You might also like
- Voice Lessons Full Text PDFDocument156 pagesVoice Lessons Full Text PDFRobertMaldini0% (1)
- Telugu Common Phrases Wiki GuideDocument3 pagesTelugu Common Phrases Wiki GuideAbhyudayaPrakashNo ratings yet
- English 10 Elements of Creative NonfictionDocument30 pagesEnglish 10 Elements of Creative NonfictionClifford Tungpalan Borromeo100% (1)
- Learn KannadaDocument4 pagesLearn KannadaShubham SadhNo ratings yet
- English TeluguDocument2 pagesEnglish TeluguShrikant HedaNo ratings yet
- ESSENTIAL ENGLISH LESSONSDocument29 pagesESSENTIAL ENGLISH LESSONSface2winNo ratings yet
- MalyalamDocument34 pagesMalyalamJay DoshiNo ratings yet
- Vendor: Oracle Exam Name: Oracle Benefits Cloud 2021 Implementation Essentials Exam Exam Code: 1Z0-1053-21 Product Questions: 60Document23 pagesVendor: Oracle Exam Name: Oracle Benefits Cloud 2021 Implementation Essentials Exam Exam Code: 1Z0-1053-21 Product Questions: 60Sudhakar GanjikuntaNo ratings yet
- BT 206 LB Manual Lls 2021-22Document21 pagesBT 206 LB Manual Lls 2021-22Krishna MahajanNo ratings yet
- The Book Thief - English PresentationDocument7 pagesThe Book Thief - English Presentationcasco123100% (1)
- Ganapathy - Murugan PDFDocument23 pagesGanapathy - Murugan PDFaravindsastha6385No ratings yet
- Ozymandias: Ozymandias' by Percy Bysshe ShelleyDocument13 pagesOzymandias: Ozymandias' by Percy Bysshe Shelleyscripduser1973100% (1)
- ParallelismDocument3 pagesParallelismSumit Kumar KunduNo ratings yet
- Indian Languages - Working KnowledgeDocument22 pagesIndian Languages - Working KnowledgeBhupesh MulikNo ratings yet
- Sanskrit-Verbless Sentences in SanskritDocument30 pagesSanskrit-Verbless Sentences in SanskritSundar Balakrishnan100% (1)
- HINDI CONVERSATION Program BrochureDocument7 pagesHINDI CONVERSATION Program Brochureobsmadhuchandra5707100% (1)
- Carve The Mark - Veronica RothDocument11 pagesCarve The Mark - Veronica RothCristina Duru100% (1)
- Contributions of Western Scholars To Kannada LinguisticsDocument20 pagesContributions of Western Scholars To Kannada LinguisticsMallikarjun100% (1)
- Tamil and KannadaDocument20 pagesTamil and Kannadaராஜா MVS100% (1)
- Learn Kannada: GreetingsDocument9 pagesLearn Kannada: GreetingsHari HaranNo ratings yet
- Kannada KaliDocument20 pagesKannada Kali29_ramesh170100% (1)
- KannadaDocument6 pagesKannadaraniNo ratings yet
- Tamil Grammar PDFDocument130 pagesTamil Grammar PDFgopicryo100% (1)
- KannadaDocument3 pagesKannadaLokesh TripathiNo ratings yet
- Learn Kannada OnlineDocument3 pagesLearn Kannada OnlineSasi KumarNo ratings yet
- Kannada Grammar MoodsDocument64 pagesKannada Grammar Moodsgopi_63510378100% (2)
- Simple Past Tense Tutorial: Author: Gopi Sudarson Created On: 27 March 2020 Updated On:5 April 2020Document28 pagesSimple Past Tense Tutorial: Author: Gopi Sudarson Created On: 27 March 2020 Updated On:5 April 2020gopi_63510378No ratings yet
- Kannada Learning Forum: List of VolunteersDocument14 pagesKannada Learning Forum: List of VolunteersSandeep PanditaNo ratings yet
- DEIXISDocument8 pagesDEIXIStommykatroNo ratings yet
- Noam Chomsky, Three Models For The Description of LanguageDocument12 pagesNoam Chomsky, Three Models For The Description of Languagebogdanciprian100% (1)
