You might also like
- Formula Matematik Dan Nota RingkasDocument9 pagesFormula Matematik Dan Nota RingkasPurawin Subramaniam100% (11)
- Math 1050 Project 3 Linear Least Squares ApproximationDocument9 pagesMath 1050 Project 3 Linear Least Squares Approximationapi-233311543No ratings yet
- STP Competitive AdvantageDocument58 pagesSTP Competitive Advantageamatulmateennoor100% (1)
- Task 19Document3 pagesTask 19Medha SinghNo ratings yet
- AccA P4/3.7 - 2002 - Dec - QDocument12 pagesAccA P4/3.7 - 2002 - Dec - Qroker_m3No ratings yet
- Arithmetic Mean ProblemsDocument7 pagesArithmetic Mean Problemsmuhammad irfanNo ratings yet
- Environmental Analysis: Process of Examining The Organization's Environment To DetermineDocument9 pagesEnvironmental Analysis: Process of Examining The Organization's Environment To DetermineTirthankar DattaNo ratings yet
- Strategic MarketingDocument11 pagesStrategic MarketingwarlockNo ratings yet
- Epgdib 2014-15 P&GDocument16 pagesEpgdib 2014-15 P&Ggrover_kNo ratings yet
- Project Profile: Rag Festival of Aurittro 04Document10 pagesProject Profile: Rag Festival of Aurittro 04coldplay_132No ratings yet
- Quantitative TechniquesDocument11 pagesQuantitative TechniquessanjayifmNo ratings yet
- SupplyDocument14 pagesSupplyWilliam Scott100% (1)
- Case Studies On Non-Fund Based LimitsDocument2 pagesCase Studies On Non-Fund Based Limitsparthasarathi_inNo ratings yet
- Chap 005Document8 pagesChap 005tai nguyenNo ratings yet
- Strategic Market Segmentation: Prepared By: Ma. Anna Corina G. Kagaoan Instructor College of Business and AccountancyDocument33 pagesStrategic Market Segmentation: Prepared By: Ma. Anna Corina G. Kagaoan Instructor College of Business and AccountancyAhsan ShahidNo ratings yet
- QuizDocument15 pagesQuizGovind N VNo ratings yet
- Marginal Costing and Profit PlanningDocument22 pagesMarginal Costing and Profit Planningdevika125790% (1)
- Tips On Project FinancingDocument3 pagesTips On Project FinancingRattinakumar SivaradjouNo ratings yet
- Futures: Distinction in Between Futures Contract and Forward ContractDocument85 pagesFutures: Distinction in Between Futures Contract and Forward ContractRDHNo ratings yet
- UBS CHANDIGARH FINAL PLACEMENT Brochure 2017Document56 pagesUBS CHANDIGARH FINAL PLACEMENT Brochure 2017DR DEEPAK KAPUR0% (1)
- Exchange Rate Theories: Dr. Amit SinhaDocument69 pagesExchange Rate Theories: Dr. Amit SinhaAmit SinhaNo ratings yet
- Trading MechanismDocument18 pagesTrading MechanismUttam GauravNo ratings yet
- Theories of Foreign ExchangeDocument19 pagesTheories of Foreign Exchangerockstarchandresh0% (1)
- Indian Carpet IndustryDocument22 pagesIndian Carpet IndustryPratik Kothari50% (2)
- Blades Hedge Thai Baht, British PoundDocument7 pagesBlades Hedge Thai Baht, British PoundAl-Imran Bin KhodadadNo ratings yet
- Bharti AirtelDocument19 pagesBharti Airtelpuneet9211No ratings yet
- Binomial TheoremDocument17 pagesBinomial TheoremSachin JaysenanNo ratings yet
- Number SystemDocument54 pagesNumber SystemBHASKAR SANKAR100% (1)
- Spring 12 QMB3250 Exam 1 Applicable Fall 09 Exam 1 SolutionsDocument6 pagesSpring 12 QMB3250 Exam 1 Applicable Fall 09 Exam 1 Solutionsjonaleman0923No ratings yet
- Number SystemDocument54 pagesNumber SystemShagun Jha100% (1)
- FandI_CT3_200604_ReportDocument11 pagesFandI_CT3_200604_Reportpriyanshu1495No ratings yet
- Discrete Mathematics Math 6A: Homework 9 SolutionDocument11 pagesDiscrete Mathematics Math 6A: Homework 9 SolutionShahnoor AliNo ratings yet
- Quiz Questions on Regression Analysis and CorrelationDocument10 pagesQuiz Questions on Regression Analysis and CorrelationHarsh ShrinetNo ratings yet
