Professional Documents
Culture Documents
Architecture Ingres V4
Uploaded by
strideworldCopyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Architecture Ingres V4
Uploaded by
strideworldCopyright:
Available Formats
INGRES Architecture Technique INGRES
ARCHITECTURE INGRES
DMSI/ANALYSE/MST du jj/10/OO ATI Page 1 sur 41
V 4.0
INGRES Architecture Technique INGRES
Sommaire
ARCHITECTURE INGRES......................................................................................................................................................1
SOMMAIRE.......................................................................................................................................................................................2
1. RAPPELS SUR LES BASES DE DONNÉES.........................................................................................................................4
1.1.VOCABULAIRE DES BASES DE DONNÉES RELATIONNELLES ET AUTRES...................................................................................................4
1.2.CONSTITUTION D’UN SGBD........................................................................................................................................................5
1.3.SÉCURITÉ ET INTÉGRITÉ...............................................................................................................................................................5
1.4.GESTION DES ACCÈS CONCURRENTS – NOTION DE TRANSACTION........................................................................................................5
2. PRÉSENTATION DE CA-OPENINGRES.............................................................................................................................6
2.1.HISTORIQUE...............................................................................................................................................................................6
2.2.VUE GÉNÉRALE..........................................................................................................................................................................6
3. ARCHITECTURE FONCTIONNELLE.................................................................................................................................7
3.1.PREMIER APERÇU........................................................................................................................................................................7
3.2.LE NOYAU.................................................................................................................................................................................8
3.2.1.Le serveur de données....................................................................................................................................................8
3.2.2.Le gestionnaire de connaissances..................................................................................................................................9
3.2.3.Le gestionnaire d'objets..................................................................................................................................................9
3.3.OUTILS DE DÉVELOPPEMENT D'APPLICATIONS.................................................................................................................................10
3.4.OUTILS UTILISATEUR.................................................................................................................................................................10
3.5.UTILITAIRES D'ADMINISTRATION..................................................................................................................................................10
4. DIFFÉRENTS TYPES D'ARCHITECTURE.......................................................................................................................11
4.1.INTRODUCTION.........................................................................................................................................................................11
4.2.ARCHITECTURE CENTRALISÉE......................................................................................................................................................11
4.3.ARCHITECTURE DISTRIBUÉE : CA-OPENINGRES / NET.................................................................................................................12
4.4.ARCHITECTURE RÉPARTIE : CA-OPENINGRES / STAR..................................................................................................................14
4.5.ARCHITECTURE RÉPLIQUÉE : CA-OPENINGRES / REPLICATOR.........................................................................................................16
5. ARCHITECTURE INTERNE................................................................................................................................................17
5.1.L’ACCÈS AUX DONNÉES – UTILISATION DU CACHE DMF................................................................................................................17
5.2.LA JOURNALISATION..................................................................................................................................................................20
5.3.GESTIONNAIRE DES COMMUNICATIONS..........................................................................................................................................20
6. AU CŒUR DU SERVEUR DE DONNÉES..........................................................................................................................23
7. LES MÉCANISMES DE LA JOURNALISATION.............................................................................................................26
7.1.LES OBJECTIFS..........................................................................................................................................................................26
7.2.LES MOYENS............................................................................................................................................................................27
7.3.LE FICHIER LOG.....................................................................................................................................................................28
7.3.1.Topologie du fichier LOG.............................................................................................................................................28
7.3.2.La vie du fichier LOG...................................................................................................................................................28
7.3.3.Le contenu du fichier LOG...........................................................................................................................................31
7.4.LES LOG BUFFERS............................................................................................................................................................31
7.5.LE FICHIER LOG DUAL.........................................................................................................................................................31
7.6.LE PROCESS D’ARCHIVAGE.........................................................................................................................................................32
8. EN CAS DE PROBLÈME.......................................................................................................................................................33
8.1.PANNES DU SERVEUR DE DONNÉES : MÉCANISME DE RECOUVREMENT.................................................................................................33
8.2.PANNE DU DISQUE : SAUVEGARDE ET ARCHIVAGE...........................................................................................................................34
9. GESTION DES ACCÈS CONCURRENTS..........................................................................................................................36
9.1.POURQUOI ?............................................................................................................................................................................36
9.2.SANS VERROUS, QUE SE PASSERAIT-IL ?........................................................................................................................................36
DMSI/ANALYSE/MST du jj/10/OO ATI Page 2 sur 41
V 4.0
INGRES Architecture Technique INGRES
9.3.COMMENT ?............................................................................................................................................................................38
9.4.OÙ ?......................................................................................................................................................................................38
9.5.LE DEAD LOCK..................................................................................................................................................................39
10. EN GUISE DE CONCLUSION............................................................................................................................................41
DMSI/ANALYSE/MST du jj/10/OO ATI Page 3 sur 41
V 4.0
INGRES Architecture Technique INGRES
1. Rappels sur les bases de données
1.1. Vocabulaire des bases de données relationnelles et autres
Les définitions concernant les bases de données que vous avez pu rencontrer dans d’autres cours, voir
d’autres lieux, ressemblent sans doute à ceci :
Une base de données est un ensemble structuré de données (on dit aussi intégré) modélisant un
univers réel. Ces données sont placées sur un support accessible par l'ordinateur et sont
partagées par plusieurs utilisateurs.
Un SGBD (système de gestion de base de données) est un ensemble de logiciels permettant la
gestion et le contrôle des accès aux données de la base et aux programmes qui les manipulent.
Au cours de l’histoire, plusieurs modèles de bases de données se sont succédés et on a tendance à dire
que chacun de ces modèles est une amélioration du précédent. C'est vrai en grande partie, mais avec une
petite réserve que nous évoquerons un peu plus loin.
Pour mieux appréhender les différences qui existent entre ces modèles, imaginons la situation suivante :
Un voyageur débarque à Roissy et désire se faire transporter par taxi rue de Courcelles dans le huitième
arrondissement.
On peut considérer que le problème se pose à plusieurs niveaux :
Niveau conceptuel règle de conduite, de circulation, de fonctionnement du taxi…
Niveau logique formalisation du problème particulier (aller à…)
Niveau physique utilisation de moyens pour résoudre le problème (passer par…)
Avec les Systèmes de Gestion de Fichiers (SGF) et le premier modèle de base de données (hiérarchique),
le chauffeur du taxi aurait pris l’itinéraire, toujours le même, fixé dans sa mémoire ou tracé sur son plan
pour se rendre à l’adresse demandée. C’est fiable à 100 % mais ne supporte aucune initiative ni aucun
« détournement ».
Avec le modèle suivant (réseau), le chauffeur aurait pu choisir entre plusieurs chemins prédéfinis. Liberté
apparente seulement puisqu’il n’a toujours pas la possibilité de faire varier son trajet une fois l’itinéraire
choisi.
En fait, jusque là, on ne pouvait résoudre un problème logique que par l’utilisation de moyens physiques
explicites.
Avec les travaux de CODD, et le modèle relationnel, le chauffeur de taxi devient intelligent ; il est capable
de définir un itinéraire tout seul en fonction, par exemple, des conditions de circulation du moment ou
d’éventuels desiderata « hors norme » du client (par exemple : en passant par un fleuriste et une
boulangerie).
Les trois niveaux précédemment cités devenant du coup autonomes, autonomie rendue possible grâce à la
programmation par les données. On s’intéresse au « quoi ? » plus au « comment ? »
Alors, quelle réserve pouvons-nous mettre à cette évolution qui semble pourtant bien pratique ?
En fait, si le modèle relationnel a mis tant de temps à percer, c’est tout simplement à cause de sa très
grande gourmandise en terme de taux d’occupation mémoire et de ressources puisqu’il faut calculer le
chemin d’accès aux données pratiquement à chaque fois. Nécessité qui n’existait pas avec le modèle
réseau qui rendait de très bons services dans une informatique de gestion moins exigeante que
maintenant.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 4 sur 41
V 4.0
INGRES Architecture Technique INGRES
1.2. Constitution d’un SGBD
Un SGBD est présenté traditionnellement sous la forme d’un système en trois couches :
La gestion des récipients de données sur les mémoires secondaires compose la première
couche : c'est le SYSTEME DE GESTION DE FICHIERS, entièrement lié au système
d’exploitation.
La gestion des données stockées dans les fichiers, le placement et l'assemblage de ces
données, la gestion des liens entre les données et des structures permettant de les retrouver
rapidement constitue la deuxième couche : c'est le système d'accès aux données ou SGBD
INTERNE.
La présentation des données aux programmes d'applications et aux usagers terminaux
ayant exprimé leurs besoins à l'aide de langages plus ou moins élaborés, constitue la fonction
essentielle de la troisième couche : c'est le SGBD EXTERNE qui assure d'une part, l'analyse et
l'interprétation des requêtes des usagers et d'autre part, la mise en forme des données échangées
avec le monde réel.
Mais, ceci ne représente en fait que 50% du code des logiciels constituant un SGBD tel que INGRES. En
effet, le monde n’étant pas parfait, il a fallu prévoir de nombreuses procédures « au cas où… » pour
pouvoir assurer trois des objectifs des bases de données, la sécurité, l’intégrité et le partage des données.
1.3. Sécurité et intégrité
Le but est d’assurer d’une part que seules les personnes autorisées pourront accéder et manipuler de
façon correcte les données de la base par :
Le contrôle des utilisateurs qui sont définis avec un ensemble de possibilités d’action (de
responsabilités) au niveau du SGBD et également un ensemble de droits d’utilisation des données
dans chacune des bases du système. Les utilisateurs devront alors s'identifier par un login et
s'authentifier par un mot de passe.
Le contrôle sur la validité des opérations effectuées par l'application de règles appelées
contraintes d'intégrité. Les plus connues étant les contraintes d'intégrité référentielle.
Et d’autre part que la base de données puisse être remise en état en cas de problème, remise en état
devant être réalisée sans redondance de travail pour les utilisateurs. Pour ce faire, il a été mis en place
des mécanismes permettant :
La protection contre les défaillances techniques, les pannes : le SGBD doit offrir des
procédures permettant la remise en état cohérent de la base en cas de problème. C'est le rôle des
mécanismes de la journalisation, de l’archivage et des sauvegardes.