- The Origin, Development and Usage of the Kannada LanguageDocument28 pagesThe Origin, Development and Usage of the Kannada Languagehmtramesh100% (2)
- Top 20 Kannada words and phrasesDocument2 pagesTop 20 Kannada words and phrasesPuruganti RameshNo ratings yet
- Pà Àßqà Àtð Àiá Éaiàä Àäß Àçtðuéæ J: (Complete The Kannada VarnamaleDocument8 pagesPà Àßqà Àtð Àiá Éaiàä Àäß Àçtðuéæ J: (Complete The Kannada VarnamaleTanay Venu100% (1)
- A Study On Financial Performance in Kumbakonam Mutual Benefit Fund LimitedDocument4 pagesA Study On Financial Performance in Kumbakonam Mutual Benefit Fund LimitedEditor IJTSRDNo ratings yet
- Kannada Text RecognitionDocument7 pagesKannada Text RecognitionIJRASETPublicationsNo ratings yet
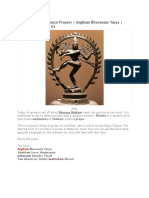
- Dhyana Shlokam Dance Prayer to Lord ShivaDocument2 pagesDhyana Shlokam Dance Prayer to Lord ShivaanisophileaNo ratings yet
- Research MethodologyDocument22 pagesResearch MethodologyKeerthana SenthilkumarNo ratings yet
- (Don't Bother To Memorize The Technical Terms Used!) : Three Places Two NumbersDocument5 pages(Don't Bother To Memorize The Technical Terms Used!) : Three Places Two NumbersTestNo ratings yet
- Learn to read and write GujaratiDocument29 pagesLearn to read and write GujaratiPiyush ShahNo ratings yet
- Learn Kannada alphabet with easy examplesDocument5 pagesLearn Kannada alphabet with easy examplescom mailNo ratings yet
- Implementation of Sandhi Viccheda For Sanskrit WordssentencesparagraphsDocument7 pagesImplementation of Sandhi Viccheda For Sanskrit WordssentencesparagraphsabhikokkadNo ratings yet
- KannadaDocument28 pagesKannadaGaneshenNo ratings yet
- English-Kannada Alphabets TranslitDocument8 pagesEnglish-Kannada Alphabets TranslitSomya Harsh100% (1)
- Kannada ModalsDocument6 pagesKannada Modalsshridhar.aNo ratings yet
- Kannada Alphabet and PronunciationDocument5 pagesKannada Alphabet and PronunciationPrakash Kumar SinghNo ratings yet
- Category CarnaticDocument18 pagesCategory CarnaticxiaoboshiNo ratings yet
- Kannada Kali TextDocument22 pagesKannada Kali TextHarryNo ratings yet
- Reported Speech Extra Practice 2 Key AnswersDocument5 pagesReported Speech Extra Practice 2 Key AnswersbollisettidurgabhavaniNo ratings yet
- Kannada Three Letter WordsDocument9 pagesKannada Three Letter Wordsmona mady100% (2)
- Hindi NumbersDocument5 pagesHindi NumberssrajaprojectsNo ratings yet
- Kannada WordDocument10 pagesKannada WordsubusriNo ratings yet
- HINDI CompleteDocument30 pagesHINDI Completesasi rekhaNo ratings yet
- Tulu Phrasebook GuideDocument8 pagesTulu Phrasebook Guidelokwader100% (1)
- Language Technology in TamilDocument38 pagesLanguage Technology in Tamilnehru444No ratings yet
- Tutorial Ans (Paragraph Completion) PDFDocument3 pagesTutorial Ans (Paragraph Completion) PDFShrutiNo ratings yet
- GK DuniyaDocument5 pagesGK Duniyachitti poluriNo ratings yet
- Indian LogicDocument72 pagesIndian LogicravirsnNo ratings yet
- FDP Brochure 2018Document2 pagesFDP Brochure 2018anoop13No ratings yet
- Pookal PookumDocument1 pagePookal PookumvimalNo ratings yet
- FTII Entrance Exam MCQ Sample PaperDocument6 pagesFTII Entrance Exam MCQ Sample PaperAvinash TamDiyaNo ratings yet
- Manas PPT 2Document11 pagesManas PPT 2Devraj HulmaniNo ratings yet
