You might also like
- (All India Tour Operator & Travel Agent) : Samyuktha Tours & Travels (Regd)Document6 pages(All India Tour Operator & Travel Agent) : Samyuktha Tours & Travels (Regd)Vasantha KumariNo ratings yet
- (WWW - Entrance Exam - Net) TcsDocument22 pages(WWW - Entrance Exam - Net) TcsAsim SiddiquiNo ratings yet
- QuestionsDocument2 pagesQuestionsVasantha KumariNo ratings yet
- PCD Internal3Document1 pagePCD Internal3Vasantha KumariNo ratings yet
- Data Structures and Object Oriented Programming in C++ Unit - Ii Advanced Object Oriented ProgrammingDocument32 pagesData Structures and Object Oriented Programming in C++ Unit - Ii Advanced Object Oriented ProgrammingVasantha KumariNo ratings yet
- RDBMS Concepts: How Many Numbers Are Divisible by 100 From 1 To 20 NoneDocument8 pagesRDBMS Concepts: How Many Numbers Are Divisible by 100 From 1 To 20 NoneVasantha KumariNo ratings yet
- RDBMS Concepts: How Many Numbers Are Divisible by 100 From 1 To 20 NoneDocument8 pagesRDBMS Concepts: How Many Numbers Are Divisible by 100 From 1 To 20 NoneVasantha KumariNo ratings yet
- Unit 4Document30 pagesUnit 4Vasantha KumariNo ratings yet
- Operating System QuestionsDocument3 pagesOperating System QuestionsVasantha KumariNo ratings yet
- SsDocument6 pagesSsVasantha KumariNo ratings yet
- Department of CSE Department of CSEDocument1 pageDepartment of CSE Department of CSEVasantha KumariNo ratings yet
- System Software LabDocument63 pagesSystem Software LabVasantha KumariNo ratings yet
- C. Inserting XML Documents in An Integer ColumnDocument19 pagesC. Inserting XML Documents in An Integer ColumnVasantha KumariNo ratings yet
- DBMS LAB EXERCISESDocument13 pagesDBMS LAB EXERCISESvasanthi201457% (14)
- Ec 2202 Data Structures and Object Oriented Programming in C++ Unit Iii Data Structures & Algorithms 3.1. AlgorithmDocument36 pagesEc 2202 Data Structures and Object Oriented Programming in C++ Unit Iii Data Structures & Algorithms 3.1. AlgorithmVasantha KumariNo ratings yet
- One Day National Level Workshop On: "Grid Integration Challenges in Renewable Energy Sources and Prospective Solutions"Document2 pagesOne Day National Level Workshop On: "Grid Integration Challenges in Renewable Energy Sources and Prospective Solutions"Vasantha KumariNo ratings yet
- Data Structures and Object Oriented Programming in C++: Unit-IDocument40 pagesData Structures and Object Oriented Programming in C++: Unit-IVasantha KumariNo ratings yet
- On Theory of Computation Session Schedule B R E A K L U N C H B R E A KDocument2 pagesOn Theory of Computation Session Schedule B R E A K L U N C H B R E A KVasantha KumariNo ratings yet
- Exam Centre: Direct Recruitment To The Post of Ae Elec/ Mech/Civil Hall TicketDocument1 pageExam Centre: Direct Recruitment To The Post of Ae Elec/ Mech/Civil Hall TicketVasantha KumariNo ratings yet
- Batches Aug 4 11 (NotFinalised)Document4 pagesBatches Aug 4 11 (NotFinalised)Vasantha KumariNo ratings yet
- DB2 Associate Mock Test Time Duration: 1 Hr. 30 Min. Passing Percentage: 60Document11 pagesDB2 Associate Mock Test Time Duration: 1 Hr. 30 Min. Passing Percentage: 60Vasantha KumariNo ratings yet
- Anna University FDTP on Theory of Computation RegistrationDocument3 pagesAnna University FDTP on Theory of Computation RegistrationVasantha KumariNo ratings yet
- IBM DB2 Mock3Q&ADocument2 pagesIBM DB2 Mock3Q&AVasantha KumariNo ratings yet
- IBM DB2 Academic Certification Update For Faculty v2 PDFDocument9 pagesIBM DB2 Academic Certification Update For Faculty v2 PDFVasantha KumariNo ratings yet
- DB2 Associate Mock Test 3Document7 pagesDB2 Associate Mock Test 3Reddy PurushothamNo ratings yet
- 5 Inter Process Communication Using PipesDocument2 pages5 Inter Process Communication Using PipesVasantha KumariNo ratings yet