1.4. Gestion des accès concurrents – Notion de transaction
Un des objectifs, et non des moindres, d’un système d’information fondé sur les bases de données est de
mettre à la disposition d’un grand nombre d’utilisateurs un ensemble cohérent de données. Ces données
vont donc être manipulées simultanément par un grand nombre d’utilisateurs.
Afin de garantir la cohérence des données, une attention particulière doit être portée lors des
manipulations effectuées par les différents utilisateurs. Cette cohérence est assurée au travers des
concepts de transactions et d’accès concurrents.
Une transaction est définie comme une unité logique de traitement qui, appliquée à un état cohérent des
données, restitue un nouvel état cohérent, modifié, de la base. Une transaction est dite atomique, c’est à
dire qu’elle doit être exécutée en entier ou pas du tout. Dans le cas d’une requête composée de plusieurs
DMSI/ANALYSE/MST du jj/10/OO ATI Page 5 sur 41
V 4.0
INGRES Architecture Technique INGRES
opérations (transaction multi-requêtes), si une des opérations ne peut pas être effectuée, alors toute la
transaction doit être considérée comme n’ayant jamais existé.
Exemple :
La transaction T effectue un virement de 100 F du compte A vers le compte B.
Les opérations nécessaires sont :
1) MODIFIER COMPTE A = COMPTE A – 100
2) MODIFIER COMPTE B = COMPTE B +100
Il paraît évident que pour éviter un dialogue difficile entre les deux clients A et B et le banquier, les deux
opérations doivent être indissociables et correctement effectuées ! ! Si un incident empêche la réalisation
de la deuxième opération, il faudra veiller à ce que la première soit annulée. On comprend bien dans cet
exemple ce qu’atomicité des transactions veut dire.
D’autre part, pour garantir un parallélisme d’exécution des transactions, une gestion fine des accès
concurrents est nécessaire. L’exécution simultanée de plusieurs transactions permet un haut débit
transactionnel. Cependant, il faut veiller à ce que l’exécution parallèle des transactions aboutisse au même
résultat que si elles étaient lancées séquentiellement. Pour ce faire, la solution classique consiste à gérer
un verrouillage des données. Procédé que nous étudierons au chapitre 9.
2. Présentation de CA-OpenIngres
2.1. Historique
C'est en 1970, lorsque M. CODD a proposé son fameux modèle relationnel, que plusieurs prototypes ont
été développés au sein des universités et des laboratoires de recherche.
Deux prototypes ont marqué l'histoire des bases de données relationnelles et font encore aujourd'hui
référence dans le domaine :
Le prototype SYSTEM-R développé par IBM entre 1974 et 1977, qui a donné naissance au
produit ORACLE.
Le prototype universitaire INGRES, développé à l'université de Berkeley à partir de 1973.
Connaître l’architecture de ces deux produits permet d’appréhender sans difficultés tous les SGBD
relationnels professionnels du marché.
Il est vrai qu’aujourd’hui, grâce à sa force commerciale, ORACLE a su s’imposer majoritairement, mais il
serait fallacieux de voir là une nette supériorité technique d’un produit par rapport à l’autre.
Commercialisé depuis 1980, INGRES a été initialement développé par la société Relational Technology
fondée par les professeurs de Berkeley, Ingres a été tout d’abord racheté par ASK puis par Computer
Associates en 1994. Il est alors devenu CA-OpenIngres.
INGRES a constamment innové, offrant des fonctionnalités avancées sur le marché à ses clients et
capitalisant un savoir-faire important pour appréhender les projets stratégiques d’entreprise. Par exemple,
Ingres fut le premier système à offrir la gestion des bases de données réparties dès 1987, un L4G orienté
objet en 1990 et les objets spatiaux en 1994.
2.2. Vue générale
CA-OpenIngres est un progiciel modulaire dont le noyau est un SGBDR composé de divers process (au
sens UNIX du terme), permettant une gestion efficace de la mémoire associée. Le processus serveur, au
centre de l’architecture, agit comme un véritable système d’exploitation qui s’appuie fortement sur le
système hôte en gérant le partage des tâches et en déléguant certaines fonctions à des processus
DMSI/ANALYSE/MST du jj/10/OO ATI Page 6 sur 41
V 4.0
INGRES Architecture Technique INGRES
esclaves. Ce qui permet de gérer un grand nombre d’utilisateurs en acceptant une montée en charge sans
dégradation linéaire des performances.
3. Architecture fonctionnelle
3.1. Premier aperçu
L'offre produit de CA-OpenIngres est composée d'un noyau et d'un ensemble d'outils. La figure ci-dessus
illustre l'architecture fonctionnelle de CA-OpenIngres.
NOYAU : assure toutes les fonctions de base d'un SGBD, d'un dictionnaire de données et d'une couche de
langage de requêtes constituant le seul moyen d'accéder aux données.
OUTILS DE DEVELOPPEMENT : Outils permettant le développement d'applications construites autour du
SGBD.
OUTILS UTILISATEURS : Outils destinés aux utilisateurs néophytes.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 7 sur 41
V 4.0
INGRES Architecture Technique INGRES
UTILITAIRES : Ensembles de fonctions destinées aux administrateurs.
OUTILS DE COMMUNICATION : Outils permettant l'utilisation de CA-OpenIngres en environnement
réseau.
3.2. Le noyau
Le noyau est la principale composante du SGBD. Il est composé du serveur de données et de deux
modules optionnels.
3.2.1. Le serveur de données
C'est lui qui assure les fonctions classiques d'un SGBD R :
Définition et manipulation de données au travers d’un langage propriétaire (QUEL) et d'un
langage standard (SQL).
Cohérence et intégrité des données
DMSI/ANALYSE/MST du jj/10/OO ATI Page 8 sur 41
V 4.0
INGRES Architecture Technique INGRES
Confidentialité des données
Sauvegarde et restauration des données
Gestion des transactions et des accès concurrents
Il est basé sur une architecture multithread et multiserveur. L'architecture multithread permet de répondre à
un grand nombre d'utilisateurs simultanés sans consommation excessive de ressources. L'architecture
multiserveur permet de lancer plusieurs instances du serveur accédant simultanément à toutes les bases
de données de l'installation. Ces instances partagent un cache pour accéder aux données, aux objets, aux
requêtes compilées, aux procédures et aux contextes des transactions en cours. L'équilibre de charge
entre les différents serveurs est assuré par un serveur appelé serveur de nom. Cette possibilité ne trouvant
sa raison d’être que sur des machines multiprocesseurs.
CA-OpenIngres possède un optimiseur de requête qui détermine la stratégie optimale d'accès aux
données en se basant sur une utilisation intensive des statistiques. L'optimiseur traduit automatiquement
toute requête sous la forme d’un plan d’exécution de requête. Ce plan d’exécution représente la meilleure
façon de traiter la requête en terme de temps CPU et de nombre d’E/S.
Enfin, les procédures base de données sont des procédures écrites en L4G, compilées une seule fois et
stockées dans la base. Elles sont partagées entre tous les utilisateurs et permettent un gain de
performance, puisqu’elles s'exécutent à chaque appel d'une application sans qu’il soit nécessaire de la
recompiler, et restent valables pour tous les utilisateurs.
3.2.2. Le gestionnaire de connaissances
Module optionnel pouvant rapidement devenir indispensable, le gestionnaire de connaissance offre les
possibilités suivantes :
GESTION DES REGLES : Les règles (RULES) sont définies à partir des règles de gestion de l'entreprise
qui ne peuvent pas être traduites par des contraintes d'intégrité au niveau des tables et se présentent
comme des petites routines exécutées automatiquement à chaque mise à jour dans la base. Le
développement d'application, déchargé de ces traitements, y gagne en productivité. (Exemple : si une
requête doit créer une commande pour un client, une règle peut vérifier que le client a bien réglé toutes les
factures de plus d'un mois d'ancienneté).
CONTROLE DES RESSOURCES : Un contrôle de la consommation excessive des ressources
(processus, mémoire... ) pour chaque utilisateur permet de repérer les excès et de prévenir le blocage des
applications en exploitation.
GESTION DES AUTORISATIONS : Les notions de rôle et de groupe d'utilisateurs offrent une meilleure
gestion des autorisations d'accès aux données et aux applications en ajoutant une sur-couche aux
fonctionnalités déjà proposées par SQL.
GESTION DES EVENEMENTS : Les événements base de données permettent de synchroniser les
applicatifs. C'est un moyen centralisé de communiquer avec une tâche applicative en attente d'un
événement qui conditionne son comportement (insertion dans une table, atteinte d'une valeur pour un
attribut, avertissement de l'arrêt du SGBD... ).
3.2.3. Le gestionnaire d'objets
Ce module permet de définir des données dont le type sort des sentiers battus que sont ‘integer’, ‘float’,
‘char’, ‘varchar’, ‘date’...
Des types de données complexes peuvent être définis par l'utilisateur (User-defined Data Type) ainsi que
des données de type géométrique (Spatial Data type).
DMSI/ANALYSE/MST du jj/10/OO ATI Page 9 sur 41
V 4.0
INGRES Architecture Technique INGRES
Contrairement à certains SGBD qui se contentent de stocker les données de ce type sous forme binaire,
CA-OpenIngres permet leur manipulation directement sous SQL au travers de fonctions et opérateurs
associés.
3.3. Outils de développement d'applications
Autour d'une base de données, CA-OpenIngres permet le développement d'applications grâce à divers
outils :
MONITEUR SQL : Interface en mode ligne qui permet l'exécution interactive des commandes SQL depuis
le système d'exploitation ou l'exécution des commandes regroupées dans un fichier (script SQL).
MONITEUR ISQL : Interface interactive permettant l'édition et l'exécution des commandes SQL.
MONITEUR ESQL : Ensemble d'outils permettant l'utilisation du langage SQL dans des programmes écrits
en langage de troisième génération (C, Pascal, Cobol, Fortran...). Ces outils sont communément appelés
‘précompilateurs' ou 'interfaces programmatiques'.
CA-OPENROAD : Outils de développement de quatrième génération qui permet la génération
d'applications dans un environnement graphique.
