You might also like
- Bloch TheoremDocument2 pagesBloch TheoremSurajNo ratings yet
- Lecture 9Document7 pagesLecture 9Milind BhatiaNo ratings yet
- Two Degree Freedom Systems AnalysisDocument14 pagesTwo Degree Freedom Systems AnalysisMahmoud Abdelghafar ElhussienyNo ratings yet
- A New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayDocument6 pagesA New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayWaj DINo ratings yet
- Lecture 13 Ece4330tDocument54 pagesLecture 13 Ece4330tHamza AteeqNo ratings yet
- Simulink_Modelling_of_the_Transient_CaseDocument39 pagesSimulink_Modelling_of_the_Transient_CaseMUSAIB UL FAYAZ 2022 17No ratings yet
- Cross Product and Lines in 3-SpaceDocument4 pagesCross Product and Lines in 3-SpaceBirru Asia RayaniNo ratings yet
- Chapter 1. Matrices, Vectors and Vector Calculus: Quantities That AreDocument20 pagesChapter 1. Matrices, Vectors and Vector Calculus: Quantities That AreHan Sang HyeonNo ratings yet
- MAT 386 Presentation 12 - Lce - and - Lorenz - SystemDocument24 pagesMAT 386 Presentation 12 - Lce - and - Lorenz - SystemDiya MalikNo ratings yet
- ECEN 214 Lab 8Document8 pagesECEN 214 Lab 8Shoaib AhmedNo ratings yet
- Department of Physics: Federal Urdu University of Arts, Science and Technology, KarachiDocument3 pagesDepartment of Physics: Federal Urdu University of Arts, Science and Technology, KarachiHashir SaeedNo ratings yet
- Partial Differential Equation Part C Upto 21octDocument7 pagesPartial Differential Equation Part C Upto 21octaayush.5.parasharNo ratings yet
- Ajms 482 23Document7 pagesAjms 482 23BRNSS Publication Hub InfoNo ratings yet
- The Curvature in Classics PhysicsDocument8 pagesThe Curvature in Classics PhysicsMIGUEL LEONARDO AGUDELO B.No ratings yet
- GoldsteinDocument18 pagesGoldsteinAli RazaNo ratings yet
- Brief overview of an essentially adequate notion of quaternionic holomorphic functionsDocument6 pagesBrief overview of an essentially adequate notion of quaternionic holomorphic functionsMichail ParfenovNo ratings yet
- Solution 1Document12 pagesSolution 1benmenceur.kaissaNo ratings yet
- 872-892 Chapter 11Document26 pages872-892 Chapter 11kahinaNo ratings yet
- Chapter 3 - Solution To Worked ExamplesDocument4 pagesChapter 3 - Solution To Worked ExamplesJack LinesNo ratings yet
- Notes Phys300Document311 pagesNotes Phys300armagandgstnNo ratings yet
- c 44 d 075516012839610Document11 pagesc 44 d 075516012839610aakashbalaprajapathiofficialNo ratings yet
- 3 - WQU - 622 CTSP - M3 - CompiledContentDocument31 pages3 - WQU - 622 CTSP - M3 - CompiledContentJoe Ng100% (1)
- Discrepancy of Linear Recurring Sequences over Galois RingsDocument7 pagesDiscrepancy of Linear Recurring Sequences over Galois RingsChatchawan PanraksaNo ratings yet
- Section 5: Finite Volume Methods For The Navier Stokes EquationsDocument27 pagesSection 5: Finite Volume Methods For The Navier Stokes EquationsUmutcanNo ratings yet
- Linear Algebra (Lec - 13) Real Vector SpacesDocument6 pagesLinear Algebra (Lec - 13) Real Vector SpacesSamiul LesumNo ratings yet
- Lorentz Transformations: A Group Theory Approach: Neil & Pillon Erik October 21, 2017Document3 pagesLorentz Transformations: A Group Theory Approach: Neil & Pillon Erik October 21, 2017abbeyNo ratings yet
- Quantum Lecture-6-2021 Stationary Nondegenerate PerturbationDocument5 pagesQuantum Lecture-6-2021 Stationary Nondegenerate PerturbationKamal kumar SahooNo ratings yet
