You might also like
- Sensor CatalogueDocument72 pagesSensor Cataloguefurious man67% (3)
- Jump Start MySQL: Master the Database That Powers the WebFrom EverandJump Start MySQL: Master the Database That Powers the WebNo ratings yet
- Alpha New Bp12Document54 pagesAlpha New Bp12AUTO HUBNo ratings yet
- A Guide To The Preparation of Civil Engineering Drawing PDFDocument186 pagesA Guide To The Preparation of Civil Engineering Drawing PDFEraj100% (3)
- Database Management System FundamentalsDocument114 pagesDatabase Management System FundamentalsAkash SachanNo ratings yet
- Design & Fabrication of a Cost-Effective Agricultural DroneDocument57 pagesDesign & Fabrication of a Cost-Effective Agricultural DroneFatima Nasir R:29No ratings yet
- A320 CBT Test 1 PDFDocument107 pagesA320 CBT Test 1 PDFCesarNo ratings yet
- Facilities Assignment 1-2-2015Document2 pagesFacilities Assignment 1-2-2015Xnort G. Xwest0% (1)
- 000 200 1210 Guidelines For Minimum Deliverables 3 November 2011Document22 pages000 200 1210 Guidelines For Minimum Deliverables 3 November 2011Raul Bautista100% (1)
- Hierarchical Model: Database ModelsDocument8 pagesHierarchical Model: Database Modelsmallireddy1234No ratings yet
- What Is in A Relational Database Model?Document23 pagesWhat Is in A Relational Database Model?H YasirNo ratings yet
- Databases ModelDocument6 pagesDatabases Modelirshia9469No ratings yet
- Database Models: Hierarchical ModelDocument6 pagesDatabase Models: Hierarchical ModelVinothkumarNo ratings yet
- DB TypesDocument9 pagesDB TypesIsmail ZebNo ratings yet
- What Are Database TypesDocument7 pagesWhat Are Database TypesZubair AkhtarNo ratings yet
- DatabaseDocument12 pagesDatabasenawasyt700No ratings yet
- RDBMS Stands For Relational Database Management SystemsDocument6 pagesRDBMS Stands For Relational Database Management SystemsABIGAIL RINNAH S 20BBA102No ratings yet
- AssignmentDocument35 pagesAssignmentnepal pokhara100% (1)
- Types of DbmsDocument13 pagesTypes of DbmsTisa ShakyaNo ratings yet
- Database Management SystemsDocument7 pagesDatabase Management SystemsfaisalNo ratings yet
- Own Preparation What Is A Database?: OracleDocument16 pagesOwn Preparation What Is A Database?: OracleKranthi-JuvvaNo ratings yet
- DBMS Unit 1Document15 pagesDBMS Unit 1Harsh OjhaNo ratings yet
- Database Models: Hierarchical ModelDocument6 pagesDatabase Models: Hierarchical ModeldipanshuhandooNo ratings yet
- Final DbmsDocument32 pagesFinal DbmsSachin JainNo ratings yet
- Assignment 1Document19 pagesAssignment 1afifa mawan100% (1)
- NoSQL Database Types and ModelsDocument8 pagesNoSQL Database Types and ModelsSiddharth JrNo ratings yet
- MIS442 Chapter 6 DocumentDocument5 pagesMIS442 Chapter 6 DocumentshantoNo ratings yet
- Database ConceptDocument4 pagesDatabase ConceptITI GarhjamulaNo ratings yet
- Organize Data Powerfully with DatabasesDocument16 pagesOrganize Data Powerfully with DatabasesIsha PundirNo ratings yet
- 3 - DBMSDocument13 pages3 - DBMScyka blyatNo ratings yet
- Slide 2 - Relational DatabaseDocument14 pagesSlide 2 - Relational DatabasecnajjembaNo ratings yet
- Database 2nd SemesterDocument18 pagesDatabase 2nd SemesterEngr RakNo ratings yet
- Data Base ModelsDocument26 pagesData Base ModelsTony JacobNo ratings yet
- Data BaseDocument23 pagesData BasealimaNo ratings yet