ABF (Application By Forms) : Langage de quatrième génération qui permet des accès à la base de
données à travers des écrans de présentation créés avec VIFRED.
VISION : Générateur d'applications dans un environnement semi-graphique. Le développeur compose une
hiérarchie de modules en désignant pour chaque module une vue externe de la base et un type d'action.
L'application est automatiquement générée à partir de ces éléments. Le produit pouvant être finalisé grâce
à un éditeur de masque d'écran et un L4G. Vision permet aussi d'intégrer des modules externes.
3.4. Outils utilisateur
Les outils utilisateur permettent un accès simplifié aux données.
TABLES : Interface graphique permettant la manipulation des tables (définition des structures,
suppression, manipulation des données)
QBF (Query By Form) : permet de composer des requêtes à l'aide de menus, de tableaux et de touches
de fonction. Point n'est besoin de maîtriser SQL pour accéder aux données. Les requêtes construites sous
QBF peuvent être sauvegardées pour une utilisation ultérieure et intégrée dans des applications.
VIFRED (Vlsual Form EDitor) : permet la création de masque d'écran, à partir d'une proposition par
défaut de QBF personnalisable et pouvant intégrer des formules de calcul et des contrôles de saisie.
VIGRAPH (Visual GRAPHics ) : permet de présenter les résultats de requêtes SQL sous forme de
graphiques (courbes, histogrammes, diagrammes, etc... )
REPORT, RBF (Report By Form). REPORT WRITER : permettent de définir des états par défaut ou
personnalisés, simples ou paramétrés selon l'outil.
On peut accéder à l'ensemble de ces outils par l'utilitaire INGMENU
3.5. Utilitaires d'administration
L'ensemble des outils d'administration apporte aux administrateurs de bases de données et à
l'administrateur du SGBD un ensemble de fonctionnalités étendues. Citons-en quelques-uns :
CBF (Configure By Form) : outils interactifs de configuration de l'installation du SGBD.
IPM (Interactive Performance Monitor) : permet de visualiser différents aspects du fonctionnement de
CA-OpenIngres (état des verrous, statistiques, état des connexions, transactions actives... )
DMSI/ANALYSE/MST du jj/10/OO ATI Page 10 sur 41
V 4.0
INGRES Architecture Technique INGRES
ACCESSDB : outils du DBA qui permet de gérer les utilisateurs, les accès aux bases et les espaces
disques.
4. Différents types d'architecture
4.1. Introduction
Les applications et les données d'un système d'information peuvent être localisées sur un même ordinateur
central ou sur des ordinateurs différents. On distingue trois types d'architecture :
ARCHITECTURE LOCALISATION DES LOCALISATION DES
DONNEES TRAITEMENTS
Centralisée Ordinateur central Ordinateur central
Distribuée Ordinateur central Ordinateurs distants
Répartie (avec ou sans duplication) Ordinateurs distants Ordinateurs distants
Il y a souvent confusion entre distribuée et répartie. Une architecture répartie implique que les données de
la base sont localisées sur des ordinateurs différents.
La réplication de données permet de dupliquer une partie d'une base source vers une base cible. On parle
alors d'architecture répliquée, variante de l'architecture répartie.
4.2. Architecture centralisée
Ce type d'architecture est la plus simple à mettre en place et correspond aux premières générations de
SGBD qui étaient gérées par de gros systèmes (mainframe). A L'ESAT, CA-OpenIngres fonctionne ainsi.
Les différentes applications (dont les outils CA-OpenIngres) sont installées sur le serveur.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 11 sur 41
V 4.0
INGRES Architecture Technique INGRES
4.3. Architecture distribuée : CA-OpenIngres / NET
Dans cette architecture, première génération du concept Client/Serveur, la gestion des données est
assurée par un ordinateur central (le serveur) tandis que les applications utilisant ces données sont situées
sur des machines distantes (les clients). Ici, ce sont les traitements qui sont distribués entre ordinateurs
différents. Les données sont toujours centralisées
D’une manière générale, nous pouvons représenter l’architecture client/serveur comme sur la figure
suivante.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 12 sur 41
V 4.0
INGRES Architecture Technique INGRES
CA-OpenIngres propose pour cette architecture le module INGRES/NET qui ajoute une sur-couche au
réseau et encapsule les données en provenance et à destination des modules de CA-OpenIngres.
Le schéma suivant nous présente l’architecture client/serveur mise en place chez Ingres.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 13 sur 41
V 4.0
INGRES Architecture Technique INGRES
Il faut alors gérer les informations nécessaires pour établir des connexions avec les machines distantes. A
chaque machine, on attribue un nom virtuel (vnode) et on définit les données permettant d’accéder à cette
machine (adresse réseau, protocole, adresse d’écoute). L’utilitaire NETUTIL permet de gérer ces
informations (dans les versions Openingres 1.x).
4.4. Architecture répartie : CA-OpenIngres / STAR
L’approche répartie des bases de données nécessite l’existence d’un référentiel commun décrivant
l’ensemble de données constituant la base de données répartie. Ce référentiel est appelé aussi schéma
conceptuel global. Au niveau physique, les données sont stockées dans des bases de données locales
gérées par des SGBD identiques ou différents. Cette répartition est transparente pour les utilisateurs qui
voient l’ensemble de données comme une seule et unique base de données.
Chaque serveur de base de données locale est autonome par rapport aux autres serveurs et il est
administré séparément. Une panne locale ne rend pas ainsi indisponible l’ensemble des données. Les
autres bases locales restant disponibles.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 14 sur 41
V 4.0
INGRES Architecture Technique INGRES
Le module CA-OpenIngres/STAR est un serveur de données fédérateur d’un ensemble de bases de
données locales.
La définition d’une base de données répartie à partir d’un ensemble de bases locales se fait par la
définition de liens logiques (link). Chaque lien correspondant à une table d’une base locale (dans le même
esprit qu’un nœud virtuel permet de définir logiquement un serveur de données physique dans le mode
client/serveur). Les utilisateurs consulteront alors les données de la base répartie en utilisant ces liens,
sans connaître l’emplacement physique de ces données.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 15 sur 41
V 4.0
INGRES Architecture Technique INGRES
4.5. Architecture répliquée : CA-OpenIngres / Replicator
L'utilisation de la duplication de données (réplication) est rendue possible grâce à CAOpenlngres
/Replicator. Les avantages majeurs de ce procédé sont une meilleure disponibilité des données et une
diminution des coûts de télécommunication par rapport à l’architecture répartie. La réplication se fait par
propagation des mises à jours effectuées sur une base source vers une ou plusieurs bases cibles. Elle est
assurée de façon complètement transparente par rapport à l'applicatif.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 16 sur 41
V 4.0
INGRES Architecture Technique INGRES
5. Architecture interne
Le schéma ci-dessous nous montre l’architecture interne de CA-OpenIngres.
Autour du serveur de données, pièce centrale du système, s’articule un ensemble de processus, de zones
mémoires (buffer) et de fichiers. Les processus utilisateurs se connectent au serveur de données local (par
le serveur d’adresse) ou distant (par le serveur de communication).
5.1. L’accès aux données – utilisation du cache DMF.
Contrairement à ce que l’on pourrait croire, les données ne sont pas manipulées directement dans la base,
mais dans une zone mémoire particulière appelée cache base de donnée ou cache DMF.
Les données sont regroupées dans des pages de données, unité d’échange incontournable.
Jusqu'aux versions 1.n de CA-OpenIngres, la taille de la page est de 2048 octets (2k). Une page pouvant
contenir plusieurs occurrences d'une table, mais une occurrence ne pouvant pas être coupée entre deux
pages. Conséquence immédiate, la taille maximale d'une occurrence dans une table est de 2k caractères
(en fait, un peu moins, puisque le système se réserve 40 octets sur chaque page). A partir de la version 2,
DMSI/ANALYSE/MST du jj/10/OO ATI Page 17 sur 41
V 4.0
INGRES Architecture Technique INGRES
on a la possibilité de paramétrer la taille des pages de 2k à 64k (en valeur des puissances de 2), la valeur
par défaut étant de 2k pour des raisons de compatibilité avec les versions antérieures.
A chaque fois qu’une requête arrive au serveur de données, celui-ci va voir si les pages de données
nécessaires sont présentes dans le cache. Si ce n’est pas le cas, il chargera ces pages. A chaque requête,
il est bien sûr préférable que la page de données nécessaire soit déjà en zone mémoire. Dans ce cas, le
jargon des administrateurs parle de ‘HIT’. Dans le cas contraire, lorsque la page doit être chargée, on parle
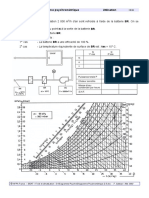
de ‘MISS’. Deux termes qui expriment bien les préoccupations en terme de performance d’accès. En fait,
un taux de 90% de ‘HIT’ est recherché. Ce taux nécessite une taille importante du cache DMF qu’il faudra
donc paramétrer en conséquence.
En ce qui concerne l’écriture des pages modifiées dans la base, deux options sont possibles. L’une qui
favorisera les performances en minimisant les accès aux disques (option avec FAST-COMMIT) et l’autre
dont l’emploi garantira un recouvrement beaucoup plus rapide en cas de panne (option sans FAST-
COMMIT) mais au détriment des performances. Dans la plupart des cas, la première option est la meilleure
(c’est en fait l’option par défaut). Toutefois, si le système est très instable et risque de tomber en panne
souvent, il sera préférable de choisir la deuxième option pour ne pas s’exposer à des recouvrements très
longs. La longueur du recouvrement s’explique par le fait qu’il est nécessaire de réexecuter les
transactions validées (commitées) et non écrites sur le disque. Pour de grosses bases de données, le
temps de recouvrement se compte en heures, ce qui aura pour conséquence de mettre les utilisateurs au
chômage technique pendant ce temps-là !
Dans le cas où le FAST-COMMIT n’est pas activé, les pages modifiées sont écrites dans la base
immédiatement au moment de la validation de la transaction. On risque bien sûr d’être amené à écrire
plusieurs fois la même page, d’où la perte de performance mentionnée plus haut. En revanche, on est sûr
que les données modifiées sont bien écrites physiquement sur les disques et qu’il n’y aura pas à revenir
dessus !
