You might also like
- Economics Quick Revision MatrialDocument33 pagesEconomics Quick Revision MatrialSiddhi AgarwalNo ratings yet
- Question Bank: Short Answer QuestionsDocument29 pagesQuestion Bank: Short Answer QuestionsPayal GoswamiNo ratings yet
- Last Minute Revision Study Material Economics Class XIIDocument21 pagesLast Minute Revision Study Material Economics Class XIIHarsh Sethia100% (1)
- Cbse Sample Papers For Class 12 Economics With Solution PDFDocument19 pagesCbse Sample Papers For Class 12 Economics With Solution PDFniharikaNo ratings yet
- EconomicsDocument90 pagesEconomicsapi-514969128No ratings yet
- CBSE Supporting Material Economics Class 12 2013Document152 pagesCBSE Supporting Material Economics Class 12 2013ChandraMENo ratings yet
- CBSE Class 9 Economics Chapter 2 Notes - People As ResourceDocument5 pagesCBSE Class 9 Economics Chapter 2 Notes - People As ResourceDeepak GuptaNo ratings yet
- 12 SM EconomicsDocument209 pages12 SM EconomicsTechnical GamingNo ratings yet
- Subhash Dey's IED XII 2024-25 (Sample PDFDocument38 pagesSubhash Dey's IED XII 2024-25 (Sample PDFAnjana Arun ANo ratings yet
- CBSE XII Economics NotesDocument165 pagesCBSE XII Economics NoteschehalNo ratings yet
- Balance of PaymentDocument26 pagesBalance of Paymentnitan4zaara100% (3)
- Changes in CBSE Economics Paper by Priti ManglaDocument9 pagesChanges in CBSE Economics Paper by Priti ManglaBook Spaces100% (4)
- Economy TestDocument57 pagesEconomy TestNelson David Bolivar ArdilaNo ratings yet
- CA Foundation MTP 2020 Paper 4 QuesDocument15 pagesCA Foundation MTP 2020 Paper 4 QuesKanchan AggarwalNo ratings yet
- ECONOMICS PROJECT SECTOR CONTRIBUTIONSDocument37 pagesECONOMICS PROJECT SECTOR CONTRIBUTIONSSkottayyNo ratings yet
- IED 3. AR & CBQ New Economic PolicyDocument43 pagesIED 3. AR & CBQ New Economic Policysayooj tvNo ratings yet
- Inclusive GrowthDocument45 pagesInclusive GrowthPRUDHVINo ratings yet
- Management Concepts, Functions and ImportanceDocument62 pagesManagement Concepts, Functions and ImportanceBhagya aggarwalNo ratings yet
- Xii Economics Excellence Series, Ziet BBSRDocument296 pagesXii Economics Excellence Series, Ziet BBSRnagartanishq2No ratings yet
- Teaching Heterodox Economics ConceptsDocument40 pagesTeaching Heterodox Economics ConceptsПетър Димитров100% (1)
- 11th STD Economics One Mark Questions in EnglishDocument35 pages11th STD Economics One Mark Questions in EnglishSelvam Lakshmanan0% (1)
- Economics Class 12 Notes, Ebook - Solved Questions For Board Exams - Free PDF DownloadDocument100 pagesEconomics Class 12 Notes, Ebook - Solved Questions For Board Exams - Free PDF DownloadRobo Buddy100% (1)
- Micro CH-2 Consumer EquilibriumDocument20 pagesMicro CH-2 Consumer EquilibriumLalitKukrejaNo ratings yet
- MANAGERIAL ECONOMICS 3 KkhsouDocument188 pagesMANAGERIAL ECONOMICS 3 KkhsouptgoNo ratings yet
- (James M. Henderson and Richard E. Quandt) Microec PDFDocument304 pages(James M. Henderson and Richard E. Quandt) Microec PDFMohammad Baqir100% (1)
- 11 Accountancy English 2020 21Document376 pages11 Accountancy English 2020 21Tanishq Bindal100% (1)
- XamIdea Economics Class 12Document457 pagesXamIdea Economics Class 12Aaditi V50% (2)
- Format - Summer Training Project Report Format.Document8 pagesFormat - Summer Training Project Report Format.vershaNo ratings yet
- Consumer's EquilibriumDocument15 pagesConsumer's Equilibriumsridharvchinni_21769100% (1)