- Math 55: Discrete Mathematics Homework SolutionsDocument9 pagesMath 55: Discrete Mathematics Homework SolutionsKelly KavitaNo ratings yet
- SSC MOCK TEST - 20 (SOLUTIONDocument11 pagesSSC MOCK TEST - 20 (SOLUTIONsarathcopNo ratings yet
- Proctored Mock 1 SolutionDocument10 pagesProctored Mock 1 Solutiontheholyghost5989No ratings yet
- K.V. JMO 2014 SolutionsDocument11 pagesK.V. JMO 2014 SolutionsPremMehtaNo ratings yet
- Spline InterpolationDocument8 pagesSpline InterpolationLiaquatAliNo ratings yet
- Math 11 N12 THDocument101 pagesMath 11 N12 THMukesh MalavNo ratings yet
- Solved Paper−1 Class 10, Mathematics, SA−1 AnswersDocument29 pagesSolved Paper−1 Class 10, Mathematics, SA−1 AnswersSenthil KumaranNo ratings yet
- Num 2Document4 pagesNum 2Arockia RajNo ratings yet
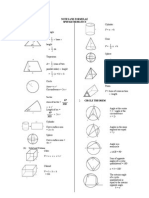
- SPM MATHS FORMULA GUIDEDocument9 pagesSPM MATHS FORMULA GUIDENurAinKhalidNo ratings yet
- Curve FittingDocument37 pagesCurve FittingToddharris100% (4)
- CBSE Board Class X Maths Basic Question Paper Solutions 2023Document35 pagesCBSE Board Class X Maths Basic Question Paper Solutions 2023sarojgiri1976No ratings yet
- Olved Xamples: Chapter # 2 Physics & MathematicsDocument18 pagesOlved Xamples: Chapter # 2 Physics & MathematicsthinkiitNo ratings yet
- Solutions 2001 2 AMC 10Document5 pagesSolutions 2001 2 AMC 10Llosemi LsNo ratings yet
- Notes and Formulae SPM Mathematics Form 1 - 3 Notes Solid GeometryDocument9 pagesNotes and Formulae SPM Mathematics Form 1 - 3 Notes Solid GeometrySharmini RajagopalNo ratings yet
- Sample Question Paper With SolutionsDocument47 pagesSample Question Paper With SolutionsanshumanNo ratings yet
- Bith212 Unit 1 IntegersDocument35 pagesBith212 Unit 1 IntegersAntonateNo ratings yet
- 13 Jan S1 RedDocument9 pages13 Jan S1 RedDulanga FernandoNo ratings yet
- JJC JC 2 H2 Maths 2011 Mid Year Exam QuestionsDocument9 pagesJJC JC 2 H2 Maths 2011 Mid Year Exam QuestionsjimmytanlimlongNo ratings yet
- Mathematics Question Bank For HighschoolDocument412 pagesMathematics Question Bank For HighschoolPintoSenkoNo ratings yet
- Curve Fitting, B-Splines & ApproximationsDocument14 pagesCurve Fitting, B-Splines & ApproximationsGetsuga TenshouNo ratings yet
- c3-c4 Specimen PaperDocument10 pagesc3-c4 Specimen Papersalak946290No ratings yet
- CBSE Class 10 Mathematics Sample Paper-04 (Solved)Document28 pagesCBSE Class 10 Mathematics Sample Paper-04 (Solved)cbsestudymaterialsNo ratings yet
- CS 540-3 Final Examination SolutionsDocument10 pagesCS 540-3 Final Examination SolutionsVũ Quốc NgọcNo ratings yet
- Notes and Formulae SPM Mathematics Form 1 - 3 Notes Solid GeometryDocument9 pagesNotes and Formulae SPM Mathematics Form 1 - 3 Notes Solid GeometryJarnice Ling Yee ChingNo ratings yet
- Final Exam 2017 - CO4403Document4 pagesFinal Exam 2017 - CO4403vs sNo ratings yet
- Binomial TheoremDocument9 pagesBinomial TheoremKapil ChaudharyNo ratings yet
- Assignment For Science Class 10Document9 pagesAssignment For Science Class 10Palvi DeviNo ratings yet
- Networking Essentials Exam NotesDocument5 pagesNetworking Essentials Exam NotesKevin H PhamNo ratings yet
- Driver Qualification NotesDocument4 pagesDriver Qualification NotesKevin H PhamNo ratings yet
- Morse Code and Phonetic AlphabetDocument2 pagesMorse Code and Phonetic AlphabetKevin H PhamNo ratings yet
- I Went To School: and It Was Fun. This Is A New FontDocument1 pageI Went To School: and It Was Fun. This Is A New FontKevin H PhamNo ratings yet
- Referencing ExerciseDocument1 pageReferencing ExerciseKevin H PhamNo ratings yet