- Semantic Analysis: Natural Language Processing (CSE 5321)Document35 pagesSemantic Analysis: Natural Language Processing (CSE 5321)ft taNo ratings yet
- Map of KathmanduDocument1 pageMap of KathmanduOld NepalNo ratings yet
- The Concept of Duty in Kalidasa's WorksDocument5 pagesThe Concept of Duty in Kalidasa's WorksEditor IJTSRDNo ratings yet
- English Phrase Equiv. Tulu Phrase Equiv. Kannada Phrase Equiv. Konkani PhraseDocument3 pagesEnglish Phrase Equiv. Tulu Phrase Equiv. Kannada Phrase Equiv. Konkani PhraseNaomi Dsilva100% (1)
- Importance of Hindi Thesaurus in NLP and Hindi Language Script DescriptionDocument3 pagesImportance of Hindi Thesaurus in NLP and Hindi Language Script DescriptionGURSEWAK SINGHNo ratings yet
- Study of Noun Phrase in Urdu: KeywordsDocument15 pagesStudy of Noun Phrase in Urdu: KeywordsUMT JournalsNo ratings yet
- Welcome To International Journal of Engineering Research and Development (IJERD)Document4 pagesWelcome To International Journal of Engineering Research and Development (IJERD)IJERDNo ratings yet
- The Tondano65533s AdjectiveDocument10 pagesThe Tondano65533s AdjectiveEffan Ferrary GultomNo ratings yet
- Workshop On Tone, TypologyDocument15 pagesWorkshop On Tone, TypologyNaing KhengNo ratings yet
- TIBCO Cyberlogitec CsDocument2 pagesTIBCO Cyberlogitec CsSudhakar GanjikuntaNo ratings yet
- Mitra Samruddhi 8Document11 pagesMitra Samruddhi 8Sudhakar GanjikuntaNo ratings yet
- Bhagavatam Vol 5Document405 pagesBhagavatam Vol 5SarmaBvr100% (1)
- Moac FileDocument24 pagesMoac FileSudhakar GanjikuntaNo ratings yet
- RealUpgradeExperiences11itoR12 PDFDocument30 pagesRealUpgradeExperiences11itoR12 PDFnagendranathareddyNo ratings yet
- 4 Bedroom FarmhouseDocument2 pages4 Bedroom FarmhouseSudhakar GanjikuntaNo ratings yet
- Question & Answer On Share PointDocument10 pagesQuestion & Answer On Share PointSudhakar GanjikuntaNo ratings yet
- Ebs Release 12 UpgradeDocument21 pagesEbs Release 12 UpgradeSudhakar GanjikuntaNo ratings yet
- Olympiad Resource BooksDocument2 pagesOlympiad Resource BooksSudhakar GanjikuntaNo ratings yet
- Oracle Apps R12 ArchitectureDocument19 pagesOracle Apps R12 ArchitectureSudhakar GanjikuntaNo ratings yet
- Contract Farming Van GentDocument23 pagesContract Farming Van GentSudhakar GanjikuntaNo ratings yet
- LJ HookerDocument2 pagesLJ HookerSudhakar GanjikuntaNo ratings yet
- Oracle r12 Appstech Tca Technical Ver.1Document31 pagesOracle r12 Appstech Tca Technical Ver.1shanmugaNo ratings yet
- Oracle DBA Apps CloningDocument20 pagesOracle DBA Apps CloningSudhakar GanjikuntaNo ratings yet
- DBI User Guide-1Document490 pagesDBI User Guide-1Sudhakar GanjikuntaNo ratings yet
- Ilife BrochureDocument1 pageIlife BrochureSudhakar GanjikuntaNo ratings yet
- India Karnataka Market SummaryDocument2 pagesIndia Karnataka Market SummarySudhakar GanjikuntaNo ratings yet
- Daily ActivityDocument15 pagesDaily ActivityPradeep ReddyNo ratings yet
- Apps Technical Oracle-1Document6 pagesApps Technical Oracle-1Sudhakar GanjikuntaNo ratings yet
- Certified Rac Scenarios For Oracle E-Business Suite CloningDocument4 pagesCertified Rac Scenarios For Oracle E-Business Suite CloningSudhakar GanjikuntaNo ratings yet
- 11th FYP Karnataka Perspective - Seminar 4.5.07Document18 pages11th FYP Karnataka Perspective - Seminar 4.5.07Bharath VenkateshNo ratings yet
