You might also like
- How to Web Scrape with Python in 4 MinutesDocument12 pagesHow to Web Scrape with Python in 4 Minutesvicearellano100% (1)
- Google Hacking Mini-Guide: How Search Engines Can Leak Sensitive DataDocument8 pagesGoogle Hacking Mini-Guide: How Search Engines Can Leak Sensitive DataRaden BimaNo ratings yet
- 1.1 Web ScrapingDocument34 pages1.1 Web ScrapinginesNo ratings yet
- Web ScrappingDocument20 pagesWeb ScrappingMuhammad Abdullah100% (1)
- Spring Rest APIDocument45 pagesSpring Rest APIMohamed HaydarNo ratings yet
- The Content Editor: Current Version: 9.3Document24 pagesThe Content Editor: Current Version: 9.3Owais Maso0d100% (1)
- Four Programming Languages Creating a Complete Website Scraper ApplicationFrom EverandFour Programming Languages Creating a Complete Website Scraper ApplicationNo ratings yet
- Data Sructures and AlgorithmsDocument112 pagesData Sructures and AlgorithmsSaad AliNo ratings yet
- RESTful Day 1 PDFDocument47 pagesRESTful Day 1 PDFenriqueNo ratings yet
- Day One Apply Junos Ops Automation - Juniper Networks PDFDocument107 pagesDay One Apply Junos Ops Automation - Juniper Networks PDF鄭俊德No ratings yet
- Getting Started With FlaskDocument23 pagesGetting Started With FlaskMohammad MazheruddinNo ratings yet
- DSA by Shradha Didi & Aman BhaiyaDocument9 pagesDSA by Shradha Didi & Aman BhaiyaAkhilesh ChauhanNo ratings yet
- ASP.NET For Beginners: The Simple Guide to Learning ASP.NET Web Programming Fast!From EverandASP.NET For Beginners: The Simple Guide to Learning ASP.NET Web Programming Fast!No ratings yet
- Learn Kubernetes in Under 3 Hours: A Detailed Guide To Orchestrating Containers PDFDocument61 pagesLearn Kubernetes in Under 3 Hours: A Detailed Guide To Orchestrating Containers PDFnaitik kapadiaNo ratings yet
- A Simple Python Web Crawler...Document5 pagesA Simple Python Web Crawler...tnasrevid100% (1)
- Creating RESTful API in JavaDocument24 pagesCreating RESTful API in JavaMuhammad FrazNo ratings yet
- Spring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudFrom EverandSpring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudNo ratings yet
- Web ScrappingDocument57 pagesWeb ScrappingArindam DuttaNo ratings yet
- PY Mod5@AzDOCUMENTS - inDocument26 pagesPY Mod5@AzDOCUMENTS - inBeing FantasticNo ratings yet
- Background Threads in ASPDocument11 pagesBackground Threads in ASPghar_dashNo ratings yet
- What Is Automation Testing?Document36 pagesWhat Is Automation Testing?Dante Mauricio FontanaNo ratings yet
- Title Search Engine: Submitted in Partial Fulfillment For The Award of DegreeDocument40 pagesTitle Search Engine: Submitted in Partial Fulfillment For The Award of DegreevineetkanwatNo ratings yet
- Angular HTTP CommunicationDocument43 pagesAngular HTTP CommunicationshyamVENKATNo ratings yet
- Web Scraping VisualizationsDocument53 pagesWeb Scraping VisualizationsOliver TaukNo ratings yet
- Create NoYoGenGulpSPFxWebPartsDocument9 pagesCreate NoYoGenGulpSPFxWebPartspriyakantbhaiNo ratings yet
- Semantic Web (CS1145) : Department Elective (Final Year) Department of Computer Science & EngineeringDocument36 pagesSemantic Web (CS1145) : Department Elective (Final Year) Department of Computer Science & Engineeringqwerty uNo ratings yet
- Fatwire Questions AnswerDocument10 pagesFatwire Questions Answerrudra_mitra2002No ratings yet
- Writing Restful Web Services Using Vs2008, WCF, C#, and Iis by Dave Peru, January 2011 (Document30 pagesWriting Restful Web Services Using Vs2008, WCF, C#, and Iis by Dave Peru, January 2011 (Pechel HernándezNo ratings yet
- No Iunea de View/Interfa Ă Ț ȚDocument10 pagesNo Iunea de View/Interfa Ă Ț ȚCatherine NemerencoNo ratings yet
- Depika WcsDocument9 pagesDepika WcsDepikaNo ratings yet
- Teleport User ManualDocument28 pagesTeleport User ManualGökhan BulutNo ratings yet
- Zentity Quick Guide - Version 1Document29 pagesZentity Quick Guide - Version 1sadayd2131No ratings yet
- Web TechnologiesDocument18 pagesWeb TechnologiesSamya PalNo ratings yet
- WWW Mechanize TutorialDocument7 pagesWWW Mechanize Tutorialsr71919No ratings yet