Pour profiter pleinement du FAST-COMMIT, l’écriture des pages du cache vers la base va être assurée par
des processus asynchrones (qui tournent en arrière plan), de manière totalement détachée des traitements
effectués sur les données. On ne sait jamais à quel moment la page modifiée par une transaction va être
écrite sur le disque.
Le schéma suivant nous montre la topologie du buffer DMF.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 18 sur 41
V 4.0
INGRES Architecture Technique INGRES
En fonctionnement avec l’option FAST-COMMIT, les pages de données sont chargées au fur et à mesure
des besoins dans le cache jusqu’à ce que la limite wbstart soit atteinte. A ce moment, les processus
d’écriture asynchrone (wbthread) se déclenchent et se chargent de le vider jusqu’à la limite wbend qui
marque l’arrêt des processus esclaves. Nous constatons la persistance de page dans la zone basse du
cache. Ces pages seront vidées à des moments particuliers appelés points de consistance ou points de
synchronisation sur lesquels nous reviendrons. A ces moments-là, un processus particulier (consistency-
point thread) réalisera le vidage complet du cache, provoquant la synchronisation entre les valeurs
stockées en zone mémoire et l’état physique (sur les disques) de la base.
Le premier constat qui vient tout de suite à l’esprit est qu’il existe entre deux points de consistance une
divergence entre ce que les utilisateurs ont pu effectuer comme modification et ce qui est réellement écrit
dans la base. Divergence d’autant plus grande que le cache remplit bien son rôle (+ de 90% de HIT).
Conséquence directe : en cas de problème, toutes les données en mémoire risqueraient d’être perdues.
Heureusement, il existe un mécanisme, la journalisation, qui permet d’assurer la sécurité des données.
Le second point remarquable réside dans le fait que les divergences correspondent au contenu du cache
entre deux points de consistance. Donc, pour minimiser ces divergences, il sera judicieux d’en régler la
fréquence. Le recouvrement sera d’autant plus rapide que la période de temps entre deux points de
consistance sera courte.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 19 sur 41
V 4.0
INGRES Architecture Technique INGRES
5.2. La journalisation
Le principe de la journalisation est de consigner dans un fichier spécial toutes les modifications apportées
aux données de la base par chaque transaction. C’est une sorte de livre de bord du SGBD. Ce livre de
bord est appelé ‘journal des transactions’ ou ‘log file’. Le détail du contenu et du fonctionnement du LOG
FILE sera abordé au chapitre 7.
Nous avons vu qu’avec le FAST-COMMIT, le serveur peut valider une transaction (exécuter un COMMIT)
sans écrire immédiatement les pages de données physiquement dans la base. La journalisation impose
d’écrire avant toute chose dans le LOG FILE la description de la modification apportée. L’utilisation du LOG
buffer diffère du buffer DMF en ce que les informations qui y sont écrites vont être transférées dans LOG
FILE sans attendre. Ceci permettant de garantir que les écritures dans la base sont représentées par des
enregistrements dans le LOG et donc de permettre un fonctionnement totalement sécurisé du système.
5.3. Gestionnaire des communications
Le gestionnaire de communication (General Communication Facility ou GCF) est un ensemble de services
et de protocoles assurant la gestion des communications entre les différents composants de CA-
OpenIngres. Il est composé de trois éléments :
GENERAL COMMUNICATION AREA (GCA) : cet élément est le plus bas niveau du GCF. C'est un
protocole utilisé pour les communications inter-processus assurant les échanges des requêtes et des
résultats sous formes de messages.
SERVEUR DE COMMUNICATION (GCC) : ce serveur se présente comme un processus qui est
responsable de la communication entre un processus client et un serveur de données à travers le réseau.
Il est utilisé par INGRES/NET. Il peut y avoir plusieurs serveurs de communication (en cas de protocoles
différents ou de fort débit par exemple).
SERVEUR DE NOM (GCN) : appelé aussi name server ou serveur d’adresse, il gère la liste des serveurs
de données, des serveurs de données réparties (STAR) et des serveurs de communication disponibles
dans une installation. Il fournit aux processus utilisateurs les informations nécessaires pour se connecter à
l’un de ces types de serveur de données. Il y a un seul serveur de nom par installation.
Pour bien comprendre comment s’articulent ces différents éléments, regardons les schémas suivants.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 20 sur 41
V 4.0
INGRES Architecture Technique INGRES
Dans le cas d’une architecture centralisée
L’application fait une demande de connexion au serveur de nom (name server ou gcn) [1]. Le gcn, véritable
annuaire des serveurs de données disponibles, renvoie à l’application l’adresse du processus serveur de
données qui convient (le choix est basé, en règle générale sur un équilibrage des charges de travail des
serveurs) [2]. L’application adresse sa requête au serveur de données désigné [3]. Le serveur de données
traite la requête [4] et retourne les résultats à l’application [5].
DMSI/ANALYSE/MST du jj/10/OO ATI Page 21 sur 41
V 4.0
INGRES Architecture Technique INGRES
Dans le cas d’une architecture client / serveur
L’application qui se connecte [1] reçoit du gcn l’adresse du processus qui va se charger de mettre en
contact la machine client et la machine serveur : le GCC [2]. L’application transmet sa requête au gcc [3]
qui établit le dialogue (au sens réseau du terme) avec le gcc de la machine serveur [4] via le protocole
réseau (ici, en exemple, TCP/IP) et une couche d’interface propre à Ingres (Ingres/net). Ensuite, le gcc
demande au gcn de la machine serveur de lui communiquer l’adresse d’un processus serveur de données
[5] et [6]. Le gcc se comporte alors comme une application vis à vis du serveur de données qui va traiter la
requête et lui retourner le résultat [7]. Enfin, ce résultat est retransmis par le chemin inverse à l’application
sur la machine client [8] et [9].
DMSI/ANALYSE/MST du jj/10/OO ATI Page 22 sur 41
V 4.0
INGRES Architecture Technique INGRES
6. Au cœur du serveur de données
Le grand maître de cérémonie du SGBD est le serveur de données. C’est lui qui en définitive traite la
requête fournie par l’application. Un serveur de données est composé de modules dont chacun est
spécialisé dans l’étape du traitement d'une requête.
Le SGBD CA-OpenIngres fonctionne en interne selon l'architecture client/serveur. Toute interaction avec la
base de données se fait à travers deux processus :
Un processus client qui assure toutes les taches de présentation et de calcul.
Un processus serveur qui reçoit toutes les demandes d'accès aux données, les analyse,
les optimise, les traite puis rend la main au processus utilisateur.
La figure suivante représente les différents modules qui constituent le serveur de données.
Détaillons le rôle de chaque module :
DMSI/ANALYSE/MST du jj/10/OO ATI Page 23 sur 41
V 4.0
INGRES Architecture Technique INGRES
SYSTEME CONTROLE FACILITY (SCF) : C'est le G.O. du traitement des demandes des utilisateurs. Il
reçoit les requêtes et coordonne les actions des autres modules du serveur de données. Il assure la
maintenance des contextes d'exécution des différentes requêtes actives en architecture multithread. Il est
aussi responsable des accès aux ressources partagées telles que les sémaphores et la mémoire. Il est
également responsable de la gestion des opérations de lancement et de l'arrêt du serveur, et de
l’initialisation des sessions.
PARSER FACILITY (PSF) : Ce module assure la conversion des commandes soumises au serveur d'un
format texte en un format interne. Ce format interne est composé d'un ensemble d'opérations élémentaires
de l'algèbre relationnelle. Des informations supplémentaires extraites du dictionnaire de données, telles
que la structure des tables manipulées, les droits et les définitions des vues, sont rajoutées à la
commande. Ces informations additionnelles sont destinées à l'optimiseur pour générer un meilleur plan
d'exécution. Notons que c'est ce module qui vous informera si une erreur de syntaxe s'est
malencontreusement glissée dans la requête que vous voulez faire exécuter.
OPTIMIZER FACILITY (OPF) : C’est le module central, capital, du serveur qui élabore le plan d’exécution
optimal de la requête.
Comment ?
A partir d’un ensemble de stratégies d’accès au données, l’OPF choisit la meilleure en utilisant, pour ces
estimations, des indicateurs : TMP CPU et DISK I/O (converti en TMP CPU). Il calcule les temps CPU d’un
certain nombre de stratégies (hypothèses) à partir des informations reçues du PSF qui sont analysées et
transformées en QEP (Query Execution Plan) selon un algorithme interne mettant en jeu des données
statistiques dont la fraîcheur est primordiale ou, à défaut, en se basant sur des règles prédéterminées (ce
qui est nettement moins efficace). La meilleure de ces stratégies sera utilisée. Bien évidemment, le travail
de recherche de l’OPF n’est pas infini et s’arrête au bout d’un certain temps (TIME OUT).
Le QEP est mémorisé jusqu’à son utilisation dans le ‘QSF Pool’. Il peut également être mémorisé pour une
utilisation future dans le cas de commandes répétitives (REPEATED dans une syntaxe ESQL). Le plan
d'exécution d'une requête peut être visualisé à l'aide de la commande SET QEP.
QUERY STORAGE FACILITY (QSF) : Ce module gère la mémoire partagée nécessaire pour la
mémorisation des requêtes sous leurs différentes formes (format texte, interne et plan d'exécution). La
mémorisation temporaire ou permanente des plans d'exécution générés par le OPF permet de les ré-
exécuter.
QUERY EXECUTION FACILITY (QEF) : Ce module est en charge d'exécuter les plans d'exécution des
commandes générées par l'OPF.
RELATION DESCRIPTION FACILITY (RDF) : Ce module gère la mémorisation dans un cache des
informations relatives aux tables et aux colonnes utilisées par les commandes SQL courantes. Ces
informations sont utilisées par le parser (PSF), l'OPF et le serveur de données réparties (INGRES/STAR).
ABSTRACT DATA TYPE FACILITY (ADF) : Ce module gère toutes les actions relatives aux types de
données telles que les opérations de comparaison et de conversion. Il gère aussi tous les types de
données définis par les utilisateurs. Il effectue les opérations en virgule flottante.
