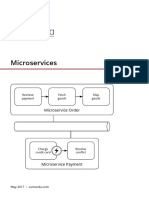
You might also like
- Six Simple RulesDocument50 pagesSix Simple RulesBardo Salgado100% (3)
- Nexus Book PDFDocument446 pagesNexus Book PDFAndrea MartireNo ratings yet
- A Concise Guide to Microservices for Executive (Now for DevOps too!)From EverandA Concise Guide to Microservices for Executive (Now for DevOps too!)Rating: 1 out of 5 stars1/5 (1)
- Mastering Microservices With ContainersDocument5 pagesMastering Microservices With ContainersManeesh DarisiNo ratings yet
- Micro Service ArchitectureDocument58 pagesMicro Service Architectureprathip100% (1)
- Microservice Architecture TutorialDocument47 pagesMicroservice Architecture TutorialMarcos Seibert100% (2)
- Decoding Microservices Best Practices Handbook For Developers 2022Document7 pagesDecoding Microservices Best Practices Handbook For Developers 2022luisclauNo ratings yet
- Java 9 High PerformanceDocument541 pagesJava 9 High PerformanceI Gede Tirtanata100% (1)
- It SopDocument42 pagesIt SopMoe Kaungkin100% (1)
- Emailreceipt AT&TDocument1 pageEmailreceipt AT&TMichel Gandhi100% (2)
- Best Practices in Implementing A Secure Microservices ArchitectureDocument85 pagesBest Practices in Implementing A Secure Microservices Architecturewenapo100% (1)
- Ebook Reactive Microservices The Evolution of Microservices at Scale 2 PDFDocument84 pagesEbook Reactive Microservices The Evolution of Microservices at Scale 2 PDFananth_rk100% (1)
- The Real-Time APIsDocument42 pagesThe Real-Time APIsWallie BillingsleyNo ratings yet
- The Process of Software Architecting PDFDocument390 pagesThe Process of Software Architecting PDFJOSE DAVID BAYONA RODRIGUEZ100% (1)
- RESTful APIs, Microservices and Service MeshesDocument15 pagesRESTful APIs, Microservices and Service MeshesVikas VSNo ratings yet
- CQRS: Event Processing To Query-DatabasesDocument47 pagesCQRS: Event Processing To Query-DatabasesMartijn BlankestijnNo ratings yet
- Event-Driven MicroservicesDocument25 pagesEvent-Driven MicroservicesKarthik KumarNo ratings yet
- WP - Best Practices For Microservices Whitepaper ResearchDocument47 pagesWP - Best Practices For Microservices Whitepaper ResearchPauline TykochinskyNo ratings yet
- Applying Domain-Driven Design and Patterns - With Examples in C#Document613 pagesApplying Domain-Driven Design and Patterns - With Examples in C#brench2100% (3)
- Software Architecture For Developers SampleDocument93 pagesSoftware Architecture For Developers SampleNirmal Singh TomarNo ratings yet
- How To Pass A Silicon Valley Software InterviewDocument95 pagesHow To Pass A Silicon Valley Software Interviewphulam146No ratings yet
- Testing MicroservicesDocument28 pagesTesting MicroservicesMalikg100% (1)
- Cloud Application Architecture Guide EN GB PDFDocument329 pagesCloud Application Architecture Guide EN GB PDFkiran100% (1)
- Engineering Micro FrontendsDocument19 pagesEngineering Micro FrontendsRahul GaurNo ratings yet
- Qs Up Questions 9Document32 pagesQs Up Questions 9Corina Nour0% (2)
- Data Oriented Architecture (Joshi)Document54 pagesData Oriented Architecture (Joshi)Pratul DubeNo ratings yet
- Using Microservices and Event Driven Architecture For Big Data Stream ProcessingDocument9 pagesUsing Microservices and Event Driven Architecture For Big Data Stream ProcessingAmine BesrourNo ratings yet
- A Sample Mini Supermarket Business Plan Template - ProfitableVentureDocument1 pageA Sample Mini Supermarket Business Plan Template - ProfitableVentureMaruff Mohd50% (2)
- White Paper Architects Guide To Implementing Event Driven ArchitectureDocument31 pagesWhite Paper Architects Guide To Implementing Event Driven Architecturemsu chennaiNo ratings yet
- Java/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandJava/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Domain Driven DesignDocument46 pagesDomain Driven DesignmojamcpdsNo ratings yet
- TOGAF V91 M7 MetamodelDocument23 pagesTOGAF V91 M7 Metamodelkunalb09No ratings yet