- Homework-4 OF Web Programming: Submitted ToDocument9 pagesHomework-4 OF Web Programming: Submitted Tob2cmNo ratings yet
- Mooc Semiar File Chirag SaxenaDocument159 pagesMooc Semiar File Chirag Saxenachirag19saxena2001No ratings yet
- VP Extra NotesDocument125 pagesVP Extra NotesRaven KnightNo ratings yet
- Security Testing With JMeterDocument11 pagesSecurity Testing With JMeterNguyễn ViệtNo ratings yet
- PresentationDocument156 pagesPresentationRaj SNo ratings yet
- Servidor - 2Document36 pagesServidor - 2daniel.sanchezruiz.cursoNo ratings yet
- UftDocument4 pagesUftsatyavarmajNo ratings yet
- MS Project ReportDocument26 pagesMS Project ReportvirubhauNo ratings yet
- Elasticsearch Quick Start: An Introduction To Elasticsearch in Tutorial FormDocument21 pagesElasticsearch Quick Start: An Introduction To Elasticsearch in Tutorial FormVinod KapoorNo ratings yet
- What Is Properties in SoapUIDocument19 pagesWhat Is Properties in SoapUISai KrishnaNo ratings yet
- Entity Framework Interview Questions With AnswersDocument16 pagesEntity Framework Interview Questions With AnswersShivprasad Koirala100% (5)
- 19-5E8 Tushara PriyaDocument23 pages19-5E8 Tushara Priya19-5E8 Tushara PriyaNo ratings yet
- Website Performance Analysis PresentationDocument63 pagesWebsite Performance Analysis Presentationhpm76No ratings yet
- 2nd ReviewDocument33 pages2nd ReviewManasvi GautamNo ratings yet
- Christos ChenDocument42 pagesChristos ChenManisha TanwarNo ratings yet
- ASPDocument53 pagesASPsony100% (2)
- Wdm-Unit 1Document158 pagesWdm-Unit 1Maheswari. SNo ratings yet
- Add Search Features To Your Application - Try ElasticDocument15 pagesAdd Search Features To Your Application - Try ElasticrkpunjalNo ratings yet
- PHP DocsDocument40 pagesPHP DocsReshma LmNo ratings yet
- HTMLDocument7 pagesHTMLRagula MadhuriNo ratings yet
- Play Framework Essentials Sample ChapterDocument29 pagesPlay Framework Essentials Sample ChapterPackt PublishingNo ratings yet
- Assignment Web CrawlerDocument5 pagesAssignment Web CrawlerAmmarsyedNo ratings yet
- Web Dev QuestionsDocument27 pagesWeb Dev Questionsdorian451No ratings yet
- Javascript Interview Questions and AnswersDocument7 pagesJavascript Interview Questions and AnswersbikshapatiNo ratings yet
- RMK Engineering College Internet Programming Lab ManualDocument52 pagesRMK Engineering College Internet Programming Lab Manualanuj1166No ratings yet
- Lab Introduce WebDocument23 pagesLab Introduce Webshruthig29111988No ratings yet
- HTTP Handlers and HTTP ModulesDocument22 pagesHTTP Handlers and HTTP Modulesnitin_singh_24No ratings yet
- Practice Problem Set 3 EEM16Document5 pagesPractice Problem Set 3 EEM16Ben QuachtranNo ratings yet
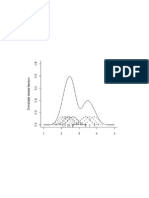
- KDE Diagram Demonstrating How Gaussian Kernels Are ResolvedDocument1 pageKDE Diagram Demonstrating How Gaussian Kernels Are ResolvedBen QuachtranNo ratings yet
- 5/3/1 Template FormDocument1 page5/3/1 Template FormBen QuachtranNo ratings yet
- EE113 Midterm 2012 For Electrical EngineeringDocument1 pageEE113 Midterm 2012 For Electrical EngineeringBen QuachtranNo ratings yet
- Modified Schedule CS33 AssemblyDocument1 pageModified Schedule CS33 AssemblyBen QuachtranNo ratings yet
- Sample Circuit ProblemsDocument4 pagesSample Circuit ProblemsBen QuachtranNo ratings yet
- Bomblab HandoutDocument4 pagesBomblab HandoutBen QuachtranNo ratings yet
- Sample Questions in Electrical EngineeringDocument2 pagesSample Questions in Electrical EngineeringBen QuachtranNo ratings yet
- Sample Circuit ProblemsDocument4 pagesSample Circuit ProblemsBen QuachtranNo ratings yet
- Formula Sheet STAT First MidtermDocument1 pageFormula Sheet STAT First MidtermBen QuachtranNo ratings yet
- Sample FInal Circuit AnalysisDocument6 pagesSample FInal Circuit AnalysisBen QuachtranNo ratings yet
- EE101A - Overview and Grading PolicyDocument2 pagesEE101A - Overview and Grading PolicyBen QuachtranNo ratings yet
- Feedback Control ProjectDocument2 pagesFeedback Control ProjectBen QuachtranNo ratings yet
- Electromagnetics Plane Waves ReviewDocument9 pagesElectromagnetics Plane Waves ReviewBen QuachtranNo ratings yet