DATA MANIPULATION FACILITY (DMF) : Ce module gère les opérations de chargement des données
des disques (fichiers de données) vers le cache DMF, le contrôle des transactions et les accès
concurrents, ainsi que les différents types de structures de stockage (heap, isam, hash, btree). Pour ce
faire, il utilise un système de journalisation et de verrouillage qui sera présenté plus loin.
Résumons le déroulement d'une requête:
La requête arrive sur le coordinateur (SCF).
Le texte de la requête est stocké (QSF).
DMSI/ANALYSE/MST du jj/10/OO ATI Page 24 sur 41
V 4.0
INGRES Architecture Technique INGRES
La requête est traduite en arbre (PSF) après recherche dans le catalogue système des
intégrités, des droits et des vues (RDF via DMF).
Cet arbre est stocké (QSF).
L'arbre est traduit en plan d'exécution (OPF) après recherche dans les catalogues
systèmes des statistiques (RDF via DMF).
Ce plan d'exécution est stocké (QSF).
Gestion de l'exécution (QEF et éventuellement ADF) et recherche des données (DMF).
Les données sont renvoyées au coordinateur (SCF) qui transmet les résultats au client.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 25 sur 41
V 4.0
INGRES Architecture Technique INGRES
7. Les mécanismes de la journalisation
7.1. Les objectifs
Pour présenter très globalement le but du système de journalisation, on pourrait dire qu’il permet d’assurer
la cohérence des bases de données.
Nous avions déjà vu l’un des aspects de la journalisation qui est de garantir que les modifications
apportées aux données et non écrites physiquement sur le disque pour cause d’utilisation du fast-commit
et des écritures asynchrones ne seront pas perdues en cas de panne du serveur de données.
Un autre objectif est de permettre l’annulation d’une transaction (volontaire ou non) indépendamment des
autres.
Regardons le schéma suivant.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 26 sur 41
V 4.0
INGRES Architecture Technique INGRES
Si on considère les traitements dans leur globalité, on ne pourra que rester en l’état 2, en conservant les
modifications de T1 et T2 ou revenir en l’état 1 (par une restore de la sauvegarde) et en annulant d’un bloc
les modifications apportées par T1 et T2. On ne pourra pas annuler une transaction sans annuler l’autre.
Par contre, si l’on écrit quelque part ce que fait la transaction T1 et ce que fait la transaction T2, il sera
possible d’utiliser ces informations pour annuler l’une des transactions sans toucher au travail de l’autre.
Le journal des transactions (log file) contient justement ces informations et le système de journalisation (ou
système de logging) fournit les outils nécessaires à son exploitation.
7.2. Les moyens
Le système de journalisation comprend plusieurs éléments :
Le fichier LOG (journal des transactions)
Un fichier LOG DUAL (réplication automatique et optionnelle du fichier LOG)
Les log buffers
Le serveur de recouvrement
Le process d’archivage
DMSI/ANALYSE/MST du jj/10/OO ATI Page 27 sur 41
V 4.0
INGRES Architecture Technique INGRES
7.3. Le fichier LOG
7.3.1. Topologie du fichier LOG
Le fichier LOG est un fichier circulaire de taille fixe ( par défaut 16 Mo, mais en général plus grand) dans
lequel sont consignées les informations permettant de défaire les transactions (rollback) et de retrouver
une base cohérente après un crash du système ou du serveur de données.
Fichier unique pour chaque installation de INGRES, ce fichier est obligatoire pour que le SGBD puisse
fonctionner. Il devrait résider sur un disque rapide à faible contention d’accès, voir un disque dédié.
7.3.2. La vie du fichier LOG
Le remplissage du LOG FILE se déroule de manière fort simple. Les pages de données en provenance
des LOG BUFFERS sont écrites dans le LOG par des processus spécialisés (les log-writers).
Régulièrement, un point de consistance est généré. A ce moment, rappelons que le contenu du CACHE
DMF est écrit sur les disques. A ce moment privilégié, le système écrit une information spéciale dans le
LOG FILE, qui permet de mémoriser, de photographier l’état des bases ouvertes et de noter les
DMSI/ANALYSE/MST du jj/10/OO ATI Page 28 sur 41
V 4.0
INGRES Architecture Technique INGRES
transactions actives (en cours) à cet instant. La fréquence de ces points de consistance est paramétrable
(par exemple, tous les 10% de remplissage du LOG). Comme nous le verrons plus loin, le recouvrement
s’effectuant à partir du point de consistance le plus récent, il y a corrélation directe entre la fréquence de
ces points de consistance et la rapidité de recouvrement en cas de panne du serveur de données.
Le fonctionnement d’un fichier circulaire est tel que la fin de fichier se déplace dynamiquement au fur et à
mesure des écritures, ce qui posera problème lorsque la boucle sera bouclée et lorsque la fin de fichier
atteindra le début de fichier. Ce genre d’événement est tout à fait impensable pour un bon fonctionnement
du SGBD. Heureusement, tout est prévu. Notons en premier lieu que les informations utiles du log file
concernent exclusivement les transactions en cours. Les informations concernant les transactions
achevées pouvant être effacées. Il existe justement un processus qui a la charge de supprimer les
informations inutiles et de récupérer de la place dans le log file, c’est le process d’archivage.
La vie du log repose sur deux processus : celui qui écrit les informations dans le log file et celui dont la
tâche est de récupérer de la place.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 29 sur 41
V 4.0
INGRES Architecture Technique INGRES
Malheureusement, il peut arriver que le log file se remplisse trop vite et que le process d’archivage n’arrive
plus à suivre. Pour éviter que cette situation ne dégénère et pour protéger les informations du log file
contre un écrasement intempestif, deux indicateurs sont positionnés.
Ces deux indicateurs ou limites représentent des taux de remplissage du log file.
La première limite, appelée ‘FORCE ABORT LIMIT’, est située vers 80% de la taille du log file. Si cette
limite est atteinte, le système tente d’annuler la transaction bloquante (la plus ancienne) par un rollback
forcé, tout en laissant les autres transactions tourner. Pendant ce temps (le rollback n’est pas instantané !),
d’autres informations continuent à être inscrites sur le log file. Encore une fois, si les écritures sont
nombreuses, la deuxième limite peut être atteinte. Cette limite, appelée ‘LOG FULL LIMIT’ se positionne en
général à 95% de la taille du log file. A ce moment, le système bloque les utilisateurs et annule toutes les
transactions en cours. Il est évident qu’il est préjudiciable pour la rentabilité d’un système d‘information que
ce phénomène se produise souvent ! Si c’est le cas, l’administrateur du SGBD aura à résoudre le problème
en intervenant soit sur la taille, soit sur les paramètres du log file, soit sur le positionnement relatif des deux
limites.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 30 sur 41
V 4.0
INGRES Architecture Technique INGRES
7.3.3. Le contenu du fichier LOG
Le journal des transactions est composé d'articles qui indiquent les événements principaux qui affectent la
base de données :
Début d'une nouvelle transaction
Fin d'une transaction (avec la confirmation des mises à jour)
Annulation d'une transaction
Création des points de consistance
Avec pour chaque mise à jour (il peut y en avoir plusieurs par transaction)
L'identifiant de la transaction
L'identifiant de l'occurrence modifiée
L'ancienne valeur (image avant) de la donnée modifiée
La nouvelle valeur (image après) de la donnée modifiée
7.4. Les LOG BUFFERS
Nous avons vu qu’avec le FAST-COMMIT, le serveur peut valider une transaction (exécuter un COMMIT)
sans que les pages de données soient écrites physiquement dans la base. La journalisation impose
d’écrire avant toute chose dans le log file la description de la modification apportée. L’utilisation du log
buffer diffère du buffer DMF en ce que les informations qui y sont écrites vont être transférées dans le log
file sans attendre. Ceci permettant de garantir que les écritures dans la base sont représentées par des
enregistrements dans le fichier log et donc de permettre un fonctionnement totalement sécurisé du
système. Autre différence notable, alors que la taille du buffer DMF se compte en dizaine de Mo (au
minimum !), le LOG BUFFER se mesure en dizaine de ko.
7.5. Le fichier LOG DUAL
Contrairement au fichier LOG, le fichier LOG DUAL est facultatif. Son rôle est de suppléer en ligne au LOG
FILE si celui-ci vient à tomber en panne. Ces deux fichiers sont rigoureusement identiques et tout ce qui
est écrit sur le LOG est écrit en parallèle sur le LOG DUAL. En cas de problème, le système bascule sur le
LOG DUAL de manière transparente pour les utilisateurs qui peuvent donc continuer à travailler.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 31 sur 41
V 4.0
INGRES Architecture Technique INGRES
7.6. Le process d’archivage
Comme nous l’avions dit précédemment, le rôle du process d’archivage est de faire le ménage dans le
LOG FILE. La question est : comment déterminer les informations à supprimer ?
Regardons le schéma suivant :
A chaque point de consistance, le process d’archivage est activé. Il regarde quelles sont les transactions
en cours et supprime du log file tous les segments qui ne contiennent pas d’informations concernant ces
transactions (un segment : espace entre deux points de consistance).
Dans notre exemple, les transactions T7 et T6 sont actives. Le process d’archivage conservera donc les
segments à partir de [PC2 – PC3]. Tout ce qui précède a été effacé, l’espace libéré est récupéré et le BOF
(Begin Of File) du log file est avancé.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 32 sur 41
V 4.0
INGRES Architecture Technique INGRES
8. En cas de problème
8.1. Pannes du serveur de données : mécanisme de recouvrement
Le premier type de problème qui peut se présenter est la panne du serveur de données, c’est à dire du
logiciel qui traite les requêtes. Dans la même catégorie, nous pouvons également mettre le bug dans le
programme d’application (celui qui émet la requête) ou la simple volonté d’un utilisateur d’annuler une
transaction pour convenance personnelle.
Dans ces cas, un module particulier du SGBD, le serveur de recouvrement, va œuvrer afin de rétablir dans
les meilleurs délais un état cohérent de la base. Pour se faire, la règle est simple : toute transaction
validée doit être écrite sur les disques et toutes celles qui ne le sont pas (transactions interrompues par la
panne) ne doivent pas l’être. Dans le cadre d’un système utilisant le FAST-COMMIT et les écritures
asynchrones, on va se retrouver avec des données en mémoire qui devraient être écrites et des données
sur le disque qui ne devraient pas y être. Pour s’en sortir, le serveur de recouvrement va utiliser un point de
repère fondamental : le dernier point de consistance. En effet, le système est sûr du contenu physique de
la base et des transactions qui tournaient à cet instant.