- Domestic Territory and Normal ResidentDocument10 pagesDomestic Territory and Normal Residentnaveen kumarNo ratings yet
- T.R. Jain and V.K. Ohri Solutions For Economics CBSE Class 11 Commerce, Chapter 7 Frequency Diagrams, Histograms, Polygon and Ogive - TopperLearningDocument22 pagesT.R. Jain and V.K. Ohri Solutions For Economics CBSE Class 11 Commerce, Chapter 7 Frequency Diagrams, Histograms, Polygon and Ogive - TopperLearningAshok Kumar67% (3)
- Detailed Syllabus ST Xaviers Kolkata Eco HonsDocument20 pagesDetailed Syllabus ST Xaviers Kolkata Eco HonsSarbartho MukherjeeNo ratings yet
- Ch.4 - Measurement of National Income ( (Macro Economics - 12th Class) ) Green BookDocument120 pagesCh.4 - Measurement of National Income ( (Macro Economics - 12th Class) ) Green BookMayank MallNo ratings yet
- Model Question Papers: Class 11Document52 pagesModel Question Papers: Class 11Ronak SudhirNo ratings yet
- Economics Project XiiDocument11 pagesEconomics Project XiiKriti SinghNo ratings yet
- Human Capital FormationDocument14 pagesHuman Capital FormationKaustubh Chintalapudi100% (1)
- 11 Economics Statistics For Economics Introduction Notes and VideoDocument5 pages11 Economics Statistics For Economics Introduction Notes and VideoOs DaNo ratings yet
- UGC NET Economics Paper 2 Notes - Last Minute Revision Series - Libgen - Li PDFDocument111 pagesUGC NET Economics Paper 2 Notes - Last Minute Revision Series - Libgen - Li PDFFinmonkey. InNo ratings yet
- XII - Project Work in EconomicsDocument15 pagesXII - Project Work in EconomicsDaksh SharmaNo ratings yet
- Ugc Net Gradeup Playlist ListDocument3 pagesUgc Net Gradeup Playlist ListDaffodilNo ratings yet
- Full Syllabus ECONOMICS XII CBSEDocument231 pagesFull Syllabus ECONOMICS XII CBSEShubdhi94100% (1)
- CBSE Revised Syllabus & Sample Papers for Economics XII Exam 2021Document50 pagesCBSE Revised Syllabus & Sample Papers for Economics XII Exam 2021The Unknown vlogger100% (1)
- National Income MCQDocument23 pagesNational Income MCQishaanrox64No ratings yet
- Managerial Economics MeaningDocument41 pagesManagerial Economics MeaningPaul TibbinNo ratings yet
- Economics Grade 11 NCERT CBSE ProjectDocument2 pagesEconomics Grade 11 NCERT CBSE ProjectBhavesh Shaha0% (1)
- Term 1: EconomicsDocument26 pagesTerm 1: EconomicsShubh GuptaNo ratings yet
- 200 Questions of Economics With Answers Including 8 Chapters..Document43 pages200 Questions of Economics With Answers Including 8 Chapters..Abhijit KonwarNo ratings yet
- Accountancy Project Book - 47thDocument14 pagesAccountancy Project Book - 47thHimanshu Dadhich0% (1)
- Cbse Class 11 Accountancy Sample Paper Sa1 2014Document3 pagesCbse Class 11 Accountancy Sample Paper Sa1 2014Ranjeet KumarNo ratings yet
- Xii BST Support MaterialDocument154 pagesXii BST Support MaterialSamreen Kaur100% (1)
- DEY'S ECONOMICS-XII - Exam Handbook For 2024 ExamDocument62 pagesDEY'S ECONOMICS-XII - Exam Handbook For 2024 ExamYash Shrivastava100% (1)
- Indian Economic Development NCERT Gist: Growth, Reforms & ChallengesDocument27 pagesIndian Economic Development NCERT Gist: Growth, Reforms & ChallengesDhruv GuptaNo ratings yet
- 12 SM Economics PDFDocument204 pages12 SM Economics PDFMukund BansalNo ratings yet
- B.A. Hons Economics Readings 2012 13Document13 pagesB.A. Hons Economics Readings 2012 13Puja KumariNo ratings yet
- MBA-Project Guideline PDFDocument7 pagesMBA-Project Guideline PDFAbhi Singh100% (1)
- Balance of Payment AdjustmentDocument37 pagesBalance of Payment AdjustmentJash ShethiaNo ratings yet
