You might also like
- OS CDAC Question Paper PDFDocument3 pagesOS CDAC Question Paper PDFAnjali SahuNo ratings yet
- File Structures 10is63 NotesDocument107 pagesFile Structures 10is63 NotesSagar s KarnawadiNo ratings yet
- Unix Process Control. Linux Tools and The Proc File SystemDocument89 pagesUnix Process Control. Linux Tools and The Proc File SystemKetan KumarNo ratings yet
- Data Structure Viva QuestionsDocument9 pagesData Structure Viva Questionsirfanahmed.dba@gmail.comNo ratings yet
- A Comparative Study On Fake Job Post Prediction Using Different Data Mining TechniquesDocument5 pagesA Comparative Study On Fake Job Post Prediction Using Different Data Mining Techniquesbits computers100% (1)
- 2 Marks QuestionsDocument30 pages2 Marks QuestionsVictor LfpNo ratings yet
- PERSISTENCE Placement Papers 3: Archive For The PERSISTENCE SYSTEMS' CategoryDocument50 pagesPERSISTENCE Placement Papers 3: Archive For The PERSISTENCE SYSTEMS' CategorySrikanth Soma100% (2)
- The Joy of Computing Using Python - Unit 2 - Week 0Document3 pagesThe Joy of Computing Using Python - Unit 2 - Week 0Ruy Lopez ClosedNo ratings yet
- Exercises and Projects for File I/O ProgramsDocument21 pagesExercises and Projects for File I/O Programshertzberg 1No ratings yet
- Cognos 10Document35 pagesCognos 10annareddypraveen100% (4)
- LAB MANUAL CST (Soft Computing) 12!02!2019Document66 pagesLAB MANUAL CST (Soft Computing) 12!02!2019alpha gammaNo ratings yet
- Technical Interview PrepDocument7 pagesTechnical Interview PrepAlina RNo ratings yet
- This Set of Operating System Multiple Choice QuestionsDocument13 pagesThis Set of Operating System Multiple Choice QuestionsUsama ArshadNo ratings yet
- Data Mining and Business Intelligence Lab ManualDocument52 pagesData Mining and Business Intelligence Lab ManualVinay JokareNo ratings yet
- PKVM - IT Practical SLIPS 9860272494 FOR SCIENCEDocument24 pagesPKVM - IT Practical SLIPS 9860272494 FOR SCIENCEDevidas Dhekle100% (1)
- C ProgrammingDocument39 pagesC ProgrammingSurya Padma100% (1)
- Btech-E Div Assignment1Document28 pagesBtech-E Div Assignment1akash singhNo ratings yet
- A719552767 - 20992 - 7 - 2019 - Lecture10 Python OOPDocument15 pagesA719552767 - 20992 - 7 - 2019 - Lecture10 Python OOPrahulNo ratings yet
- File Handling in CDocument58 pagesFile Handling in CSalman Javed BajwaNo ratings yet
- MS .NET Question Bank Covers Classes, Objects, Arrays, ExceptionsDocument3 pagesMS .NET Question Bank Covers Classes, Objects, Arrays, ExceptionsChandrakant KaralkarNo ratings yet
- Data Structure Using C: Proposal On Phone Directory Application Using Doubly-Linked ListDocument5 pagesData Structure Using C: Proposal On Phone Directory Application Using Doubly-Linked Listgirish desaiNo ratings yet
- File Handling (MCQ'S)Document9 pagesFile Handling (MCQ'S)Amogh D GNo ratings yet
- Advanced Java Material Download FromDocument148 pagesAdvanced Java Material Download Fromswathisural100% (1)
- CS301 Finalterm Subjective 2013 Solved - 2Document16 pagesCS301 Finalterm Subjective 2013 Solved - 2Network Bull100% (2)
- DSA Weekly PlanDocument3 pagesDSA Weekly PlanJatin0% (1)
- Javascript Exercise AnswerDocument10 pagesJavascript Exercise AnswerRevati MenghaniNo ratings yet
- OS MCQ Set 3Document4 pagesOS MCQ Set 3Sudhanshu SinghNo ratings yet
