You might also like
- 03 - Hapticity of SpaceDocument7 pages03 - Hapticity of SpaceAltrerosje Asri NgastowoNo ratings yet
- Grotesque Aesthetic in Architecture and FilmDocument17 pagesGrotesque Aesthetic in Architecture and FilmAltrerosje Asri NgastowoNo ratings yet
- Alexander1965A City Is Not A Tree PDFDocument22 pagesAlexander1965A City Is Not A Tree PDFmolhodepimentapirataNo ratings yet
- Semar - Javanese Aesthetic PhilosophyDocument7 pagesSemar - Javanese Aesthetic PhilosophyAltrerosje Asri NgastowoNo ratings yet
- Juhani Pallasmaa Architecture and NeuroscienceDocument11 pagesJuhani Pallasmaa Architecture and Neuroscienceandjela111180% (10)
- Place of Consciousness: Lived Space in Architecture and CinemaDocument30 pagesPlace of Consciousness: Lived Space in Architecture and CinemaAltrerosje Asri NgastowoNo ratings yet
- GLOBALIZATION: A HISTORY OF INCREASING CONNECTIVITYDocument6 pagesGLOBALIZATION: A HISTORY OF INCREASING CONNECTIVITYAltrerosje Asri NgastowoNo ratings yet
- Architectural GenomicsDocument8 pagesArchitectural GenomicsAltrerosje Asri NgastowoNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- UAS Writing For Discourse - 4 Pagi OkDocument1 pageUAS Writing For Discourse - 4 Pagi Oksalwa syabinaNo ratings yet
- Natamycin Story - What You Need to KnowDocument13 pagesNatamycin Story - What You Need to KnowCharles MardiniNo ratings yet
- 421 Reproduction Developmental Toxicity Screening TestDocument10 pages421 Reproduction Developmental Toxicity Screening TestAshishNo ratings yet
- The "Five Families" College Essay ExampleDocument1 pageThe "Five Families" College Essay ExampleKishor RaiNo ratings yet
- 8 Cell - The Unit of Life-NotesDocument6 pages8 Cell - The Unit of Life-NotesBhavanya RavichandrenNo ratings yet
- Poultry Science MCQDocument12 pagesPoultry Science MCQelanthamizhmaran83% (6)
- LearnerDocument7 pagesLearnersudhacarhrNo ratings yet
- Lab Exercise 0ne: Carbohydrate Analysis Lab A.1 (Page 28)Document31 pagesLab Exercise 0ne: Carbohydrate Analysis Lab A.1 (Page 28)Goh Kae HorngNo ratings yet
- Conference on Global Issues in Agricultural, Environmental and Forestry SciencesDocument16 pagesConference on Global Issues in Agricultural, Environmental and Forestry SciencesShirish NarnawareNo ratings yet
- Significance of 4D Printing For Dentistry: Materials, Process, and PotentialsDocument9 pagesSignificance of 4D Printing For Dentistry: Materials, Process, and PotentialsMohamed FaizalNo ratings yet
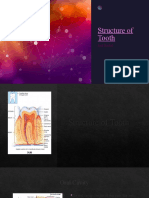
- Structure of Tooth m121Document13 pagesStructure of Tooth m121amirhossein vaeziNo ratings yet
- Behaviour of Great Apes Studied by Three Female ScientistsDocument12 pagesBehaviour of Great Apes Studied by Three Female ScientistsSani AhmadNo ratings yet
- Eagles and Eaglets gr2Document2 pagesEagles and Eaglets gr2vovanmtcNo ratings yet
- Dna Finger PrintingDocument23 pagesDna Finger PrintingSanjay KumarNo ratings yet
- Botany AssignmentDocument35 pagesBotany AssignmentLakshmiNo ratings yet
- 02 Anatomy and Histology PLE 2019 RatioDocument69 pages02 Anatomy and Histology PLE 2019 RatioPatricia VillegasNo ratings yet
- Advt - R-09-2023 WT ResultDocument16 pagesAdvt - R-09-2023 WT ResultAvinash Kumar SinghNo ratings yet
- Noscapine - British PharmacopoeiaDocument3 pagesNoscapine - British PharmacopoeiaSocial Service (V)No ratings yet
- Short Periods of Incubation During Egg Storage - SPIDESDocument11 pagesShort Periods of Incubation During Egg Storage - SPIDESPravin SamyNo ratings yet
- Follicular Dynamics in Bovine and Ovine 1Document19 pagesFollicular Dynamics in Bovine and Ovine 1israr yousafNo ratings yet
- BIO 192 Lab Report #1 BivalveDocument8 pagesBIO 192 Lab Report #1 BivalveBen KillamNo ratings yet
- Protein Structure and Function Book ReviewDocument1 pageProtein Structure and Function Book ReviewBrunoNo ratings yet
- Science Holidays Homework Class 9Document2 pagesScience Holidays Homework Class 9nileshNo ratings yet
- The Antibacterial Properties of Isothiocyanates PDFDocument15 pagesThe Antibacterial Properties of Isothiocyanates PDFSasicha DoungsuwanNo ratings yet
- Biodiversity & StabilityDocument76 pagesBiodiversity & StabilityMAXINE CLAIRE CUTINGNo ratings yet
- Flowering PlantsDocument43 pagesFlowering Plantskingbanakon100% (1)
- Sample Lab ReportDocument7 pagesSample Lab ReportPutri Syalieyana0% (1)
- Transport Phenomena in Nervous System PDFDocument538 pagesTransport Phenomena in Nervous System PDFUdayanidhi RNo ratings yet
- Advanced Level Biology 2015 Marking SchemeDocument29 pagesAdvanced Level Biology 2015 Marking SchemeAngiee FNo ratings yet
- Explaining Butterfly MetamorphosisDocument13 pagesExplaining Butterfly MetamorphosisCipe drNo ratings yet