- The Stone-Von Neumann-Mackey Theorem: Quantum Mechanics in Functional AnalysisDocument15 pagesThe Stone-Von Neumann-Mackey Theorem: Quantum Mechanics in Functional AnalysisKeeley HoekNo ratings yet
- Convex Set: Dimension of A Convex Set Convex Hull Convex CombinationDocument15 pagesConvex Set: Dimension of A Convex Set Convex Hull Convex CombinationIamINNo ratings yet
- Lecture 4 - LADocument5 pagesLecture 4 - LARafat Hasan DipuNo ratings yet
- Taylor's SeriesDocument4 pagesTaylor's Seriesdibakarde72No ratings yet
- F 11 Place 2Document8 pagesF 11 Place 2paimoNo ratings yet
- Finite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationDocument6 pagesFinite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Chapter 6 PDFDocument31 pagesChapter 6 PDF黃昱宸No ratings yet
- The Line Integral of The Scalar Field: Math301 Summary (A. Fathy)Document3 pagesThe Line Integral of The Scalar Field: Math301 Summary (A. Fathy)Mohammed KhalilNo ratings yet
- 1.5 Vector AlgebraDocument8 pages1.5 Vector Algebra七海未来No ratings yet
- End-Sem – July-Nov 2020 (30th DecDocument2 pagesEnd-Sem – July-Nov 2020 (30th DecsssNo ratings yet
- The Pulled Spool: by Henrik Berg Department of Engineering and Physics Analytical Mechanics - FYGB08 December, 2016Document19 pagesThe Pulled Spool: by Henrik Berg Department of Engineering and Physics Analytical Mechanics - FYGB08 December, 2016omkarNo ratings yet
- Analytical Current-Voltage Model For Gate-All-Around Transistor With Poly-Crystalline Silicon ChannelDocument11 pagesAnalytical Current-Voltage Model For Gate-All-Around Transistor With Poly-Crystalline Silicon Channel전종욱No ratings yet
- H Optimization and H Infinity OptimizationDocument13 pagesH Optimization and H Infinity OptimizationKenneth LandichoNo ratings yet
- 3D Dynamics - 0102 - Fundamentals of Kinematics - Orthogonal Coordinate FramesDocument5 pages3D Dynamics - 0102 - Fundamentals of Kinematics - Orthogonal Coordinate Framessangram6957No ratings yet
- Cross ProductDocument14 pagesCross ProductHamid RajpootNo ratings yet
- Control ProblemsDocument3 pagesControl Problemsengenius infoNo ratings yet
- Designing A System of 3 Interconnected Tanks To Control Water LevelDocument15 pagesDesigning A System of 3 Interconnected Tanks To Control Water LevelperiNo ratings yet
- State Space ModelingDocument42 pagesState Space ModelingShojeb ShojolNo ratings yet
- Aircraft Stability and Control - Lec07Document9 pagesAircraft Stability and Control - Lec07Akeel AliNo ratings yet
- Controllability For A Wave Equation With Moving BoundaryDocument7 pagesControllability For A Wave Equation With Moving Boundary37 TANNUNo ratings yet
- QuestionsVertechy MoMfADocument95 pagesQuestionsVertechy MoMfASalvatore BamundoNo ratings yet
- Synthesis AerodynamicsDocument12 pagesSynthesis AerodynamicsMarcoNo ratings yet
- SM 38Document109 pagesSM 38ayushNo ratings yet
- Machine Problem Contents PDF FreeDocument23 pagesMachine Problem Contents PDF FreePedro Ian QuintanillaNo ratings yet
- Easy Notes On Mechanics Moment of Inertia PDFDocument48 pagesEasy Notes On Mechanics Moment of Inertia PDFFaisal Shabbir0% (2)
- Noteson Constructions Rev 4Document6 pagesNoteson Constructions Rev 4ouahba.zaghmaneNo ratings yet
- Worksheet4 SolutionDocument6 pagesWorksheet4 SolutionhartejtapiaNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Partial Catalytic Hydrogenation of Acetylene Converter)Document10 pagesPartial Catalytic Hydrogenation of Acetylene Converter)jmgwooNo ratings yet