- COVID-19 Impact on Indian Economy and Economic Remedial Measures In Overall Context of World EconomyFrom EverandCOVID-19 Impact on Indian Economy and Economic Remedial Measures In Overall Context of World EconomyNo ratings yet
- Tabulation of Data: Arranging Info in Rows & ColumnsDocument5 pagesTabulation of Data: Arranging Info in Rows & ColumnsSalman AnsariNo ratings yet
- B.Ed 1.5 Year 1 & 2 Assignment Spring 2019Document11 pagesB.Ed 1.5 Year 1 & 2 Assignment Spring 2019HamaYoun BabAr100% (1)
- 804 Math Answer SheetDocument12 pages804 Math Answer Sheetmaham khanNo ratings yet
- Applied ElectronicsDocument40 pagesApplied ElectronicsGuruKPO75% (4)
- Applied ElectronicsDocument37 pagesApplied ElectronicsGuruKPO100% (2)
- Abstract AlgebraDocument111 pagesAbstract AlgebraGuruKPO100% (5)
- Think Tank - Advertising & Sales PromotionDocument75 pagesThink Tank - Advertising & Sales PromotionGuruKPO67% (3)
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Biyani's Think Tank: Concept Based NotesDocument49 pagesBiyani's Think Tank: Concept Based NotesGuruKPO71% (7)
- Data Communication & NetworkingDocument138 pagesData Communication & NetworkingGuruKPO75% (4)
- OptimizationDocument96 pagesOptimizationGuruKPO67% (3)
- Advertising and Sales PromotionDocument75 pagesAdvertising and Sales PromotionGuruKPO100% (3)
- Production and Material ManagementDocument50 pagesProduction and Material ManagementGuruKPONo ratings yet
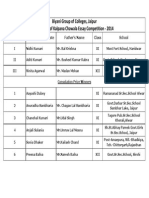
- Biyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014Document1 pageBiyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014GuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Computer Graphics & Image ProcessingDocument117 pagesComputer Graphics & Image ProcessingGuruKPONo ratings yet
- Fundamental of Nursing Nov 2013Document1 pageFundamental of Nursing Nov 2013GuruKPONo ratings yet
- Community Health Nursing I Nov 2013Document1 pageCommunity Health Nursing I Nov 2013GuruKPONo ratings yet
- Paediatric Nursing Sep 2013 PDFDocument1 pagePaediatric Nursing Sep 2013 PDFGuruKPONo ratings yet
- Community Health Nursing Jan 2013Document1 pageCommunity Health Nursing Jan 2013GuruKPONo ratings yet
- Biological Science Paper 1 Jan 2013Document1 pageBiological Science Paper 1 Jan 2013GuruKPONo ratings yet
- Biological Science Paper 1 Nov 2013Document1 pageBiological Science Paper 1 Nov 2013GuruKPONo ratings yet
- Community Health Nursing I July 2013Document1 pageCommunity Health Nursing I July 2013GuruKPONo ratings yet
- Business LawDocument112 pagesBusiness LawDewanFoysalHaqueNo ratings yet
- Biological Science Paper I July 2013Document1 pageBiological Science Paper I July 2013GuruKPONo ratings yet
- BA II English (Paper II)Document45 pagesBA II English (Paper II)GuruKPONo ratings yet
- Service MarketingDocument60 pagesService MarketingGuruKPONo ratings yet
- Business Ethics and EthosDocument36 pagesBusiness Ethics and EthosGuruKPO100% (3)
- Banking Services OperationsDocument134 pagesBanking Services OperationsGuruKPONo ratings yet
- Product and Brand ManagementDocument129 pagesProduct and Brand ManagementGuruKPONo ratings yet
- Software Project ManagementDocument41 pagesSoftware Project ManagementGuruKPO100% (1)
- Journal On The Impact of Nursing Informatics To Clinical PracticeDocument2 pagesJournal On The Impact of Nursing Informatics To Clinical PracticeLhara Vhaneza CuetoNo ratings yet