- EE101A Electromagnetics Homework SolutionsDocument2 pagesEE101A Electromagnetics Homework SolutionsBen QuachtranNo ratings yet
- Practice Problems in Feedback ControlDocument6 pagesPractice Problems in Feedback ControlBen QuachtranNo ratings yet
- Systems of Equations and Planes ProblemsDocument1 pageSystems of Equations and Planes ProblemsBen QuachtranNo ratings yet
- Homework Problems For PhysicsDocument1 pageHomework Problems For PhysicsBen QuachtranNo ratings yet
- Problems On ElectrostaticsDocument3 pagesProblems On ElectrostaticsBen QuachtranNo ratings yet
- Notes On Amperes LawDocument10 pagesNotes On Amperes LawBen QuachtranNo ratings yet
- C String NotesDocument3 pagesC String NotesBen QuachtranNo ratings yet
- Multivariable Calculus Vector ProblemsDocument1 pageMultivariable Calculus Vector ProblemsBen QuachtranNo ratings yet
- Physics Harmonic Motion and Waves PracticeDocument5 pagesPhysics Harmonic Motion and Waves PracticeBen QuachtranNo ratings yet
- Sample Final For Complex AnalysisDocument5 pagesSample Final For Complex AnalysisBen QuachtranNo ratings yet
- ABAP ALV Tree ExemploDocument13 pagesABAP ALV Tree ExemploLeonardo NobreNo ratings yet
- Othello Game Player: D C S J ' CDocument26 pagesOthello Game Player: D C S J ' CHansenSutantoNo ratings yet
- Dsad L10Document53 pagesDsad L10Babuji BaskaranNo ratings yet
- Mongodb Session 2Document47 pagesMongodb Session 2star100% (1)
- A. 2451 B. 4950 C. 4851 D. 9900Document48 pagesA. 2451 B. 4950 C. 4851 D. 9900Abhijit routNo ratings yet
- Oracle ADF Insider - Learn Oracle ADF Online PDFDocument5 pagesOracle ADF Insider - Learn Oracle ADF Online PDFsreenivasulureddy.chNo ratings yet
- Data StuctureDocument219 pagesData Stuctureapi-3782519100% (5)
- Data Structures and Algorithms - Slides UpdatedDocument182 pagesData Structures and Algorithms - Slides UpdatedMehak NazNo ratings yet
- Branch N BoundDocument3 pagesBranch N BoundSingh VishalNo ratings yet
- Types of Classification AlgorithmDocument27 pagesTypes of Classification AlgorithmVaibhav KoshtiNo ratings yet
- Skyline Daa 1Document8 pagesSkyline Daa 1Boul chandra GaraiNo ratings yet
- 4.1) FP Growth AlgorithmDocument26 pages4.1) FP Growth AlgorithmSanjana SairamaNo ratings yet
- Clo JureDocument1,742 pagesClo JureHola MundoNo ratings yet
- David Liu NotesDocument79 pagesDavid Liu NotesEdward WangNo ratings yet
- DSA by Shradha Didi & Aman Bhaiya - DSA in 2.5 MonthsDocument5 pagesDSA by Shradha Didi & Aman Bhaiya - DSA in 2.5 Monthsashishrajkumar82No ratings yet
- Technical Aspect of Hierarchy in BWDocument16 pagesTechnical Aspect of Hierarchy in BWOla BakareNo ratings yet
- Data Structure Questions and AnswersDocument29 pagesData Structure Questions and AnswersHabtamu Hailemariam AsfawNo ratings yet
- Data Compression Techniques for Text FilesDocument12 pagesData Compression Techniques for Text FilesperhackerNo ratings yet
- MGNM575 Ca1Document7 pagesMGNM575 Ca1Atul KumarNo ratings yet
- (Lab Workbook) : 17Cs3554 - Competitive Coding LabDocument117 pages(Lab Workbook) : 17Cs3554 - Competitive Coding Lab198W1A05C5-SEC-B VUMMANENI MYTHILINo ratings yet
- 16 Creating RESTful Web Services With Application ModulesDocument49 pages16 Creating RESTful Web Services With Application ModulesJai KanthNo ratings yet
- Unit 5 SearchingSortingHashing PDFDocument53 pagesUnit 5 SearchingSortingHashing PDFAnonymous ab2R0jK0aNo ratings yet
- Secure Data Retrieval For Decentralized Disruption-Tolerant Military NetworksDocument13 pagesSecure Data Retrieval For Decentralized Disruption-Tolerant Military NetworksKiran ShenoyNo ratings yet
- Data Structure and Algorithm MCQ: A) B) C) D)Document12 pagesData Structure and Algorithm MCQ: A) B) C) D)Ashutosh ChoubeyNo ratings yet
- CS1201 Data StructuresDocument4 pagesCS1201 Data StructuressureshNo ratings yet
- Distance BCA Syllabus Karnataka State Open University Bachelor of Computer ApplicationsDocument29 pagesDistance BCA Syllabus Karnataka State Open University Bachelor of Computer ApplicationsSunil JhaNo ratings yet
- 3130702Document3 pages3130702Akshat SodhaNo ratings yet