- File Organization and Processing PDFDocument2 pagesFile Organization and Processing PDFGeorgeNo ratings yet
- Data Structures and Algorithms - IntroDocument20 pagesData Structures and Algorithms - IntroRajan JaiprakashNo ratings yet
- Principles of Programming-2016Document90 pagesPrinciples of Programming-2016LWATE SAMUEL100% (1)
- Input Output in C++ PDFDocument11 pagesInput Output in C++ PDFAll TvwnzNo ratings yet
- Richard ADocument22 pagesRichard AMohammed AbdullahNo ratings yet
- CS604 - Finalterm Solved Mcqs Solved With ReferencesDocument49 pagesCS604 - Finalterm Solved Mcqs Solved With ReferencesPrincessRabiNo ratings yet
- Linux Lab ManuelDocument23 pagesLinux Lab ManuelNikhil MaliNo ratings yet
- Level-1:: Competitive Programming - SyllabusDocument2 pagesLevel-1:: Competitive Programming - Syllabusgupta_ssrkm2747No ratings yet
- Artificial Intelligence Chap2-2Document147 pagesArtificial Intelligence Chap2-2Jesse SandersNo ratings yet
- 2 - UNIT - II - Synchronization and DeadlocksDocument45 pages2 - UNIT - II - Synchronization and DeadlocksTharaka Roopesh100% (1)
- Computer SecurityDocument6 pagesComputer SecurityYamini SNo ratings yet
- CS8492 /database Management Systems 2017 Regulations: Unit Iv Implementation TechniquesDocument22 pagesCS8492 /database Management Systems 2017 Regulations: Unit Iv Implementation TechniquesHarshath MNo ratings yet
- Information Retrieval Systems important questions for IV-Year examDocument3 pagesInformation Retrieval Systems important questions for IV-Year examJaini KavyaNo ratings yet
- Java OOP Lab Assignments Week 1-4Document20 pagesJava OOP Lab Assignments Week 1-4Techno PrasadNo ratings yet
- Storage, Indices, B Tree, Hashing in DbmsDocument34 pagesStorage, Indices, B Tree, Hashing in Dbmsabs100% (1)
- Android SQLite Database TutorialDocument6 pagesAndroid SQLite Database TutorialJean claude onanaNo ratings yet
- C# Collections GuideDocument4 pagesC# Collections GuideJanicealmine SandeepsharmaNo ratings yet
- Data Link LayerDocument23 pagesData Link LayerVipin NagarNo ratings yet
- Retrieval Utilities Improve ResultsDocument19 pagesRetrieval Utilities Improve ResultsTaran RishitNo ratings yet
- MySQL Interview Questions and Answers For Experienced and FreshersDocument5 pagesMySQL Interview Questions and Answers For Experienced and FreshersMohmad Ashik M ANo ratings yet
- Training Course Outlines: Machine LearningDocument3 pagesTraining Course Outlines: Machine LearningArslan NazirNo ratings yet
- Fundamentals of Algorithmic Problem Solving: B.B. Karki, LSU 2.1 CSC 3102Document4 pagesFundamentals of Algorithmic Problem Solving: B.B. Karki, LSU 2.1 CSC 3102Syed JabeerNo ratings yet
- CS363 Spring 2021 Homework 2Document9 pagesCS363 Spring 2021 Homework 2zubair zubairNo ratings yet
- LoadrunnerDocument48 pagesLoadrunnerjayand_netNo ratings yet
- Unit-I: Introduction To Information Retrieval SystemsDocument14 pagesUnit-I: Introduction To Information Retrieval Systems7killers4u100% (1)
- IRS Unit-1Document14 pagesIRS Unit-1Ratna Raju Ayalapogu100% (4)
- IRS Study MaterialDocument87 pagesIRS Study Materialrishisiliveri95100% (1)
- Irs Unit1Document15 pagesIrs Unit1Kadasi AbishekNo ratings yet
- Irs Unit-1Document61 pagesIrs Unit-1brecwcseb 20No ratings yet