- Building Microservices With .NET CoreDocument21 pagesBuilding Microservices With .NET CoreMohammed KhanjriNo ratings yet
- Securing Microservice APIsDocument51 pagesSecuring Microservice APIsDenis ConnollyNo ratings yet
- Awesome .NET Core Genvio - References-for-Developers Wiki GitHubDocument12 pagesAwesome .NET Core Genvio - References-for-Developers Wiki GitHubArun KumarNo ratings yet
- Microservices On AWS: December 2016Document42 pagesMicroservices On AWS: December 2016ThườngNhẫnNo ratings yet
- Devops and MicroservicesDocument37 pagesDevops and Microservicesokello pablo100% (1)
- Microservice Architecture For The Enterprise PDFDocument14 pagesMicroservice Architecture For The Enterprise PDFaldan63No ratings yet
- CQRS and Event SourcingDocument8 pagesCQRS and Event SourcingopmsxxNo ratings yet
- Cracking Microservices Interview: Learn Advance Concepts, Patterns, Best Practices, NFRs, Frameworks, Tools and DevOpsFrom EverandCracking Microservices Interview: Learn Advance Concepts, Patterns, Best Practices, NFRs, Frameworks, Tools and DevOpsRating: 3 out of 5 stars3/5 (1)
- Software Architecture For Developers SampleDocument29 pagesSoftware Architecture For Developers SampleDironNo ratings yet
- Project Plan - Sauce & SpoonDocument49 pagesProject Plan - Sauce & SpoonAdakuNo ratings yet
- Milktea System Docu Chapter 1 5Document26 pagesMilktea System Docu Chapter 1 5Innovator Adrian100% (1)
- 5Cztxs Microservices 2017 enDocument18 pages5Cztxs Microservices 2017 enManuel VegaNo ratings yet
- Architecture Design and PatternsDocument14 pagesArchitecture Design and PatternsUsama bin Abdul Wahid100% (1)
- Beyond The 12-Factor App PivotalDocument72 pagesBeyond The 12-Factor App Pivotal백예균No ratings yet
- RefCardz - Getting Started With MicroservicesDocument6 pagesRefCardz - Getting Started With MicroservicesajulienNo ratings yet
- Overview DDD N-Layered Architecture (4h Workshop)Document91 pagesOverview DDD N-Layered Architecture (4h Workshop)Ricardo Martins Neves100% (1)
- Microservices Vs Service Oriented ArchitectureDocument57 pagesMicroservices Vs Service Oriented Architecturercoca_1100% (3)
- 426 Spring SecurityDocument1 page426 Spring SecuritykeytasksNo ratings yet
- Microservices For Everyone Sample PDFDocument49 pagesMicroservices For Everyone Sample PDFJelena MalinovićNo ratings yet
- Micro ServicesDocument92 pagesMicro ServicesMuditNo ratings yet
- Microservices RecipesDocument37 pagesMicroservices RecipesJoel Andy Rojas ValenciaNo ratings yet
- CQRSDocument97 pagesCQRSNelssonJoséSalvadorNo ratings yet
- Microservice PatternDocument1 pageMicroservice PatternHari Haran M100% (1)
- Patterns and Practices: MicroservicesDocument42 pagesPatterns and Practices: MicroservicesIlama Sto100% (1)
- How To Build Microservices: Top 10 Hacks To Modeling, Integrating & Deploying Microservices: The Blokehead Success SeriesFrom EverandHow To Build Microservices: Top 10 Hacks To Modeling, Integrating & Deploying Microservices: The Blokehead Success SeriesRating: 1 out of 5 stars1/5 (1)
- Architectures You Ve Always Wondered About EMagDocument37 pagesArchitectures You Ve Always Wondered About EMagMichael LiangNo ratings yet
- Microservices ArchitectureDocument23 pagesMicroservices Architecturebetatester1No ratings yet
- Manufacturing Planning and Control For Supply Chain Management 6th Edition Jacobs Solutions ManualDocument22 pagesManufacturing Planning and Control For Supply Chain Management 6th Edition Jacobs Solutions Manualoutscoutumbellar.2e8na100% (21)
- Arcitura Microservice ArchitectDocument20 pagesArcitura Microservice Architecttest test0% (2)
- Split Into MicroservicesDocument68 pagesSplit Into MicroservicesKicrut KerenNo ratings yet
- Spring Integration in ActionDocument2 pagesSpring Integration in ActionDreamtech PressNo ratings yet
- Microservice Architecture: A Seminar Report OnDocument28 pagesMicroservice Architecture: A Seminar Report OnrupaliNo ratings yet
- Micro ServicesDocument2 pagesMicro ServicesNitesh KumarNo ratings yet
- Calvin Sigmod12 PDFDocument12 pagesCalvin Sigmod12 PDFdeepeshNo ratings yet
