You might also like
- MenuDocument5 pagesMenuVIJAYPUTRANo ratings yet
- Projects With Microcontrollers And PICCFrom EverandProjects With Microcontrollers And PICCRating: 5 out of 5 stars5/5 (1)
- Method Statement FINALDocument61 pagesMethod Statement FINALshareyhou67% (3)
- Certification Authorities Software Team (CAST) Position Paper CAST-2Document7 pagesCertification Authorities Software Team (CAST) Position Paper CAST-2VIJAYPUTRANo ratings yet
- ADC TutorialDocument17 pagesADC TutorialNagabhushanam KoduriNo ratings yet
- Employee of The Month.Document2 pagesEmployee of The Month.munyekiNo ratings yet
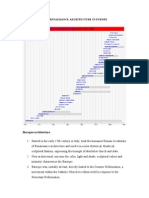
- Post Renaissance Architecture in EuropeDocument10 pagesPost Renaissance Architecture in Europekali_007No ratings yet
- Experiment 10 Analog-to-Digital Converter (ADC) in PIC18F452 ObjectiveDocument10 pagesExperiment 10 Analog-to-Digital Converter (ADC) in PIC18F452 Objectivehira NawazNo ratings yet
- Arduino Measurements in Science: Advanced Techniques and Data ProjectsFrom EverandArduino Measurements in Science: Advanced Techniques and Data ProjectsNo ratings yet
- SCIENCE 11 WEEK 6c - Endogenic ProcessDocument57 pagesSCIENCE 11 WEEK 6c - Endogenic ProcessChristine CayosaNo ratings yet
- Collecting, Analyzing, & Feeding Back DiagnosticDocument12 pagesCollecting, Analyzing, & Feeding Back DiagnosticCaroline Mariae TuquibNo ratings yet
- C++ Chapter 1 - 6Document16 pagesC++ Chapter 1 - 6Jose Silvas Corona67% (3)
- Pic PC InterfacedDocument16 pagesPic PC Interfacedabceln100% (3)
- USB ThermometerDocument40 pagesUSB ThermometerTheodøros D' SpectrøømNo ratings yet
- Data Conversion CCTSDocument5 pagesData Conversion CCTSDavis AllanNo ratings yet
- Code Optimization Word-Wide Optimization Mixing C and AssemblyDocument13 pagesCode Optimization Word-Wide Optimization Mixing C and AssemblyJoshua DuffyNo ratings yet
- Lab 1e Fixed-Point Output Fall 2010 1e.1Document8 pagesLab 1e Fixed-Point Output Fall 2010 1e.1iky77No ratings yet
- DSPACE Procedure With MPPT ExampleDocument21 pagesDSPACE Procedure With MPPT ExampleSri SriNo ratings yet
- Experiment 10 - Lab ReportDocument11 pagesExperiment 10 - Lab ReportIntahsarNo ratings yet
- Layout Tips For 12-Bit A/D Converter Application: Getting A Good StartDocument7 pagesLayout Tips For 12-Bit A/D Converter Application: Getting A Good StartRoberto MejiaNo ratings yet
- CPR E 381x/382x Lab11aDocument10 pagesCPR E 381x/382x Lab11aHelenNo ratings yet
- ADCDocument18 pagesADCYogha Satria LaksanaNo ratings yet
- TMS320F2812-Analogue To Digital ConverterDocument26 pagesTMS320F2812-Analogue To Digital ConverterPantech ProLabs India Pvt LtdNo ratings yet
- Flash ADC Design in ElectricDocument22 pagesFlash ADC Design in ElectricNagaraj HegdeNo ratings yet
- FFFDocument24 pagesFFFEngr Nayyer Nayyab MalikNo ratings yet
- Embedded Micro Controller Test SolutionDocument9 pagesEmbedded Micro Controller Test SolutionalikaastridNo ratings yet
- PLEASE (NEATLY) SHOW ALL WORK! Comment All Code Well. Do Not Make TheDocument4 pagesPLEASE (NEATLY) SHOW ALL WORK! Comment All Code Well. Do Not Make TheengshimaaNo ratings yet
- Digital Coding of Signals: ClippingDocument15 pagesDigital Coding of Signals: ClippingGurkaranjot SinghNo ratings yet