- Hierarchical Model The Hierarchical Data Model Organizes Data in A Tree StructureDocument6 pagesHierarchical Model The Hierarchical Data Model Organizes Data in A Tree Structureshail_pariNo ratings yet
- DBMS1Document9 pagesDBMS1bhojraj singhNo ratings yet
- Lesson 2Document50 pagesLesson 2Ahmed MujtabaNo ratings yet
- Types of Database Management SystemsDocument6 pagesTypes of Database Management SystemsAsis MahalikNo ratings yet
- Lecture 1Document50 pagesLecture 1Lakshay MITTALNo ratings yet
- UNIT-2Document34 pagesUNIT-2vishalsingh9669No ratings yet
- Cape Notes Unit 2 Module 1 Content 1 3Document12 pagesCape Notes Unit 2 Module 1 Content 1 3Pauline WaltersNo ratings yet
- Types of Databases PDFDocument13 pagesTypes of Databases PDFanon_456991453No ratings yet
- DBMS vs File SystemsDocument13 pagesDBMS vs File SystemsablosNo ratings yet
- Case Study On Different Nosql Data ModelsDocument6 pagesCase Study On Different Nosql Data ModelsutkarshNo ratings yet
- 6testing DB Imp m06Document14 pages6testing DB Imp m06masresha teferaNo ratings yet
- Prelims 5Document7 pagesPrelims 5Akshata ChopadeNo ratings yet
- What Is An Engineering Information SystemDocument3 pagesWhat Is An Engineering Information Systemhannah AyengNo ratings yet
- European Database DirectiveDocument13 pagesEuropean Database DirectiveManish SahuNo ratings yet
- 1st Chap Data ModelsDocument47 pages1st Chap Data ModelsGuru DarshanNo ratings yet
- Database ModelDocument8 pagesDatabase Modelkatherine976No ratings yet
- What Is A DatabaseDocument3 pagesWhat Is A DatabaseJanous G. AbadNo ratings yet
- Database Management System-1Document26 pagesDatabase Management System-1Vyanjna pandeyNo ratings yet
- Cape Notes Unit 2 Module 1 Content 1 3 2Document11 pagesCape Notes Unit 2 Module 1 Content 1 3 2Kxñg BùrtõñNo ratings yet
- Module 3 - Data and Database ManagementDocument11 pagesModule 3 - Data and Database ManagementDarrilyn VillalunaNo ratings yet
- Types of Data BaseDocument10 pagesTypes of Data BaseFaisal Awan100% (1)
- A Database Model Shows The Logical Structure of A DatabaseDocument4 pagesA Database Model Shows The Logical Structure of A DatabaseFungai ChotoNo ratings yet
- InsertttDocument25 pagesInsertttYoo Hoo BinNo ratings yet
- UNIT 6: Database Management SystemDocument20 pagesUNIT 6: Database Management SystemheropantiNo ratings yet
- Types of Database ModelsDocument5 pagesTypes of Database ModelsRobell SamsonNo ratings yet
- Differentiate IM Terms Records Fields TablesDocument12 pagesDifferentiate IM Terms Records Fields TablesDrake Wells0% (1)
- AdDB Chap 1Document42 pagesAdDB Chap 1Mercy DegaNo ratings yet
- What is a Database in 40 CharactersDocument15 pagesWhat is a Database in 40 Charactersshivam kacholeNo ratings yet
- Evolution of DBMSDocument3 pagesEvolution of DBMSAhitha RajNo ratings yet
- Term Paper On Database Management SystemDocument40 pagesTerm Paper On Database Management SystemSakib StudentNo ratings yet
- A Database Is A Structured Collection of DataDocument21 pagesA Database Is A Structured Collection of DataAmar SarkarNo ratings yet
- DataDocument7 pagesData9y9aNo ratings yet
- National University of Lesotho Database Systems AssignmentDocument7 pagesNational University of Lesotho Database Systems AssignmentJolly MarkNo ratings yet
- National University of Lesotho Database Systems AssignmentDocument7 pagesNational University of Lesotho Database Systems AssignmentJolly MarkNo ratings yet