- Msds PropaneDocument8 pagesMsds Propaneregina pramuditaNo ratings yet
- Memo 5 Baru ReskiDocument38 pagesMemo 5 Baru Reskiregina pramuditaNo ratings yet
- TK 411 - Plant Design: Minutes of Meeting Form For Group ProjectDocument1 pageTK 411 - Plant Design: Minutes of Meeting Form For Group Projectregina pramuditaNo ratings yet
- BT CompotitionDocument16 pagesBT Compotitionregina pramuditaNo ratings yet
- Memo 5 PambagianDocument1 pageMemo 5 Pambagianregina pramuditaNo ratings yet
- Naoh PDFDocument5 pagesNaoh PDFS KambleNo ratings yet
- Memo 5 PambagianDocument1 pageMemo 5 Pambagianregina pramuditaNo ratings yet
- Daftar Alat-Alat ARRDD Co. LengkapDocument2 pagesDaftar Alat-Alat ARRDD Co. Lengkapregina pramuditaNo ratings yet
- 9 10 F (X) - 0.5x + 9.2 R 0.2840909091: Axis TitleDocument6 pages9 10 F (X) - 0.5x + 9.2 R 0.2840909091: Axis Titleregina pramuditaNo ratings yet
- Data Boiling Point & AntoinneDocument1 pageData Boiling Point & Antoinneregina pramuditaNo ratings yet
- Jadwal Semester 4 (Januari 2017 - Juni 2017) Senin Selasa RabuDocument4 pagesJadwal Semester 4 (Januari 2017 - Juni 2017) Senin Selasa Raburegina pramuditaNo ratings yet
- TK 411 - Plant Design: Minutes of Meeting Form For Group ProjectDocument1 pageTK 411 - Plant Design: Minutes of Meeting Form For Group Projectregina pramuditaNo ratings yet
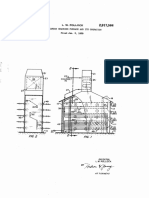
- Dec. 15, 1959 L. W. Pollock 2,917,564: Hydrocarbon Cracking Furnace and Its Operation Filed Jan. 5, 1959Document6 pagesDec. 15, 1959 L. W. Pollock 2,917,564: Hydrocarbon Cracking Furnace and Its Operation Filed Jan. 5, 1959regina pramuditaNo ratings yet
- Fuel PropertiesDocument22 pagesFuel PropertiesGilberto YoshidaNo ratings yet
- Naphthacracking 120907055612 Phpapp02Document22 pagesNaphthacracking 120907055612 Phpapp02regina pramuditaNo ratings yet
- Memo 2 Yang Harus DikerjakanDocument2 pagesMemo 2 Yang Harus Dikerjakanregina pramuditaNo ratings yet
- Us 3392211Document3 pagesUs 3392211regina pramuditaNo ratings yet
- Cracking Furnace Oil/ Water Quench Compresor Demathanaizer Metana HidrogenDocument2 pagesCracking Furnace Oil/ Water Quench Compresor Demathanaizer Metana Hidrogenregina pramuditaNo ratings yet
- TK 411 - Plant Design: Confidential Peer Assessment FormDocument1 pageTK 411 - Plant Design: Confidential Peer Assessment Formregina pramuditaNo ratings yet
- Pilot SimDocument13 pagesPilot Simregina pramuditaNo ratings yet
- Us 2498806Document7 pagesUs 2498806regina pramuditaNo ratings yet
- Estadisticas Opep 2016Document128 pagesEstadisticas Opep 2016Juan PabloNo ratings yet
- Naphtha Ms DsDocument14 pagesNaphtha Ms Dsregina pramuditaNo ratings yet
- Tugas Kelompok Kelas A ROI, BEP, DCF, NPV, IRRDocument30 pagesTugas Kelompok Kelas A ROI, BEP, DCF, NPV, IRRregina pramuditaNo ratings yet
- Production Method A. "Ethylene From Ethanol Process"Document2 pagesProduction Method A. "Ethylene From Ethanol Process"regina pramuditaNo ratings yet
- Alpine Newbie - Alpine LinuxDocument4 pagesAlpine Newbie - Alpine LinuxBengt FrostNo ratings yet
- LOEWE Certos Service ManualDocument79 pagesLOEWE Certos Service Manualroberto100% (6)
- How Do I Read My Friend'S Whatsapp Chat Without Taking His Phone?Document6 pagesHow Do I Read My Friend'S Whatsapp Chat Without Taking His Phone?Mahesh KumarNo ratings yet
- Public Key Infrastructure 101Document130 pagesPublic Key Infrastructure 101Robin RohitNo ratings yet