- IRS Unit-1Document14 pagesIRS Unit-1Nagendra MarisettiNo ratings yet
- IRS: Information Storage and Retrieval SystemsDocument16 pagesIRS: Information Storage and Retrieval SystemsMohamed EzzNo ratings yet
- IRS Unit-1Document27 pagesIRS Unit-1Venkatesh JNo ratings yet
- Data Management and Visualization GuideDocument116 pagesData Management and Visualization GuideSiddarthModiNo ratings yet
- Who Invented C Language?: The Compilers, JVMS, Kernals Etc. Are Written in C Language and Most of Languages Follows CDocument7 pagesWho Invented C Language?: The Compilers, JVMS, Kernals Etc. Are Written in C Language and Most of Languages Follows CSiddarthModiNo ratings yet
- Guidelines For Submitting The AbstractDocument2 pagesGuidelines For Submitting The AbstractSiddarthModiNo ratings yet
- IRS Unit-2Document13 pagesIRS Unit-2SiddarthModi100% (2)
- WTDocument15 pagesWTSiddarthModiNo ratings yet
- SEVivaDocument16 pagesSEVivaSiddarthModiNo ratings yet
- Virtual Memory Can Slow Down PerformanceDocument5 pagesVirtual Memory Can Slow Down PerformanceSiddarthModiNo ratings yet
- IRS Unit-3Document28 pagesIRS Unit-3SiddarthModi100% (2)
- Economics and Financial Accounting NotesDocument187 pagesEconomics and Financial Accounting NotesGovindinne SivakanthareddyNo ratings yet
- Information Retrieval SystemsDocument102 pagesInformation Retrieval SystemsSiddarthModi100% (1)
- Soft Text SearchDocument14 pagesSoft Text SearchSiddarthModiNo ratings yet
- IRS Unit 7-8Document164 pagesIRS Unit 7-8SiddarthModiNo ratings yet
- Associate Analytics Appendix Additional Practice QuestionsDocument34 pagesAssociate Analytics Appendix Additional Practice QuestionsSiddarthModiNo ratings yet
- OoadDocument3 pagesOoadSiddarthModiNo ratings yet
- STM ImpDocument4 pagesSTM ImpSiddarthModiNo ratings yet
- 1.install Virtualbox 2.put Ubuntu in It Using Iso 3.install R UsingDocument6 pages1.install Virtualbox 2.put Ubuntu in It Using Iso 3.install R UsingSiddarthModiNo ratings yet
- SaimathadocDocument19 pagesSaimathadocSiddarthModiNo ratings yet
- HTMLDocument40 pagesHTMLSiddarthModiNo ratings yet
- SadfDocument3 pagesSadfSiddarthModiNo ratings yet
- Associate Analytics M1 SHDocument112 pagesAssociate Analytics M1 SHSiddarthModiNo ratings yet
- 2006 34Document364 pages2006 34SiddarthModiNo ratings yet
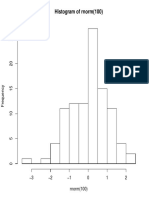
- Histogram of RnormDocument1 pageHistogram of RnormSiddarthModiNo ratings yet
- Serv LetsDocument7 pagesServ LetsSiddarthModiNo ratings yet
- B.Tech 3-2 R13-Timetable PDFDocument12 pagesB.Tech 3-2 R13-Timetable PDFAthulNo ratings yet
- AptitudeasdDocument59 pagesAptitudeasdSiddarthModi0% (1)
- MEFADocument2 pagesMEFASiddarthModiNo ratings yet
- XhasdDocument1 pageXhasdSiddarthModiNo ratings yet
- XhasdDocument1 pageXhasdSiddarthModiNo ratings yet
- Annex XIV - UNFPA Client Order Tracking ApplicationDocument45 pagesAnnex XIV - UNFPA Client Order Tracking Applicationanatomi arsitekturNo ratings yet
- Oracle Fusion Applications Post-Installation GuideDocument124 pagesOracle Fusion Applications Post-Installation GuidenewmanNo ratings yet
- Distributed DBMS - CS712 Power Point Slides Lecture 11Document13 pagesDistributed DBMS - CS712 Power Point Slides Lecture 11Hafiz Muhammad KashifNo ratings yet