- DocumentDocument2 pagesDocumentJolly MarkNo ratings yet
- DocumentDocument2 pagesDocumentJolly MarkNo ratings yet
- Solar Charge Controller SolsumF Manual PDFDocument1 pageSolar Charge Controller SolsumF Manual PDFJolly MarkNo ratings yet
- The Basics of Solar Power For Producing ElectricityDocument5 pagesThe Basics of Solar Power For Producing ElectricityJason HallNo ratings yet
- Gallium Nitride Materials and Devices IV: Proceedings of SpieDocument16 pagesGallium Nitride Materials and Devices IV: Proceedings of SpieBatiriMichaelNo ratings yet
- Digital Logic Design - Switch Logic & Basic GatesDocument27 pagesDigital Logic Design - Switch Logic & Basic GatesTroon SoonNo ratings yet
- Cross Belt Magnetic Separator (CBMS)Document2 pagesCross Belt Magnetic Separator (CBMS)mkbhat17kNo ratings yet
- Hot Rolled Sheet Pile SHZ Catalogue PDFDocument2 pagesHot Rolled Sheet Pile SHZ Catalogue PDFkiet eelNo ratings yet
- MleplustutorialDocument13 pagesMleplustutorialvorge daoNo ratings yet
- 08 Candelaria Punta Del Cobre IOCG Deposits PDFDocument27 pages08 Candelaria Punta Del Cobre IOCG Deposits PDFDiego Morales DíazNo ratings yet
- Ce010 601 Design of Steel Structures Ce PDFDocument5 pagesCe010 601 Design of Steel Structures Ce PDFPrakash rubanNo ratings yet
- Unit 10Document18 pagesUnit 10ChaithraMalluNo ratings yet
- Timers, Serial CommunicationDocument19 pagesTimers, Serial CommunicationVyshnav PNo ratings yet
- Eurotech IoT Gateway Reliagate 10 12 ManualDocument88 pagesEurotech IoT Gateway Reliagate 10 12 Manualfelix olguinNo ratings yet
- RelativedensityipgDocument2 pagesRelativedensityipgapi-310625232No ratings yet
- Instrumentation Design UTHMDocument5 pagesInstrumentation Design UTHMAnis AzwaNo ratings yet
- Javascript Api: Requirements Concepts Tutorial Api ReferenceDocument88 pagesJavascript Api: Requirements Concepts Tutorial Api ReferenceAshish BansalNo ratings yet
- Sequelize GuideDocument5 pagesSequelize Guidemathur1995No ratings yet
- Developmental Morphology and Physiology of GrassesDocument26 pagesDevelopmental Morphology and Physiology of GrassesAnonymous xGVfcqNo ratings yet
- Superconductivity in RH S and PD Se: A Comparative StudyDocument5 pagesSuperconductivity in RH S and PD Se: A Comparative StudyChithra ArulmozhiNo ratings yet
- CI SetDocument18 pagesCI Setতন্ময় ঢালি Tanmay DhaliNo ratings yet
- Unit-I-2-Marks-With-Ans3 Hydrology1 - BY Civildatas - Blogspot.in PDFDocument4 pagesUnit-I-2-Marks-With-Ans3 Hydrology1 - BY Civildatas - Blogspot.in PDFHimanshu sharmaNo ratings yet
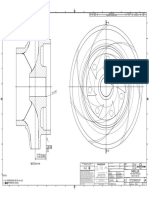
- Impeller: REV Rev by Description PCN / Ecn Date CHK'D A JMM Released For Production N/A 18/11/2019 PDLDocument1 pageImpeller: REV Rev by Description PCN / Ecn Date CHK'D A JMM Released For Production N/A 18/11/2019 PDLSenthilkumar RamalingamNo ratings yet
- Tutorial CorelDRAW-X8Document10 pagesTutorial CorelDRAW-X8Ajay BhargavaNo ratings yet
- Austenitic Stainless SteelsDocument10 pagesAustenitic Stainless SteelsbramNo ratings yet
- Data Warehousing: Modern Database ManagementDocument49 pagesData Warehousing: Modern Database ManagementNgọc TrâmNo ratings yet
- Green Synthesis of Zinc Oxide Nanoparticles: Elizabeth Varghese and Mary GeorgeDocument8 pagesGreen Synthesis of Zinc Oxide Nanoparticles: Elizabeth Varghese and Mary GeorgesstephonrenatoNo ratings yet