- Abstract-An Analog Circuit For The Fitzhugh-Nagumo Equations IsDocument5 pagesAbstract-An Analog Circuit For The Fitzhugh-Nagumo Equations Isneel1237No ratings yet
- MSP430 C Compiler Programming GuideDocument242 pagesMSP430 C Compiler Programming Guidecharles_sieNo ratings yet
- STEM Activity: Makey MakeyDocument14 pagesSTEM Activity: Makey Makeypreeti0505No ratings yet
- Reset Hikvision NVR or Camera in Under 40 StepsDocument6 pagesReset Hikvision NVR or Camera in Under 40 StepsDinesh Ramjuttun100% (1)
- Three-Dimensional Static and Dynamic Analysis of Structures: Edward L. WilsonDocument20 pagesThree-Dimensional Static and Dynamic Analysis of Structures: Edward L. WilsonManuel FloresNo ratings yet
- SQL Server 2008 Replication Technical Case StudyDocument44 pagesSQL Server 2008 Replication Technical Case StudyVidya SagarNo ratings yet
- CODESYS Application Composer enDocument3 pagesCODESYS Application Composer enCarlalberto VermiNo ratings yet
- Assign2 F15Document5 pagesAssign2 F15Lindsey HoffmanNo ratings yet
- Solution Manual For Concepts of Database Management 9th Edition Joy L Starks Philip J Pratt Mary Z LastDocument36 pagesSolution Manual For Concepts of Database Management 9th Edition Joy L Starks Philip J Pratt Mary Z Lastbuffyycleped3j28100% (41)
- Online Book Store Database Design and ScriptsDocument14 pagesOnline Book Store Database Design and ScriptsTushar ShelakeNo ratings yet
- USB Download Version 1.3 Release Notes PDFDocument2 pagesUSB Download Version 1.3 Release Notes PDFCarlos HurtadoNo ratings yet
- Moe-Llava: Mixture of Experts For Large Vision-Language ModelsDocument22 pagesMoe-Llava: Mixture of Experts For Large Vision-Language Models2136 SANTHOSHINo ratings yet
- Quest HW1 SolutionsDocument6 pagesQuest HW1 Solutionsellie<3No ratings yet
- StressFree Sketching Week 1 Assignment LTDocument2 pagesStressFree Sketching Week 1 Assignment LTMariana BelhamNo ratings yet
- Alg Linear Axminusbeqc All PDFDocument20 pagesAlg Linear Axminusbeqc All PDFNurulNo ratings yet
- Home Automation System ReportDocument5 pagesHome Automation System ReportAkanksha BoseNo ratings yet
- Trina Solar - Installation ManualDocument13 pagesTrina Solar - Installation ManualJuan HolandaNo ratings yet
- Purposive Communication: Module 7: Communication For Various PurposesDocument11 pagesPurposive Communication: Module 7: Communication For Various PurposesKatherine Marie BerouNo ratings yet
- IDPSDocument12 pagesIDPSمطيع برهومNo ratings yet
- Kaloji Narayana Rao University of Health Sciences, Telangana:: WarangalDocument4 pagesKaloji Narayana Rao University of Health Sciences, Telangana:: WarangalManiDeep ReddyNo ratings yet
- Guardian Unlimited - Weekend - Jon Ronson Meets Hacker Gary McKinnon PDFDocument7 pagesGuardian Unlimited - Weekend - Jon Ronson Meets Hacker Gary McKinnon PDFJOHN TSOUREKINo ratings yet
- Siminar SajaDocument29 pagesSiminar SajaMarwan CompNo ratings yet
- User Manual - Export Data From SAP To Excel v2.0Document12 pagesUser Manual - Export Data From SAP To Excel v2.0Jenny DwiNo ratings yet
- Buzon. en Cuarentena Microsoft - Exchange.data - StorageDocument4 pagesBuzon. en Cuarentena Microsoft - Exchange.data - StorageLuis SotoNo ratings yet
- WALK THE TALK - Mission235 - by Omar YoussefDocument149 pagesWALK THE TALK - Mission235 - by Omar YoussefOmar YoussefNo ratings yet
- Week 31 10 ICTDocument65 pagesWeek 31 10 ICTGhadeer AlkhayatNo ratings yet