- Cover Page: 37242 Optimisation in Quantitative Management Ollaborative Written AssignmentDocument1 pageCover Page: 37242 Optimisation in Quantitative Management Ollaborative Written AssignmentKevin H PhamNo ratings yet
- Assessment and Assignment To-DoDocument1 pageAssessment and Assignment To-DoKevin H PhamNo ratings yet
- Stability Constants of Metal Complexes: Section - CDocument34 pagesStability Constants of Metal Complexes: Section - ChaumeoNo ratings yet
- Assessment StandardsDocument13 pagesAssessment Standardsapi-197799687No ratings yet
- Fyugp MDCDocument32 pagesFyugp MDCIIM CSCNo ratings yet
- Logarithms Explained: Definition of A Logarithmic FunctionDocument8 pagesLogarithms Explained: Definition of A Logarithmic FunctionJinkee TacandongNo ratings yet
- Setting Cut-Offs in Numerical ModelingDocument12 pagesSetting Cut-Offs in Numerical Modelingviya7No ratings yet
- Introduction To LogarithmDocument5 pagesIntroduction To LogarithmBong Chun100% (1)
- Emerge Guide PDFDocument124 pagesEmerge Guide PDFmehrdad sadeghiNo ratings yet
- Comp631 Chap6Document234 pagesComp631 Chap6Myo Thi HaNo ratings yet
- Experiment 1Document9 pagesExperiment 1Rizza Mae RaferNo ratings yet
- Mathematics Class 10 Enrichment MaterialDocument85 pagesMathematics Class 10 Enrichment Materialnarsi reddy MorthalaNo ratings yet
- Exponential and Logarithmic FunctionsDocument22 pagesExponential and Logarithmic FunctionsPie PeyNo ratings yet
- DPP (29 - ) 12th Maths WADocument46 pagesDPP (29 - ) 12th Maths WARaju SinghNo ratings yet
- 0606 Scheme of Work (For Examination From 2016)Document64 pages0606 Scheme of Work (For Examination From 2016)Khmer Cham100% (2)
- CS 253: Algorithms: Growth of FunctionsDocument22 pagesCS 253: Algorithms: Growth of FunctionsVishalkumar BhattNo ratings yet
- Physics BookDocument78 pagesPhysics BookOrNo ratings yet
- Electrodermal Act Very ImportantDocument43 pagesElectrodermal Act Very Importantexplorator1No ratings yet
- Basic Calculus Activity Sheet Quarter 3 - Melc 5Document10 pagesBasic Calculus Activity Sheet Quarter 3 - Melc 5Bea JalipaNo ratings yet
- Multiple choice exam on exponential and logarithmic functionsDocument17 pagesMultiple choice exam on exponential and logarithmic functionsValeria Olmos FernándezNo ratings yet
- Fractional Calculus - ApplicationsDocument306 pagesFractional Calculus - ApplicationsJohn Alain Stanley Viraca Vega100% (1)
- History of LogarithmsDocument14 pagesHistory of LogarithmsBear ZOobearNo ratings yet
- Logarithm sht2Document3 pagesLogarithm sht2Ainee100% (1)
- Concepts Linear Vs Non-Linear RegressionDocument32 pagesConcepts Linear Vs Non-Linear RegressionZain Ahmad Khan100% (1)
- Cargo and Trim Problems SolvedDocument8 pagesCargo and Trim Problems SolvedGeorge CarinoNo ratings yet
- PPT4-Exponential and Logarithmic FunctionsDocument17 pagesPPT4-Exponential and Logarithmic FunctionsRano AcunNo ratings yet
- Bacterial-Endotoxins QAS11-452 FINAL July12 PDFDocument13 pagesBacterial-Endotoxins QAS11-452 FINAL July12 PDFsherylqueridaNo ratings yet
- LogarithmsDocument19 pagesLogarithmsRidha Aprilia AminNo ratings yet
- Calculus in Management Sciences SyllabusDocument3 pagesCalculus in Management Sciences SyllabusNguyễn HàNo ratings yet
- Stat FitDocument112 pagesStat FitedwinwwillanNo ratings yet
- Melnikov, Green's Functions and Elementary Functions, 2011Document176 pagesMelnikov, Green's Functions and Elementary Functions, 2011Denis JaissonNo ratings yet
- 31 - Kahneman Et Al (2023) - Income and Emotional Well-Being - A Conflict ResolvedDocument6 pages31 - Kahneman Et Al (2023) - Income and Emotional Well-Being - A Conflict ResolvedCorrado BisottoNo ratings yet