- CORDICDocument8 pagesCORDICRofaelEmilNo ratings yet
- Group5 f2c ConverterDocument5 pagesGroup5 f2c Convertermayanksanjay007No ratings yet
- Analog Interfacing: LessonDocument13 pagesAnalog Interfacing: LessonSayan Kumar KhanNo ratings yet
- PIC Analog To Digital Converter TutorialDocument5 pagesPIC Analog To Digital Converter TutorialSharath MunduriNo ratings yet
- Dual Slope ADC DesignDocument10 pagesDual Slope ADC DesignMoHaMMeD HaLaByNo ratings yet
- ADC Module: VoltageDocument5 pagesADC Module: VoltageAmmar AlkindyNo ratings yet
- Berkes - Interfacing Exp ArrangementDocument20 pagesBerkes - Interfacing Exp ArrangementAditya K NNo ratings yet
- Proton Compiler ManualDocument10 pagesProton Compiler ManualAlexis AldásNo ratings yet
- AssignmentDocument4 pagesAssignmentAnonymous ne1h1Vk140No ratings yet
- Fixed Point Routines - 00617bDocument383 pagesFixed Point Routines - 00617bGuillermo Hernandez100% (1)
- Adc Lab Pic18Document23 pagesAdc Lab Pic18Bolarinwa Joseph100% (1)
- Microcontrollers Lab ManualDocument37 pagesMicrocontrollers Lab ManualArati DazNo ratings yet
- Rotary EncoderDocument6 pagesRotary EncoderalesysNo ratings yet
- Project Ele 447Document29 pagesProject Ele 447Narendra AchariNo ratings yet
- Chapter2-Microcontroller Architecture & Assembly Language Pt3Document36 pagesChapter2-Microcontroller Architecture & Assembly Language Pt3adamwaiz100% (2)
- Inter Grating AdcDocument6 pagesInter Grating AdcthắngNo ratings yet
- Restricted Earth Fault Protection - 1Document17 pagesRestricted Earth Fault Protection - 1Ahetesham MullaNo ratings yet
- ADC Program For LPC2138Document8 pagesADC Program For LPC2138hypernuclide100% (1)
- Applications of Handshake ModeDocument3 pagesApplications of Handshake Modevyshnu3006No ratings yet
- ArchitectureDocument112 pagesArchitectureKrishnaveni DhulipalaNo ratings yet
- BER MeterDocument8 pagesBER Metersakti prasad nandaNo ratings yet
- LCR-Meter ElektorDocument5 pagesLCR-Meter ElektorFernando VidalNo ratings yet
- Module 2 NotesDocument28 pagesModule 2 NotesKrithika KNo ratings yet
- Digital Voltmeter Using Pic MicrocontrollerDocument38 pagesDigital Voltmeter Using Pic MicrocontrollerTaramba kossiNo ratings yet
- F2833x Analogue Digital Converter: V V V D VDocument28 pagesF2833x Analogue Digital Converter: V V V D VSaiNo ratings yet
- PTI Section 9 Analog DigitalDocument14 pagesPTI Section 9 Analog Digitalchrist9088No ratings yet
- 2010 CASPER Workshop: Tutorial 4: Wideband PocoDocument16 pages2010 CASPER Workshop: Tutorial 4: Wideband PocotrabajadosNo ratings yet
- IR Sensor Based Distance Measurement SystemDocument5 pagesIR Sensor Based Distance Measurement SystemRajkeen ChamanshaikhNo ratings yet
- Analog To Digital ConvertDocument20 pagesAnalog To Digital ConvertluxiaofengNo ratings yet
- Radix-4 and Radix-8 Multiplier Using Verilog HDL: (Ijartet) Vol. 1, Issue 1, September 2014Document6 pagesRadix-4 and Radix-8 Multiplier Using Verilog HDL: (Ijartet) Vol. 1, Issue 1, September 2014RalucaJulaNo ratings yet
- Understanding Integrating ADC AN1041Document7 pagesUnderstanding Integrating ADC AN1041dileepank14No ratings yet
- FPGA Implementation of IEEE-754 Karatsuba MultiplierDocument4 pagesFPGA Implementation of IEEE-754 Karatsuba MultiplierSatyaKesavNo ratings yet
