChaosRating: 4.5 out of 5 stars4.5/5 (294)
- Mindset by Carol S. Dweck - Book Summary: The New Psychology of SuccessFrom EverandMindset by Carol S. Dweck - Book Summary: The New Psychology of SuccessRating: 4.5 out of 5 stars4.5/5 (327)
- Essentialism by Greg McKeown - Book Summary: The Disciplined Pursuit of LessFrom EverandEssentialism by Greg McKeown - Book Summary: The Disciplined Pursuit of LessRating: 4.5 out of 5 stars4.5/5 (187)
- Summary of Supercommunicators by Charles Duhigg: How to Unlock the Secret Language of ConnectionFrom EverandSummary of Supercommunicators by Charles Duhigg: How to Unlock the Secret Language of ConnectionNo ratings yet
- Make It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningFrom EverandMake It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningRating: 4.5 out of 5 stars4.5/5 (55)
- The Whole-Brain Child by Daniel J. Siegel, M.D., and Tina Payne Bryson, PhD. - Book Summary: 12 Revolutionary Strategies to Nurture Your Child’s Developing MindFrom EverandThe Whole-Brain Child by Daniel J. Siegel, M.D., and Tina Payne Bryson, PhD. - Book Summary: 12 Revolutionary Strategies to Nurture Your Child’s Developing MindRating: 4.5 out of 5 stars4.5/5 (57)
- Book Summary of The Subtle Art of Not Giving a F*ck by Mark MansonFrom EverandBook Summary of The Subtle Art of Not Giving a F*ck by Mark MansonRating: 4.5 out of 5 stars4.5/5 (577)
- Designing Your Life by Bill Burnett, Dave Evans - Book Summary: How to Build a Well-Lived, Joyful LifeFrom EverandDesigning Your Life by Bill Burnett, Dave Evans - Book Summary: How to Build a Well-Lived, Joyful LifeRating: 4.5 out of 5 stars4.5/5 (61)
- Summary of The Galveston Diet by Mary Claire Haver MD: The Doctor-Developed, Patient-Proven Plan to Burn Fat and Tame Your Hormonal SymptomsFrom EverandSummary of The Galveston Diet by Mary Claire Haver MD: The Doctor-Developed, Patient-Proven Plan to Burn Fat and Tame Your Hormonal SymptomsNo ratings yet
- SUMMARY: So Good They Can't Ignore You (UNOFFICIAL SUMMARY: Lesson from Cal Newport)From EverandSUMMARY: So Good They Can't Ignore You (UNOFFICIAL SUMMARY: Lesson from Cal Newport)Rating: 4.5 out of 5 stars4.5/5 (14)
- The 5 Second Rule by Mel Robbins - Book Summary: Transform Your Life, Work, and Confidence with Everyday CourageFrom EverandThe 5 Second Rule by Mel Robbins - Book Summary: Transform Your Life, Work, and Confidence with Everyday CourageRating: 4.5 out of 5 stars4.5/5 (328)
- Summary, Analysis, and Review of Cal Newport's Deep WorkFrom EverandSummary, Analysis, and Review of Cal Newport's Deep WorkRating: 3.5 out of 5 stars3.5/5 (18)
- Steal Like an Artist by Austin Kleon - Book Summary: 10 Things Nobody Told You About Being CreativeFrom EverandSteal Like an Artist by Austin Kleon - Book Summary: 10 Things Nobody Told You About Being CreativeRating: 4.5 out of 5 stars4.5/5 (128)
- We Were the Lucky Ones: by Georgia Hunter | Conversation StartersFrom EverandWe Were the Lucky Ones: by Georgia Hunter | Conversation StartersNo ratings yet
- Summary of The Hunger Habit by Judson Brewer: Why We Eat When We're Not Hungry and How to StopFrom EverandSummary of The Hunger Habit by Judson Brewer: Why We Eat When We're Not Hungry and How to StopNo ratings yet
- Summary, Analysis, and Review of Daniel Kahneman's Thinking, Fast and SlowFrom EverandSummary, Analysis, and Review of Daniel Kahneman's Thinking, Fast and SlowRating: 3.5 out of 5 stars3.5/5 (2)
- One Hundred Years of Solitude: A Novel by Gabriel Garcia Márquez | Conversation StartersFrom EverandOne Hundred Years of Solitude: A Novel by Gabriel Garcia Márquez | Conversation StartersRating: 3.5 out of 5 stars3.5/5 (10)