Que se soit pour une transaction (dans le cas d’un arrêt du programme d’application ou du choix de
l’utilisateur d’annuler sa transaction) ou pour l’ensemble des transactions (dans le cas d’un arrêt du serveur
de données), la technique est toujours la même. Nous allons étudier dans le schéma suivant les différents
cas possibles.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 33 sur 41
V 4.0
INGRES Architecture Technique INGRES
Le serveur de recouvrement va d'abord déterminer quelles sont les transactions qui ont été validées avant
la panne (dans le jargon, on parle de transactions gagnantes) et celles qui étaient actives au moment de la
panne (perdantes). Ce qu’il faut bien voir, c’est que l’utilisateur qui a reçu confirmation que sa transaction
s’est terminée correctement, n’a pas à subir de désagrément du au principe du FAST-COMMIT et des
écritures asynchrones.
Pour lui transaction validée = données écrites physiquement.
En parcourant le LOG vers l'avant à partir du dernier point de consistance, le serveur de recouvrement va
trouver les informations utiles pour remettre la base en état cohérent. Pour cela, il lui faudra finir le travail
des transactions gagnantes et annuler celui des transactions interrompues par la panne.
Regardons nos cinq transactions :
T1, gagnante : Validée avant le point de consistance, toutes les modifications ont été écrites dans la base.
Le serveur de recouvrement n'a rien à faire.
T2, gagnante : Au moment du point de consistance, la transaction T2 n'est pas terminée, mais les
informations contenues dans le journal indiquent qu'elle sera validée. Seule certitude, une valeur
intermédiaire a été écrite physiquement au moment du dernier point de consistance. Le serveur de
recouvrement va donc refaire les actions de T2 mémorisées dans le journal à partir du point de
consistance afin de pouvoir la valider.
T3, perdante : Au moment du point de consistance, la transaction T3 n'est pas terminée et les informations
contenues dans le journal indiquent qu'elle ne sera pas validée avant la panne. Il faut donc annuler la
transaction c'est-à-dire que toutes les modifications écrites au moment du dernier point de consistance par
T3 doivent être annulées. Cela nécessite un parcours à l'envers du journal : pour chaque modification faite,
il faut revenir à l'ancienne valeur en appliquant les ‘images avant’ et ceci jusqu'au début de la transaction
T3.
T4, gagnante : Pour l'utilisateur qui a lancé T4, sa transaction est validée. Malheureusement, les
informations n'ont pas encore été écrites dans la base. Le serveur de recouvrement va donc refaire le
travail de T4 en appliquant les ‘images après’ correspondantes du journal de transactions.
T5, perdante : Pour l'utilisateur qui a lancé T5, sa transaction s'est terminée anormalement, mais comme
aucune écriture n’a été réalisée dans la base, le serveur de recouvrement va tout simplement ignorer cette
transaction.
Quand toutes les transactions présentes entre le dernier point de consistance et le moment de la panne
ont été traitées, le serveur de recouvrement pose un point de consistance (il provoque ainsi l’écriture
physique de données qui sont toutes cohérentes !). Les transactions annulées font l'objet d'un message
d'erreur vers les utilisateurs ou applications concernées.
Notons que sans les points de consistance le serveur de recouvrement devrait traiter tout le fichier LOG, ce
qui serait bien évidemment plus long. Ce qui nous conforte dans l’idée que la fréquence des points de
consistance influe directement sur la rapidité du recouvrement dans ce type de panne.
8.2. Panne du disque : sauvegarde et archivage
Même si cela n’arrive pas souvent, une panne des disques sur lesquels sont stockées les bases (style
atterrissage de tête) peut survenir et les rendre inutilisables.
En matière de sécurité des données, nous avons tous la très bonne habitude d’effectuer régulièrement des
sauvegardes. Tout SGBD digne de ce nom propose un ensemble de mécanismes permettant la mise en
œuvre des sauvegardes. Charge à l’administrateur de définir sa stratégie qui découle directement de la
philosophie de l’entreprise.
Si le disque est détruit, les données sont perdues. Il faudra donc recharger une copie de la sauvegarde la
plus récente. Imaginons qu’une sauvegarde est réalisée tous les matins à 7h00 et que la panne survienne
DMSI/ANALYSE/MST du jj/10/OO ATI Page 34 sur 41
V 4.0
INGRES Architecture Technique INGRES
à 16h00. En rechargeant la sauvegarde de 7h00 (que l’on appelle sauvegarde statique), tout le travail
effectué entre la sauvegarde et la panne est définitivement perdu. Dans le meilleur des cas, les utilisateurs
auraient à refaire par eux-mêmes le travail perdu. Dans le pire des cas, ce procédé ‘manuel’ n’est même
pas envisageable (trop long, trop cher, trop complexe…) et l’entreprise aura du mal à se relever de cet
accident. Parfois, dans le cas où les données évoluent vraiment très peu, la sauvegarde statique est
suffisante. Dans tous les autres cas (les plus courants) cette situation n’est pas viable.
Le SGBD CA-OpenIngres, comme d’autres, propose une solution technique remarquable : l’archivage du
log file.
Lorsque le process d’archivage supprime les informations inutiles du log file (c’est-à-dire, rappelons le,
celles qui concernent les transactions terminées), il les enregistre dans des fichiers spéciaux (les fichiers
d’archives). Entre deux sauvegardes statiques, le système crée un fichier d’archives. La combinaison de la
sauvegarde statique et du fichier d’archives permet non seulement de recharger la sauvegarde mais aussi
de refaire automatiquement le travail perdu. Pendant le temps que dure la remise en état de la base, les
utilisateurs ne seront pas autorisés à se connecter, mais c’est un moindre mal, puisqu’ils auront la certitude
de récupérer les données dans l’état le plus récent possible. Seules les transactions en cours au moment
de la panne seront perdues.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 35 sur 41
V 4.0
INGRES Architecture Technique INGRES
9. Gestion des accès concurrents
9.1. Pourquoi ?
Dans un système d'information fondé sur les bases de données, plusieurs usagers vont se partager la
même base. Partager, c'est-à-dire vouloir accéder à la même donnée au même moment. A titre d'exemple,
citons le système de réservation de billet de train. Il s'agit de gérer des dizaines de millions d'octets
d'information et des centaines de transactions par seconde. On comprend facilement qu'il faut éviter de
réserver deux (ou plusieurs) fois la même place. La nécessité de mettre en place un système pour gérer
les conflits que pourrait engendrer la concurrence d'accès apparaît évidente.
9.2. Sans verrous, que se passerait-il ?
Dans les deux exemples suivants, on considère qu'il n'y a pas de mécanisme permettant de gérer les
accès concurrents.
Un premier exemple est celui de l'écriture perdue.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 36 sur 41
V 4.0
INGRES Architecture Technique INGRES
Ici, l'écriture effectuée par la transaction 2 écrase celle faite par la transaction 1. En effet, la valeur finale
après une exécution correcte des transactions aurait dû être A = A - n + m. Or, elle sera dans notre
exemple de A = A + m puisque la transaction 2 utilise la valeur initiale de A, avant que la modification
apportée par la transaction 1 ait été enregistrée.
Un deuxième exemple, le cas de la lecture incohérente.
A l'inverse du cas précédent, la transaction 2 utilise bien la valeur modifiée par la transaction T1 pour
effectuer sa mise à jour. Tout serait pour le mieux (on aurait bien A = A - n + m) mais, par malchance, la
transaction 1 est annulée. C'est-à-dire que l'opération A = A - n est invalidée et de ce fait, la transaction 2
utilise une valeur incohérente de A.
En fait, pour le bonheur de tout le monde, il aurait fallu que tout se passe comme si les transactions 1 et 2
s'exécutaient de manière séquentielle. On appelle cela la sérialisation des transactions. Les SGBD dignes
de ce nom doivent garantir cette fonction.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 37 sur 41
V 4.0
INGRES Architecture Technique INGRES
CA-OpenIngres met en œuvre un principe de verrouillage pour résoudre ce problème. Cette méthode est
basée sur les règles suivantes :
Pendant que je lis une information, personne ne doit pouvoir la modifier
Pendant que je modifie une information, personne ne doit pouvoir y accéder.
Pendant que je lis une information, d'autres peuvent la lire en même temps.
9.3. Comment ?
Le SGBD, responsable de la gestion des accès concurrents, va devoir se débrouiller pour que tout se
passe bien. Il va donc appliquer une politique de verrouillage très simple :
LECTURE Verrou partagé (SHARED LOCK)
MISE A JOUR Verrou exclusif (EXCLUSIVE LOCK)
Lorsqu'une transaction veut mettre à jour une donnée, elle doit d'abord poser un verrou
exclusif (exclusive lock)
Lorsqu'une transaction veut lire une donnée, elle doit d'abord poser un verrou partagé
(shared lock)
On ne peut pas poser de verrou exclusif sur une donnée déjà verrouillée On ne peut
pas modifier une donnée qui est lue par un autre utilisateur
On ne peut pas poser de verrou partagé sur une donnée verrouillée exclusivement On
ne peut pas lire une donnée qui est mise à jour par un autre utilisateur.
On peut poser un verrou partagé sur une donnée ayant déjà un verrou partagé Plusieurs
utilisateurs peuvent lirent simultanément la donnée.
Si une transaction doit poser un verrou et qu'elle ne peut pas, elle attend (par défaut
indéfiniment, mais ce temps d'attente est, heureusement, paramétrable).
Lorsque la transaction se termine, elle libère les verrous.
9.4. Où ?
Dans un souci de performances, il faut cibler au plus juste la quantité d'informations verrouillée. Pour cela,
le système offre la possibilité de placer des verrous à plusieurs niveaux :
Au niveau de la base, ce qui est impensable en mode de production puisque cela va induire de très fortes
pertes de performances dans le cas de mises à jour faites par de nombreux utilisateurs. Toutefois, ce
niveau de verrouillage peut être utilisé par l'administrateur pour certaines opérations particulières.
