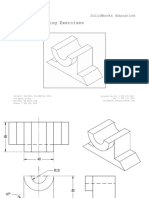
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Sjzl20081552-ZXR10 T240G&T160G&T64G&T40G (V2 (1) .8.01C) 10 Gigabit Routing Switch Hardware ManualDocument89 pagesSjzl20081552-ZXR10 T240G&T160G&T64G&T40G (V2 (1) .8.01C) 10 Gigabit Routing Switch Hardware ManualAd B Abu100% (1)
- Extreme S Series DSDocument18 pagesExtreme S Series DSManohar KothandaramanNo ratings yet
- Samsung UE40C8000 ManualDocument66 pagesSamsung UE40C8000 ManualChisvasiSebastianNo ratings yet
- HP Pavilion G6 Fan Cleaning: Guides Answers StoreDocument14 pagesHP Pavilion G6 Fan Cleaning: Guides Answers StoreBane TomanovicNo ratings yet
- Q&A - What Is SAE J1939?: (Source For The Following Answers: SAE HS-1939)Document3 pagesQ&A - What Is SAE J1939?: (Source For The Following Answers: SAE HS-1939)Ponraj Govindarajan100% (1)
- Unit 5:structures in C' Structure-Defination: Defination1:A Group of One or More Variables of Different Data Types OrganizedDocument18 pagesUnit 5:structures in C' Structure-Defination: Defination1:A Group of One or More Variables of Different Data Types OrganizedShanmuka SreenivasNo ratings yet
- Adnan's Computer For PharmacistDocument136 pagesAdnan's Computer For PharmacistDr-Adnan Sarwar ChaudharyNo ratings yet
- Draft v0.1: Policy 191 - Incident Response Tools & Resources ChecklistDocument8 pagesDraft v0.1: Policy 191 - Incident Response Tools & Resources ChecklistMarcus AdomeyNo ratings yet
- FILE 20210113 151059 Vdocuments - Site 01-Ua5000-Technical-Manual PDFDocument107 pagesFILE 20210113 151059 Vdocuments - Site 01-Ua5000-Technical-Manual PDFThanh LeNo ratings yet
- Cad DrawingsDocument51 pagesCad DrawingspramodNo ratings yet
- Enhanced Interior Gateway Routing Protocol (Eigrp)Document60 pagesEnhanced Interior Gateway Routing Protocol (Eigrp)Anasham TegegnNo ratings yet
- InformaticaDocument15 pagesInformaticakumar554No ratings yet
- AmgtrmDocument272 pagesAmgtrmBalamurali VivekanandanNo ratings yet
- 41 Mobile100 TechnicalDocument107 pages41 Mobile100 TechnicalCauVong JustinNo ratings yet
- Important Points To Note PE1-PE2Document3 pagesImportant Points To Note PE1-PE2Debaki Nandan SamalNo ratings yet
- itrioWF UserManual PDFDocument22 pagesitrioWF UserManual PDFCehanNo ratings yet
- Terberg Network Structure-3661600586101635Document14 pagesTerberg Network Structure-3661600586101635yousufNo ratings yet
- UM NuEclipse ENDocument40 pagesUM NuEclipse ENjaikishanNo ratings yet
- Structure: About This ChapterDocument8 pagesStructure: About This ChapterBacha KhanNo ratings yet
- Tools For Teaching Computer Networking and Hardware ConceptsDocument405 pagesTools For Teaching Computer Networking and Hardware ConceptsMarko DunjicNo ratings yet
- Inquest: VFSTRDocument19 pagesInquest: VFSTRAvinash BommiNo ratings yet
- Telecom Interview Questions Answers Guide PDFDocument10 pagesTelecom Interview Questions Answers Guide PDFtom2626No ratings yet
- Intel Xeon Processor C5500 and C3500 Series Non-Transparent Bridge Programming GuideDocument30 pagesIntel Xeon Processor C5500 and C3500 Series Non-Transparent Bridge Programming Guideteo2005No ratings yet
- Descarga de ScribdDocument4 pagesDescarga de ScribdYoel MartínezNo ratings yet
- Lenze Drive With S7 ProfibusDocument17 pagesLenze Drive With S7 ProfibusDavid BestNo ratings yet
- Mouse and Keyboard PresentationDocument22 pagesMouse and Keyboard PresentationNagesh PatilNo ratings yet
- Steam Community Guide How To Find & Play Modules On Neverwinter VaultDocument5 pagesSteam Community Guide How To Find & Play Modules On Neverwinter VaultPaulNo ratings yet
- Nvidia Smi.1Document26 pagesNvidia Smi.1Amanda GibsonNo ratings yet
- 1.2a Timing - Sense - Timing Arc inDocument5 pages1.2a Timing - Sense - Timing Arc inSudheer GangisettyNo ratings yet
- CamaraDocument4 pagesCamaraLeonardoNo ratings yet