- Exam Centre: Direct Recruitment To The Post of Ae Elec/ Mech/Civil Hall TicketDocument1 pageExam Centre: Direct Recruitment To The Post of Ae Elec/ Mech/Civil Hall TicketVasantha KumariNo ratings yet
- 5 Inter Process Communication Using PipesDocument2 pages5 Inter Process Communication Using PipesVasantha KumariNo ratings yet
- 15 06 24 09 43 12 3306 RajkumarDocument40 pages15 06 24 09 43 12 3306 RajkumarVasantha KumariNo ratings yet
- Implementation of Producer-Consumer Problem Using Semaphores ProgramDocument2 pagesImplementation of Producer-Consumer Problem Using Semaphores ProgramVasantha KumariNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Rationals, Irrationals and Continued FractionsDocument17 pagesRationals, Irrationals and Continued Fractionsaditya devNo ratings yet
- NSS Mathematics in Action (2nd Edition) 4A Section Worksheets 5 More about PolynomialsDocument2 pagesNSS Mathematics in Action (2nd Edition) 4A Section Worksheets 5 More about PolynomialsChing Kiu ChuNo ratings yet
- Mastery Test in Math 10 - Q1Document3 pagesMastery Test in Math 10 - Q1DennisEstrellosoAlbiso100% (2)
- 3.1 3.4 3.5 Buku WeiDocument2 pages3.1 3.4 3.5 Buku WeiMaritaNadyahNo ratings yet
- Chords RegionsDocument3 pagesChords RegionswillygopeNo ratings yet
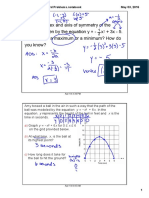
- 10.10 Quad Functions Word ProblemsDocument3 pages10.10 Quad Functions Word Problemsswapnil parmarNo ratings yet
- Worksheet 2 (18BCA1083)Document9 pagesWorksheet 2 (18BCA1083)Deepanshu ChoudharyNo ratings yet
- AICTE Vol. - 1 - PG-2018Document394 pagesAICTE Vol. - 1 - PG-2018Damodar ReddyNo ratings yet
- Permutation & Combination Theory - EDocument9 pagesPermutation & Combination Theory - Ethinkiit100% (1)
- ECS 170 Artificial IntelligenceDocument2 pagesECS 170 Artificial IntelligenceMahesh RaghvaniNo ratings yet
- Graph types - undirected, simple, multigraph, directedDocument3 pagesGraph types - undirected, simple, multigraph, directedpallavi mahajanNo ratings yet
- PSEUDOPRIMES: Probable Primes That Are Actually CompositeDocument10 pagesPSEUDOPRIMES: Probable Primes That Are Actually CompositeyeshaNo ratings yet
- MG 02 1 FiniteAutomata AnimDocument12 pagesMG 02 1 FiniteAutomata AnimSanny Era Eliza SiallaganNo ratings yet
- Assignment 1Document2 pagesAssignment 1lauraNo ratings yet
- Lec3 Graph RepresentationDocument11 pagesLec3 Graph Representationindranil konerNo ratings yet
- Error Control Coding Fundamentals and Applications by Shu Lin PDFDocument2 pagesError Control Coding Fundamentals and Applications by Shu Lin PDFMaggie0% (1)
- Graphing Polynomials ws1Document6 pagesGraphing Polynomials ws1devikaNo ratings yet
- Numbers Aptitude Concepts and Formulas: Points To RememberDocument8 pagesNumbers Aptitude Concepts and Formulas: Points To RememberDeepankar SrivastavaNo ratings yet
- Quantum Information Lecture Notes by John PreskillDocument329 pagesQuantum Information Lecture Notes by John PreskillAlexandr TrotskyNo ratings yet
- NumbersDocument97 pagesNumbersvenugopalNo ratings yet
- Heap SortDocument2 pagesHeap SortJemmyNo ratings yet
- (MAA 4.10) BINOMIAL DISTRIBUTION - SolutionsDocument4 pages(MAA 4.10) BINOMIAL DISTRIBUTION - Solutionsvarsha.sundarNo ratings yet
- GBFS 10 21Document5 pagesGBFS 10 21Mohammad JubayerNo ratings yet
- Hamiltonian CircuitsDocument89 pagesHamiltonian CircuitslogNo ratings yet
- Algorithm Design TechniquesDocument24 pagesAlgorithm Design TechniquespermasaNo ratings yet
- Python Practical FIleDocument12 pagesPython Practical FIleAkshansh Kumar0% (1)
- Gamma Fourier KummerDocument6 pagesGamma Fourier KummerPatrick Gabriel FloresNo ratings yet
- Index and LogDocument15 pagesIndex and LogSuresh Rao AppannahNo ratings yet
- Library GenesisDocument7 pagesLibrary Genesishans hansenNo ratings yet
- Maximum Happiness from Daily ActivitiesDocument68 pagesMaximum Happiness from Daily ActivitiesNikitaNo ratings yet