- Action Research 2017Document19 pagesAction Research 2017ryan tanjayNo ratings yet
- BIKF2023 - Call For PapersDocument14 pagesBIKF2023 - Call For PapersBabuRao Ganpatrao AapteNo ratings yet
- Security CultureDocument9 pagesSecurity CultureSamir RicaurteNo ratings yet
- Multi Sensory ApproachDocument11 pagesMulti Sensory Approachmahesh thampi100% (1)
- Mohini Jain Vs State of KarnatakaDocument13 pagesMohini Jain Vs State of KarnatakardandapsNo ratings yet
- Stakeholder Management in ProjectsDocument29 pagesStakeholder Management in Projectsbilalahmedsh100% (1)
- EVALUARE MOBILITATE ONLINE PadletDocument5 pagesEVALUARE MOBILITATE ONLINE PadletDanielaRăducănescuNo ratings yet
- E10 - Practice 2 (HK2) - Conditional Type 3Document6 pagesE10 - Practice 2 (HK2) - Conditional Type 3LittleSerenaNo ratings yet
- Community HealthDocument23 pagesCommunity HealthGlizzle MacaraegNo ratings yet
- NEBOSH International Diploma in Occupational Health & SafetyDocument1 pageNEBOSH International Diploma in Occupational Health & SafetyVignesh ShenoyNo ratings yet
- A Study On Working Women and Their InvestmentDocument70 pagesA Study On Working Women and Their InvestmentRITIKA PATHAKNo ratings yet
- 1-Plant Design - BasicsDocument7 pages1-Plant Design - BasicsAbdullahNo ratings yet
- Perfume Making Training ReportDocument7 pagesPerfume Making Training ReportGhulam Nabi NizamaniNo ratings yet
- All About PSME: By: Group 5 (Son, Estomata, Locsin, Dale)Document39 pagesAll About PSME: By: Group 5 (Son, Estomata, Locsin, Dale)Ronald VilladolidNo ratings yet
- Definition of Terms and Research Hypothesis in Chapter 3Document14 pagesDefinition of Terms and Research Hypothesis in Chapter 3laria jeanNo ratings yet
- AYC Application Form 2017: I. Background InformationDocument6 pagesAYC Application Form 2017: I. Background InformationyuoryNo ratings yet
- Inclusive EducationDocument75 pagesInclusive EducationJohn Paul MangalusNo ratings yet
- Mark Scheme (Results) January 2021: Pearson Edexcel International GCSE in Mathematics B (4MB1) Paper 01RDocument22 pagesMark Scheme (Results) January 2021: Pearson Edexcel International GCSE in Mathematics B (4MB1) Paper 01RYinMyat MonNo ratings yet
- MSC Projectmanagement 2022Document2 pagesMSC Projectmanagement 2022Hein HtetNo ratings yet
- Csulbh-Sslessonplan-Roughdraft 2Document7 pagesCsulbh-Sslessonplan-Roughdraft 2api-342334430No ratings yet
- English8 q1 Mod2of5 Bibliography v2Document20 pagesEnglish8 q1 Mod2of5 Bibliography v2GinaLaureaNo ratings yet
- NovardokDocument4 pagesNovardokRudolph C. KleinNo ratings yet
- Mil 4TH & 5TH Week Online PDFDocument4 pagesMil 4TH & 5TH Week Online PDFMylene HeragaNo ratings yet
- Toys Esl Vocabulary Presentation For Kids CLT Communicative Language Teaching Resources 136987Document24 pagesToys Esl Vocabulary Presentation For Kids CLT Communicative Language Teaching Resources 136987DenysNo ratings yet
- 10 A Television Documentary On Overeating Claimed That Americans Are About 10 Course HeroDocument1 page10 A Television Documentary On Overeating Claimed That Americans Are About 10 Course HeroWafaNo ratings yet
- Making Your CaseDocument313 pagesMaking Your CasefiseradaNo ratings yet
- The Students Will AnswerDocument8 pagesThe Students Will AnswerLexa Mae Quizon100% (2)
- Science of Happiness Paper 1Document5 pagesScience of Happiness Paper 1Palak PatelNo ratings yet
- Canada-Document Student VISA ChecklistDocument2 pagesCanada-Document Student VISA ChecklistChris Daniel MangoleNo ratings yet