Au niveau de la table, ce qui implique que toute une table sera verrouillée pour un seul utilisateur quel
que soit le nombre d'occurrences qu'il utilise.
Au niveau de la page de donnée, c'est le niveau de verrouillage le plus fin chez CA-OpenIngres. Seule
une partie des données de la table, celles contenues dans la même page que l'occurrence utilisée, sera
verrouillée.
Au niveau de l’occurrence, pour les dernières versions des SGBDR. Cette technique est très gourmande
en ressource et nécessite de grosses puissances de calcul.
Toutefois, en fixant à 1 le nombre d’occurrences par page, il est possible de simuler un verrouillage au
niveau occurrence à moindre coût (il faudra toutefois prévoir un espace disque beaucoup plus grand).
DMSI/ANALYSE/MST du jj/10/OO ATI Page 38 sur 41
V 4.0
INGRES Architecture Technique INGRES
Le système de verrouillage de CA-OpenIngres pose par défaut les verrous au niveau page. Toutefois, s'il
estime avant son exécution qu'une requête va verrouiller un nombre important de pages ou si en cours
d'utilisation le nombre de pages verrouillées augmente, il peut faire évoluer le verrouillage au niveau table.
C'est ce qu'on appelle l'escalade du verrouillage. Le nombre de pages maximum autorisé avant l'escalade
est contenu dans la variable maxlocks qui vaut 10 par défaut et peut être modifié.
L'escalade au niveau table pourra se faire, par exemple, lorsque la requête n'est pas assez restrictive (pas
de clause where dans la commande SQL).
9.5. Le DEAD LOCK
Une mauvaise utilisation des possibilités des SGBD (structures des bases ou conception des transactions)
peut aboutir à ce que le système de verrous soit perturbé.
Prenons un exemple.
Que se passe-t-il ?
L'utilisateur 1 pose un verrou partagé sur la table employé (niveau table car non restrictive).
DMSI/ANALYSE/MST du jj/10/OO ATI Page 39 sur 41
V 4.0
INGRES Architecture Technique INGRES
L'utilisateur 2 pose un verrou partagé sur la table département (niveau table car non restrictive).
L'utilisateur 1 a besoin d'un verrou exclusif au niveau page sur la table département. Il doit attendre car la
table est verrouillée.
L'utilisateur 2 a besoin d'un verrou exclusif au niveau page sur la table employé. Il doit attendre car la table
est verrouillée.
L'utilisateur 1 attend donc que l'utilisateur 2 libère ses verrous, ce qu'il ne pourra faire que lorsqu'il aura
terminé son travail, ce qu'il ne peut pas faire, puisqu'il attend la table bloquée par l'utilisateur 1 qui attend
que l'utilisateur 2 … BLOQUAGE !
La cause principale est un mauvais découpage des transactions. Les verrous partagés posés pour les
select auraient du être libérés avant l'exécution des requêtes de mises à jour.
Prenons un autre exemple.
L'utilisateur 1 commence à accumuler les verrous exclusifs au niveau page sur la table employé.
DMSI/ANALYSE/MST du jj/10/OO ATI Page 40 sur 41
V 4.0
INGRES Architecture Technique INGRES
L'utilisateur 2 commence à accumuler les verrous exclusifs au niveau page sur la table employé.
L'utilisateur 1 a besoin d'accéder à des données contenues dans une page verrouillée par l'utilisateur 2.
L'utilisateur 1 attend la fin de la transaction de l'utilisateur 2 et le déblocage des verrous de celui-ci.
L'utilisateur 2 a besoin d'accéder à des données contenues dans une page verrouillée par l'utilisateur 1.
L'utilisateur 2 attend la fin de la transaction de l'utilisateur 1 et le déblocage des verrous de celui-ci.
BLOCAGE ! Une solution consisterait ici à forcer un verrouillage au niveau table dès le début de la
transaction, ou de découper physiquement la table en domaine si cela correspond à une règle de travail de
l’entreprise.
Dans ces cas de deadlock, l'attente pourrait être infinie. Mais le système au bout d'un certain temps va
décider d'annuler une des deux transactions. L'utilisateur lésé sera averti.
10. En guise de conclusion
Nous avons découvert au travers de CA-OpenIngres les grandes lignes de l’architecture des SGBD
Relationnels. D’autres SGBD existent sur le marché, celui-ci n’était qu’un (bon) exemple. Même si
certaines divergences peuvent apparaître d’un produit à l’autre, la philosophie et les concepts sont
communs à tous les vrais SGBDR.
Enfin, si tous ces produits proposent de nombreux outils et répondent aux attentes des entreprises en
matière de système d’information, n’oublions pas le rôle capital du personnage clé qu’est l’administrateur
du SGBD qui devra surveiller, régler et optimiser le fonctionnement de l’ensemble.
Mais ceci est une autre histoire…
DMSI/ANALYSE/MST du jj/10/OO ATI Page 41 sur 41
V 4.0
You might also like
- BE Formation MyReport-BE-BuilderDocument200 pagesBE Formation MyReport-BE-BuilderDeyilon Aubin100% (1)
- Cours de Route Eng. BOUTCHEKO Bernard - Copie PDFDocument249 pagesCours de Route Eng. BOUTCHEKO Bernard - Copie PDFJotchap Martial100% (3)
- Audio NumeriqueDocument49 pagesAudio Numeriquebobrac100% (4)
- Distillateur SolaireDocument67 pagesDistillateur SolaireHifdi AyaNo ratings yet
- Architecture Du WebDocument77 pagesArchitecture Du WebTitou Imene LolaNo ratings yet
- Miage It PDFDocument41 pagesMiage It PDFalexandreNo ratings yet
- OMAX - Benjamin LevyDocument57 pagesOMAX - Benjamin LevydavidNo ratings yet
- P-2002 Yvette Ossele AtanganaDocument203 pagesP-2002 Yvette Ossele AtanganaReghis OussamaNo ratings yet
- Scdsci M 2011 Essaid HasnaDocument43 pagesScdsci M 2011 Essaid HasnasaadNo ratings yet
- Etude Comparative de Dimensionnement D Une Structure Metallique Entre Les Regles CM66 Et L Eurocode3 PDFDocument80 pagesEtude Comparative de Dimensionnement D Une Structure Metallique Entre Les Regles CM66 Et L Eurocode3 PDFYoussef Serguini100% (1)
- Modèle Rapport PFC-convertiDocument74 pagesModèle Rapport PFC-convertiYounes Boucherif100% (1)
- Tfe Rosati Final CompressedDocument69 pagesTfe Rosati Final CompressedAbdelrrazagElghoulNo ratings yet
- Silkan Polycopie CompilationDocument54 pagesSilkan Polycopie CompilationYassine HansaliNo ratings yet
- CoursAccess Id686Document48 pagesCoursAccess Id686receipt logNo ratings yet
- Chapitre EbxmlDocument33 pagesChapitre Ebxmlrostom boudjanouiaNo ratings yet
- Rapport-AGV-YAZAKI-suivis Du 03-08Document60 pagesRapport-AGV-YAZAKI-suivis Du 03-08Bachir El AbbasNo ratings yet
- Poly MTR 2.0 PDFDocument90 pagesPoly MTR 2.0 PDFChokri HajsalahNo ratings yet
- COURS DE RESISTANCE DES MATERIAUX Complément2 EIPCDocument78 pagesCOURS DE RESISTANCE DES MATERIAUX Complément2 EIPCMouhammad DiomandeNo ratings yet
- ClientLeger WYSEDocument66 pagesClientLeger WYSEvirus_zotopNo ratings yet
- AMETI Rapport 2 CorrectUpdate25022023Document28 pagesAMETI Rapport 2 CorrectUpdate25022023Haleem OlawaleNo ratings yet
- FM Global 2.0 FR EdDocument119 pagesFM Global 2.0 FR EdMichael Jeremie-vernaireNo ratings yet
- Initiation Aux Réseaux Informatiques s5 PDFDocument53 pagesInitiation Aux Réseaux Informatiques s5 PDFSoukaina EL Bakkali100% (1)
- Unity ProDocument54 pagesUnity ProEdwin RTNo ratings yet
- Rapport An Nuel 2017 Art PDocument48 pagesRapport An Nuel 2017 Art PMoussa SoumanaNo ratings yet
- Étude Comparative de Dimensionnement D'une Structure Métallique, Entre Les Règles Cm66 Et L Eurocode3 ADocument80 pagesÉtude Comparative de Dimensionnement D'une Structure Métallique, Entre Les Règles Cm66 Et L Eurocode3 AyoussefNo ratings yet
- RCI. Réseaux Et Communication Industrielle. TD N 1Document87 pagesRCI. Réseaux Et Communication Industrielle. TD N 1Sara Ibn El AhracheNo ratings yet
- RapportDocument60 pagesRapportslim yaichNo ratings yet
- Rapport Du Projet de Fin D'études: Reconnaissance Des Personnes Par Le Visage Dans Des Séquences VidéoDocument46 pagesRapport Du Projet de Fin D'études: Reconnaissance Des Personnes Par Le Visage Dans Des Séquences Vidéoaminehadouch001No ratings yet
- Mémoire de Fin D'études de Master: Conception Et Réalisation D'un Système D'automatisation D'un Parking D'automobileDocument62 pagesMémoire de Fin D'études de Master: Conception Et Réalisation D'un Système D'automatisation D'un Parking D'automobileMOHAMED BOUZEBRANo ratings yet
- courspic_v1.1Document14 pagescourspic_v1.1bouchenebNo ratings yet