- Hadoop Cheat Sheet - Jesse AndersonDocument7 pagesHadoop Cheat Sheet - Jesse AndersonAskia TheGreatNo ratings yet
- Defect Tracking FlowchartDocument5 pagesDefect Tracking FlowchartJohn MrGrimm DobsonNo ratings yet
- Using Active Data Guard Reporting With Oracle E-Business Suite ReleaseDocument21 pagesUsing Active Data Guard Reporting With Oracle E-Business Suite ReleaseMohammed Abdul MuqeetNo ratings yet
- Handling Missing DataDocument21 pagesHandling Missing DataJenny CastilloNo ratings yet
- Project Topics in Computer Science Department Nigerian UniversitiesDocument10 pagesProject Topics in Computer Science Department Nigerian UniversitiesChizzy Rose100% (1)
- Login and LogoutDocument11 pagesLogin and LogoutKeerthikeshwar ReddyNo ratings yet
- Spring Boot EssentialsDocument2 pagesSpring Boot EssentialsMohd ArifNo ratings yet
- Lean-Six Sigma in The Age of Artificial IntelligenceDocument5 pagesLean-Six Sigma in The Age of Artificial IntelligenceJuan Planas RivarolaNo ratings yet
- Scribe Insight TutorialDocument30 pagesScribe Insight TutorialKavi ManiNo ratings yet
- ISO 1302 2002 Indication of Surface Texture in Technical Product DocumentationDocument67 pagesISO 1302 2002 Indication of Surface Texture in Technical Product DocumentationprasannaNo ratings yet
- Application TechniquesDocument840 pagesApplication Techniquesruzawani86No ratings yet
- What a CMS Does and How it Facilitates Content CreationDocument2 pagesWhat a CMS Does and How it Facilitates Content CreationAungNo ratings yet
- Daily, Weekly and Monthly Responsibilities For Oracle Applications DbasDocument21 pagesDaily, Weekly and Monthly Responsibilities For Oracle Applications DbasVikrant ThapaNo ratings yet
- ArcGIS Water Utilities-Data Models For Water UtilitiesDocument126 pagesArcGIS Water Utilities-Data Models For Water UtilitiesJohnWW100% (4)
- Testing PhaseDocument15 pagesTesting PhaseSaad MansoorNo ratings yet
- Hospital Appiontment System CsDocument22 pagesHospital Appiontment System Csmithul3214No ratings yet
- Davis Gordon BDocument22 pagesDavis Gordon BGonzalo Noriega MorenoNo ratings yet
- Python Crash Course: INSTALLED - APPS, Which Is Stored in The Project's Settings - Py FileDocument4 pagesPython Crash Course: INSTALLED - APPS, Which Is Stored in The Project's Settings - Py FileROBERTO CUJIANo ratings yet
- Dbflow: Professional Android App DevelopmentDocument14 pagesDbflow: Professional Android App Developmentsidoga lesgowkagarutNo ratings yet
- Hrms TablesDocument32 pagesHrms TablesJoshua MeyerNo ratings yet
- Angular 6 CRUD Example - MEAN Stack TutorialDocument39 pagesAngular 6 CRUD Example - MEAN Stack TutorialEstebanRodriguezNo ratings yet
- Chapter One: Learning ObjectivesDocument21 pagesChapter One: Learning ObjectivesK59 Tran Gia KhanhNo ratings yet
- Initial Data Requirement TemplateDocument57 pagesInitial Data Requirement TemplateAruna ParimiNo ratings yet
- CSD Syllabus StructureDocument174 pagesCSD Syllabus StructureTaqi ShahNo ratings yet
- Slido 2Document39 pagesSlido 2Tony SchickNo ratings yet
- Allot NX Server Migration From Windows To LinuxDocument29 pagesAllot NX Server Migration From Windows To LinuxJenster ImarcloudNo ratings yet
- Cloud Native Computing: Daniyal NagoriDocument31 pagesCloud Native Computing: Daniyal NagoriWaqasMirzaNo ratings yet