- C For PICDocument9 pagesC For PICsaudNo ratings yet
- A High-Speed Multiplication Algorithm Using Modified Partial Product Reduction TreeDocument7 pagesA High-Speed Multiplication Algorithm Using Modified Partial Product Reduction TreesrinivascbitNo ratings yet
- Adc ScalerDocument5 pagesAdc Scalermartinez_cvmNo ratings yet
- Lesson Adc PWMDocument36 pagesLesson Adc PWMDavidRubeomNo ratings yet
- A Digital Temperature Meter Using An LM35 Temperature SensorDocument10 pagesA Digital Temperature Meter Using An LM35 Temperature SensorsunpnairNo ratings yet
- Analog To Digital ConvertersDocument11 pagesAnalog To Digital Convertersمحمد ماجدNo ratings yet
- Floating Point To FixedDocument15 pagesFloating Point To Fixedcnt2sskNo ratings yet
- Dump:10Document1 pageDump:10VIJAYPUTRANo ratings yet
- LiiDocument10 pagesLiiVIJAYPUTRANo ratings yet
- L111Document49 pagesL111VIJAYPUTRANo ratings yet
- InfoDocument1 pageInfoVIJAYPUTRANo ratings yet
- Introoduction To Basic Language Art of LanguageDocument1 pageIntrooduction To Basic Language Art of LanguageVIJAYPUTRANo ratings yet
- Unix BookDocument132 pagesUnix BookVasanth100% (7)
- LanguageDocument4 pagesLanguageVIJAYPUTRANo ratings yet
- Unix BookDocument132 pagesUnix BookVasanth100% (7)
- Installing Software On Linux - Guide To Linux For BeginnersDocument4 pagesInstalling Software On Linux - Guide To Linux For BeginnersVIJAYPUTRANo ratings yet
- PRQA QAVerifyDocument4 pagesPRQA QAVerifyVIJAYPUTRANo ratings yet
- Certification Authorities Software Team (CAST) Position Paper CAST-1Document12 pagesCertification Authorities Software Team (CAST) Position Paper CAST-1VIJAYPUTRANo ratings yet
- UnivDocument3 pagesUnivVIJAYPUTRANo ratings yet
- CPP 2 PythonDocument4 pagesCPP 2 PythonNishfaan NaseerNo ratings yet
- Ban105 1.2Document26 pagesBan105 1.2VIJAYPUTRANo ratings yet
- A New Simplified Space-Vector PWM Method For Three-Level InvertersDocument6 pagesA New Simplified Space-Vector PWM Method For Three-Level InvertersVIJAYPUTRANo ratings yet
- 30 21028Document6 pages30 21028VIJAYPUTRANo ratings yet
- Teppo LuukkonenDocument32 pagesTeppo LuukkonenVIJAYPUTRANo ratings yet
- 3 XnextbifurDocument12 pages3 XnextbifurVIJAYPUTRANo ratings yet
- Triangle-Comparison Approach and Space Vector Approach To Pulsewidth Modulation in Inverter Fed DrivesDocument38 pagesTriangle-Comparison Approach and Space Vector Approach To Pulsewidth Modulation in Inverter Fed DrivesVIJAYPUTRANo ratings yet
- Virtual Human Hand: Autonomous Grasping Strategy: Esteban Pe Na PitarchDocument26 pagesVirtual Human Hand: Autonomous Grasping Strategy: Esteban Pe Na PitarchVIJAYPUTRANo ratings yet
- Some Useful Linux CommandsDocument37 pagesSome Useful Linux CommandsVIJAYPUTRANo ratings yet
- Verilog PWM Switch ModelsDocument3 pagesVerilog PWM Switch ModelsVIJAYPUTRANo ratings yet
- Verilog PWM Switch Models2Document2 pagesVerilog PWM Switch Models2VIJAYPUTRANo ratings yet
- Corrections 1st Print Loop ControlDocument8 pagesCorrections 1st Print Loop ControlVIJAYPUTRANo ratings yet
- LorenzDocument2 pagesLorenzVIJAYPUTRANo ratings yet
- 00-SMPS by Christophe Basso - Table of ContentsDocument8 pages00-SMPS by Christophe Basso - Table of Contentssenkum812002No ratings yet