- Enterprise Integration Patterns (OSGi Container)Document78 pagesEnterprise Integration Patterns (OSGi Container)IBRAHIM CANDIR100% (1)
- Happiness TransformingtheDevelopmentLandscapeDocument481 pagesHappiness TransformingtheDevelopmentLandscapeTeja Kamal0% (1)
- Scope Machine Learning2014Document1 pageScope Machine Learning2014Teja KamalNo ratings yet
- Dependency Injection: November 2012Document19 pagesDependency Injection: November 2012Teja KamalNo ratings yet
- Kerala - God'S Own Country: Day 01: COCHIN To MUNNAR 140KM, 4Hrs DriveDocument2 pagesKerala - God'S Own Country: Day 01: COCHIN To MUNNAR 140KM, 4Hrs DriveTeja KamalNo ratings yet
- PING September2010finalDocument7 pagesPING September2010finalTeja KamalNo ratings yet
- CS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityDocument58 pagesCS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityTeja KamalNo ratings yet
- 01 MapreduceDocument77 pages01 MapreduceTeja KamalNo ratings yet
- Programming Languages Dan Grossman 2013: Nested FunctionsDocument5 pagesProgramming Languages Dan Grossman 2013: Nested FunctionsTeja KamalNo ratings yet
- 004 This Course 2Document8 pages004 This Course 2Teja KamalNo ratings yet
- Hibernate PresentationDocument68 pagesHibernate PresentationTeja KamalNo ratings yet
- Wal-Mart Retail Management: A Project ReportDocument80 pagesWal-Mart Retail Management: A Project Reportsantosh1354No ratings yet
- Requisitions & Direct OrdersDocument4 pagesRequisitions & Direct Ordersrajesh_d84No ratings yet
- Mba (M&S) Sem IvDocument18 pagesMba (M&S) Sem IvthakurprashantNo ratings yet
- Bamboo Processing Factory ProposalDocument46 pagesBamboo Processing Factory ProposalNana Kofi Bimpong IINo ratings yet
- 1.14 Networks: Intranet Local Log Onto Network Card Satellite Server Terminals WAN (Wide Area Network)Document2 pages1.14 Networks: Intranet Local Log Onto Network Card Satellite Server Terminals WAN (Wide Area Network)EDWARD LUIS HUAYLLASCO CARLOSNo ratings yet
- An Overview of The Regulatory Framework of FinTech in Nigeria - Fin Tech - Nigeria PDFDocument9 pagesAn Overview of The Regulatory Framework of FinTech in Nigeria - Fin Tech - Nigeria PDFAjiboye TooniNo ratings yet
- Jncia FWVDocument2 pagesJncia FWVJeffrey Albert CaandiNo ratings yet
- Demystifying The World of Oracle Payments in R12 How To Handle Credit & Debit Card CapturesDocument54 pagesDemystifying The World of Oracle Payments in R12 How To Handle Credit & Debit Card Captures1lvlup UpmanNo ratings yet
- FICO Transaction CodesDocument64 pagesFICO Transaction Codessaregama200565No ratings yet
- Foodworld Learnings C07Document2 pagesFoodworld Learnings C07Anadi MitraNo ratings yet
- OFBiz POS User Manual - Version 9.11Document24 pagesOFBiz POS User Manual - Version 9.11shibubabu123No ratings yet
- Manual JavaPOS MSR English V1.04Document7 pagesManual JavaPOS MSR English V1.04CORTOLIMANo ratings yet
- POSBANK A10 Thermal Receipt PrinterDocument19 pagesPOSBANK A10 Thermal Receipt PrinterPOSBank USANo ratings yet
- Wanda POS Installation Guide v2Document18 pagesWanda POS Installation Guide v2SpeedyKazamaNo ratings yet
- RMO 21-2015 FT Final PDFDocument6 pagesRMO 21-2015 FT Final PDFGoogleNo ratings yet
- ChecklistforAuditing-ApplicationDocument2 pagesChecklistforAuditing-ApplicationPiggylek LekpiggyNo ratings yet
- Final ReportDocument18 pagesFinal ReportNikki TaklikarNo ratings yet
- POS Printer Driver V8.11 Installation Instruction ManualDocument20 pagesPOS Printer Driver V8.11 Installation Instruction ManualinformaticahmhaNo ratings yet
- Retail Distribution ChannelDocument18 pagesRetail Distribution ChannelhelloNo ratings yet
- Cash Disbursements ProceduresDocument13 pagesCash Disbursements ProceduresSheila Mae AramanNo ratings yet
- IS438 Tutorial1 DimensionalModeling ExercicesDocument3 pagesIS438 Tutorial1 DimensionalModeling Exercicesniram_sugriyaNo ratings yet
- Bluekode Account ProfileDocument12 pagesBluekode Account ProfileJOOOOONo ratings yet