- Conception Et Réalisation D'une ApplicationDocument51 pagesConception Et Réalisation D'une ApplicationAbdallah Ghannam100% (1)
- Mémoire MasterDocument86 pagesMémoire MasterMohammed SeddikiNo ratings yet
- RapportDocument32 pagesRapportMohamed Ali MsaadiaNo ratings yet
- Sam1a Coursv11Document66 pagesSam1a Coursv11طريق الرشادNo ratings yet
- M104 - TEI - Réalisation Des Croquis Et Des SchémasDocument130 pagesM104 - TEI - Réalisation Des Croquis Et Des SchémaslatifaerraidyNo ratings yet
- LAGA 67281-12-fr-2005Document72 pagesLAGA 67281-12-fr-2005SupertazNo ratings yet
- Hasnfra 17 PDF 267Document83 pagesHasnfra 17 PDF 267Brahim EchchaitNo ratings yet
- Stage Ing HattabDocument39 pagesStage Ing HattabElhattab FethiNo ratings yet
- Étude Comparative de Dimensionnement D Une Structure Métallique, Entre Les Règles CM66 Et L Eurocode3 PDFDocument80 pagesÉtude Comparative de Dimensionnement D Une Structure Métallique, Entre Les Règles CM66 Et L Eurocode3 PDFAmine Hadri67% (6)
- Charles KouadioDocument32 pagesCharles Kouadiocharleskouadio nguessanNo ratings yet
- Etude Texturale Et Fractale Des Echos RadarDocument100 pagesEtude Texturale Et Fractale Des Echos RadarHachemi BheNo ratings yet
- Cours Etude de ConceptionDocument60 pagesCours Etude de ConceptionMdzayd EL FahimeNo ratings yet
- Cours Etude de Conception MECA2Document60 pagesCours Etude de Conception MECA2Benamara Abdelmajid100% (1)
- Application Web Pour La Gestio - LARGO Salma - 3531Document50 pagesApplication Web Pour La Gestio - LARGO Salma - 3531Jaouad EL BounaniNo ratings yet
- TP RDM2Document30 pagesTP RDM2Emir KaMounNo ratings yet
- Conception Assistee Par Ordinateur PDFDocument44 pagesConception Assistee Par Ordinateur PDFMohammed AlaouiNo ratings yet
- NkPres - ArchitAvance Parallel Virtual - 16 20fev16Document186 pagesNkPres - ArchitAvance Parallel Virtual - 16 20fev16Marcellin NKENLIFACKNo ratings yet
- PTD3 - Travaux Dirigés-JavaDocument43 pagesPTD3 - Travaux Dirigés-JavanouhaylaacharqyNo ratings yet
- Mecanique Générale PDFDocument118 pagesMecanique Générale PDFfounè diassana100% (1)
- DELTA RAPPORT (1) IkramDocument41 pagesDELTA RAPPORT (1) IkramOumnia MimitaNo ratings yet
- Du crayon à l'imprimante: Alphabétisation, micro-informatique et sémiotiqueFrom EverandDu crayon à l'imprimante: Alphabétisation, micro-informatique et sémiotiqueNo ratings yet
- Traité d'économétrie financière: Modélisation financièreFrom EverandTraité d'économétrie financière: Modélisation financièreNo ratings yet
- Reporting pilier 3 de solvabilité II: Guide pour la production des QRTFrom EverandReporting pilier 3 de solvabilité II: Guide pour la production des QRTNo ratings yet
- HueDocument1 pageHuestrideworldNo ratings yet
- Mode D'emploi Du Mamiya 7IIDocument21 pagesMode D'emploi Du Mamiya 7IIstrideworldNo ratings yet
- Idies Rapport 2013 BATDocument34 pagesIdies Rapport 2013 BATAltercoNo ratings yet
- ChineDocument2 pagesChinestrideworldNo ratings yet
- Stratégies Groupes SuiteDocument10 pagesStratégies Groupes Suitestrideworld100% (1)
- FRS1073 4 A 0413 FRA /AFP-RF83 Médias-Presse-AFP-Internet-PiratageDocument2 pagesFRS1073 4 A 0413 FRA /AFP-RF83 Médias-Presse-AFP-Internet-PiratagestrideworldNo ratings yet
- Ecf0413 4 PF 0318 BelDocument2 pagesEcf0413 4 PF 0318 BelstrideworldNo ratings yet
- BesancenotDocument1 pageBesancenotstrideworldNo ratings yet
- FRS0765 4 Eaf 0340 FraDocument2 pagesFRS0765 4 Eaf 0340 FrastrideworldNo ratings yet
- FRS0996 4 Fu 0316 GBRDocument2 pagesFRS0996 4 Fu 0316 GBRstrideworldNo ratings yet
- La Note Du LundiDocument2 pagesLa Note Du LundistrideworldNo ratings yet
- Stratégies GroupesDocument36 pagesStratégies GroupesstrideworldNo ratings yet
- IpadDocument2 pagesIpadstrideworldNo ratings yet
- InvisibilitéDocument2 pagesInvisibilitéstrideworldNo ratings yet
- FRS0996 4 Fu 0316 GBRDocument2 pagesFRS0996 4 Fu 0316 GBRstrideworldNo ratings yet
- Aubry Martine (V Peillon)Document2 pagesAubry Martine (V Peillon)strideworldNo ratings yet
- Présentation ADDocument17 pagesPrésentation ADstrideworld100% (1)
- Traquer Les Secrets Du Cosmos À 1700 Mètres de ProfondeurDocument3 pagesTraquer Les Secrets Du Cosmos À 1700 Mètres de ProfondeurstrideworldNo ratings yet
- Installation Serveur W2KDocument9 pagesInstallation Serveur W2Kstrideworld100% (1)
- IpsecDocument16 pagesIpsecstrideworld100% (1)
- SécurisationDocument17 pagesSécurisationstrideworld100% (1)
- SiteDocument18 pagesSitestrideworldNo ratings yet
- Présentation Windows 2000Document5 pagesPrésentation Windows 2000strideworldNo ratings yet
- Infrastructure Clé PubliqueDocument25 pagesInfrastructure Clé Publiquestrideworld100% (1)
- Dns 2Document21 pagesDns 2strideworld100% (1)
- Gestion LogicielsDocument23 pagesGestion LogicielsstrideworldNo ratings yet
- DNS 1Document22 pagesDNS 1strideworld100% (2)
- DéléguationDocument25 pagesDéléguationstrideworld100% (1)
- Utilisation de DFS Pour Partager Les Ressources DisqueDocument9 pagesUtilisation de DFS Pour Partager Les Ressources Disquestrideworld100% (2)
- Crypt AgeDocument14 pagesCrypt Agestrideworld100% (1)
- Output 5.TextMarkDocument14 pagesOutput 5.TextMarkSolhi EssaidNo ratings yet
- G3ei 2015-2016Document5 pagesG3ei 2015-2016Yahya ElamraniNo ratings yet
- Chapitre 3 Les Dimensions Temporelle Et Budgétaire de La Gestion de ProjetDocument38 pagesChapitre 3 Les Dimensions Temporelle Et Budgétaire de La Gestion de Projetzabala kamalaNo ratings yet
- TP VoIPDocument14 pagesTP VoIPIsmailovic ChernicovNo ratings yet
- Linux & GreenBow IPsec VPN Configuration (FR)Document15 pagesLinux & GreenBow IPsec VPN Configuration (FR)greenbow100% (1)
- Plan Du Cours - Géologie GénéraleDocument3 pagesPlan Du Cours - Géologie GénéraleYasser GéologueNo ratings yet
- Batisexpo Batimatec 2021 WebDocument16 pagesBatisexpo Batimatec 2021 WebDj@melNo ratings yet
- Chapitre 6 - Liants Hydrauliques - Partie 1Document49 pagesChapitre 6 - Liants Hydrauliques - Partie 1Abderrahman ZAMOUCHINo ratings yet
- Le Diagnostic Et Sa Démarche 1 - Généralités:: Stratégies de MaintenanceDocument21 pagesLe Diagnostic Et Sa Démarche 1 - Généralités:: Stratégies de Maintenancerabbaj100% (1)
- Résolution Examen 2016 PDFDocument11 pagesRésolution Examen 2016 PDFDominoHevyNo ratings yet
- Diagramme 20psychrom c3 A9trique 202-3Document12 pagesDiagramme 20psychrom c3 A9trique 202-3El Hadj Abdoulaye SECKu.No ratings yet
- tp001 - MuseureDocument8 pagestp001 - MuseureCLUB-IBDAA-ME Univ MilaNo ratings yet
- Cours HorlogeDocument49 pagesCours HorlogepierreNo ratings yet
- Tamimount AmineDocument86 pagesTamimount AmineZu Yad100% (1)
- Technique GSMDocument13 pagesTechnique GSMSiddo NajimNo ratings yet
- 9624 Fiche Sequence Ci Maintenance Diagnostic Et Mise Au Point Des Elements de Liaison Au SolDocument3 pages9624 Fiche Sequence Ci Maintenance Diagnostic Et Mise Au Point Des Elements de Liaison Au SolKarim AzzNo ratings yet
- 2 TavDocument58 pages2 TavAya SaidiNo ratings yet
- 88-4 Modelisation de L'interactionDocument9 pages88-4 Modelisation de L'interactionFikar KassimNo ratings yet
- Presentation Badihou VF 1Document15 pagesPresentation Badihou VF 1Mamadou ThilloNo ratings yet
- Filets Et ChaineDocument22 pagesFilets Et ChaineMohamed RaouyNo ratings yet
- Fiche Mission Configuration Utm SophosDocument14 pagesFiche Mission Configuration Utm Sophosapi-352422048No ratings yet
- TD Chap2 ElectroniqueDocument5 pagesTD Chap2 ElectroniqueWael MaatougNo ratings yet
- Aspersor Maxi-Paw Rain Bird Instrucciones.Document1 pageAspersor Maxi-Paw Rain Bird Instrucciones.A M P RoaNo ratings yet
- Securité Chap5Document3 pagesSecurité Chap5Lilya ChaatalNo ratings yet
- Assainissement02 130606125811 Phpapp01Document75 pagesAssainissement02 130606125811 Phpapp01Benhmaida HananNo ratings yet
- Iso 23277 2015Document9 pagesIso 23277 2015Thomas Kirov AlbertNo ratings yet
- Béton Précontraint - Techniques de Mise en Oeuvre PDFDocument34 pagesBéton Précontraint - Techniques de Mise en Oeuvre PDFNacer Assam75% (4)
- CfguklllllnbbnDocument24 pagesCfguklllllnbbnXaymae75% (4)
- Wa0006.Document1 pageWa0006.Nabil NabilNo ratings yet