- Phase Margin and Quality FactorDocument7 pagesPhase Margin and Quality FactorVIJAYPUTRANo ratings yet
- Mae 342 Lecture 17Document1 pageMae 342 Lecture 17VIJAYPUTRANo ratings yet
- Physiol Toric Calculator: With Abulafia-Koch Regression FormulaDocument1 pagePhysiol Toric Calculator: With Abulafia-Koch Regression FormuladeliNo ratings yet
- PM 50 Service ManualDocument60 pagesPM 50 Service ManualLeoni AnjosNo ratings yet
- Forensic IR-UV-ALS Directional Reflected Photography Light Source Lab Equipment OR-GZP1000Document3 pagesForensic IR-UV-ALS Directional Reflected Photography Light Source Lab Equipment OR-GZP1000Zhou JoyceNo ratings yet
- Journal of Molecular LiquidsDocument11 pagesJournal of Molecular LiquidsDennys MacasNo ratings yet
- Sharat Babu Digumarti Vs State, Govt. of NCT of Delhi (Bazee - Com Case, Appeal) - Information Technology ActDocument17 pagesSharat Babu Digumarti Vs State, Govt. of NCT of Delhi (Bazee - Com Case, Appeal) - Information Technology ActRavish Rana100% (1)
- Payment of Wages 1936Document4 pagesPayment of Wages 1936Anand ReddyNo ratings yet
- Ford Focus MK2 Headlight Switch Wiring DiagramDocument1 pageFord Focus MK2 Headlight Switch Wiring DiagramAdam TNo ratings yet
- Actron Vismin ReportDocument19 pagesActron Vismin ReportSirhc OyagNo ratings yet
- Current Harmonics: Electric Power System Power QualityDocument3 pagesCurrent Harmonics: Electric Power System Power QualityAlliver SapitulaNo ratings yet
- Standard BMW PDFDocument19 pagesStandard BMW PDFIna IoanaNo ratings yet
- Final SEC Judgment As To Defendant Michael Brauser 3.6.20Document14 pagesFinal SEC Judgment As To Defendant Michael Brauser 3.6.20Teri BuhlNo ratings yet
- SL Generator Ultrasunete RincoDocument2 pagesSL Generator Ultrasunete RincoDariaNo ratings yet
- Creating A Research Space (C.A.R.S.) ModelDocument5 pagesCreating A Research Space (C.A.R.S.) ModelNazwa MustikaNo ratings yet
- Vest3000mkii TurntableDocument16 pagesVest3000mkii TurntableElkin BabiloniaNo ratings yet
- DHA - Jebel Ali Emergency Centre + RevisedDocument5 pagesDHA - Jebel Ali Emergency Centre + RevisedJam EsNo ratings yet
- Population Second TermDocument2 pagesPopulation Second Termlubna imranNo ratings yet
- LU 5.1 ElectrochemistryDocument32 pagesLU 5.1 ElectrochemistryNurAkila Mohd YasirNo ratings yet
- Advanced Herd Health Management, Sanitation and HygieneDocument28 pagesAdvanced Herd Health Management, Sanitation and Hygienejane entunaNo ratings yet
- Tata NanoDocument25 pagesTata Nanop01p100% (1)
- HR Practices in Public Sector Organisations: (A Study On APDDCF LTD.)Document28 pagesHR Practices in Public Sector Organisations: (A Study On APDDCF LTD.)praffulNo ratings yet
- Cln4u Task Prisons RubricsDocument2 pagesCln4u Task Prisons RubricsJordiBdMNo ratings yet
- Institutions and StrategyDocument28 pagesInstitutions and StrategyFatin Fatin Atiqah100% (1)
- Visi RuleDocument6 pagesVisi RuleBruce HerreraNo ratings yet
- Agrinome For Breeding - Glossary List For Mutual Understandings v0.3 - 040319Document7 pagesAgrinome For Breeding - Glossary List For Mutual Understandings v0.3 - 040319mustakim mohamadNo ratings yet
- Pogon Lifta MRL PDFDocument128 pagesPogon Lifta MRL PDFMašinsko ProjektovanjeNo ratings yet