- Property Title Registration System For Karnataka: 05.05.2010 IndexDocument16 pagesProperty Title Registration System For Karnataka: 05.05.2010 IndexSudhakar GanjikuntaNo ratings yet
- 121 AdmpDocument58 pages121 Admponeeb350No ratings yet
- Step by Step Document To Create Standby Database9iDocument8 pagesStep by Step Document To Create Standby Database9iJayendra GhoghariNo ratings yet
- 13 13 Draft Agreement For Use of EquipmentDocument18 pages13 13 Draft Agreement For Use of EquipmentSudhakar GanjikuntaNo ratings yet
- AP Land Use RegularityDocument36 pagesAP Land Use RegularitySudhakar GanjikuntaNo ratings yet
- Sandal Wood 148Document9 pagesSandal Wood 148Sudhakar GanjikuntaNo ratings yet
- Sandal WoodDocument7 pagesSandal WoodSudhakar GanjikuntaNo ratings yet
- Pests and diseases of sandalwood plants in nurseries and their managementDocument8 pagesPests and diseases of sandalwood plants in nurseries and their managementSudhakar GanjikuntaNo ratings yet
- Grammar-EXTRA Inspired 2 Unit 5 Verb Indirect and Direct ObjectDocument1 pageGrammar-EXTRA Inspired 2 Unit 5 Verb Indirect and Direct Objectrotrejo.tucNo ratings yet
- Interlang EA 13022017Document21 pagesInterlang EA 13022017Mint NpwNo ratings yet
- Passive Voice lesson plan teaches students grammar structureDocument5 pagesPassive Voice lesson plan teaches students grammar structureDiana GhebanNo ratings yet
- Relative ClauseDocument4 pagesRelative ClauseThucNguyenNgocNo ratings yet
- Present Perfect SimpleDocument6 pagesPresent Perfect SimpleEnginerr Isra Astudillo IsraNo ratings yet
- Document 1Document2 pagesDocument 1NeerNo ratings yet
- Day 8 - Noun PhrasesDocument28 pagesDay 8 - Noun PhrasesNorman Chen100% (2)
- The Language of Report WritingDocument22 pagesThe Language of Report WritingAgnes_A100% (1)
- Contoh Rancangan Pengajaran Harian Bahasa Inggeris Tahun 6Document22 pagesContoh Rancangan Pengajaran Harian Bahasa Inggeris Tahun 6cocorunner75% (8)
- Passive VoiceDocument2 pagesPassive VoiceSchoen CarlosNo ratings yet
- Aarne-Thompson Classification Systems - Wikipedia, The Free EncyclopediaDocument4 pagesAarne-Thompson Classification Systems - Wikipedia, The Free EncyclopedianishantlalNo ratings yet
- Teks Snapshot Elar GR 05Document6 pagesTeks Snapshot Elar GR 05api-339322543No ratings yet
- GR 3 Ocps Poetry UnitDocument34 pagesGR 3 Ocps Poetry Unitapi-300535577100% (1)
- Useful Vocabulary For Writting Book ReviewsDocument7 pagesUseful Vocabulary For Writting Book Reviewsvashira82No ratings yet
- Unit 6 Guardians of TraditionDocument47 pagesUnit 6 Guardians of Traditionmy_mint-222No ratings yet
- Test Your English Grammar SkillsDocument2 pagesTest Your English Grammar SkillsDaniela Popovska AngelovskaNo ratings yet
- Department of Education: Republic of The PhilippinesDocument4 pagesDepartment of Education: Republic of The PhilippinesCeeDyeyNo ratings yet
- Gram of GrammarDocument63 pagesGram of GrammarJ Velasco PeraltaNo ratings yet
- Lesson Plan 8Document7 pagesLesson Plan 8Allung SheinXyuNo ratings yet
- English Noun ClouseDocument4 pagesEnglish Noun ClouseNeutron EnglishNo ratings yet
- Daniel DefoeDocument15 pagesDaniel DefoeRangothri Sreenivasa SubramanyamNo ratings yet