You might also like
- Architectures RISC Et ExemplesDocument6 pagesArchitectures RISC Et ExemplesjuniorNo ratings yet
- Notes de Cours Calculateurs - Interfacage - Chap 1 - 2Document27 pagesNotes de Cours Calculateurs - Interfacage - Chap 1 - 2Амр ХашмиNo ratings yet
- MAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsFrom EverandMAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsNo ratings yet
- TEJ3M U1 011 ProcesseurDocument23 pagesTEJ3M U1 011 ProcesseurTsiory RanaivosonNo ratings yet
- Chapitre I Architecture Générale de L'unité Centrale D'un OrdinateurDocument22 pagesChapitre I Architecture Générale de L'unité Centrale D'un OrdinateurOuramdaneNo ratings yet
- Architecture de Base D'un Ordinateur Premiere PartieDocument52 pagesArchitecture de Base D'un Ordinateur Premiere PartieElena GlNo ratings yet
- Chapitre 2Document13 pagesChapitre 2Mehdi SellamiNo ratings yet
- l2 Info Corrigé Architecture Des OrdinateursDocument3 pagesl2 Info Corrigé Architecture Des OrdinateursJai AbdoNo ratings yet
- Manuel Chap1+2Document54 pagesManuel Chap1+2Oum MahdiNo ratings yet
- Chapitre 1 Et Chapitre 2 AODocument42 pagesChapitre 1 Et Chapitre 2 AOÑį HăđNo ratings yet
- Cours SE Complet PDFDocument90 pagesCours SE Complet PDFalonsop100% (1)
- Gestion de Processus Kacha FinDocument42 pagesGestion de Processus Kacha FinHind Smith100% (1)
- Intro TD6Document5 pagesIntro TD6sialgroupNo ratings yet
- Sequence DemarrageDocument14 pagesSequence DemarrageZikas Winners100% (1)
- Cours Système DexploitationDocument24 pagesCours Système DexploitationbilalNo ratings yet
- TP #1 Montage Et Démontage D'un PCDocument15 pagesTP #1 Montage Et Démontage D'un PCnourNo ratings yet
- Resume Du Module 17 Architecture Et Fonctionnement Dun Reseau InformatiqueDocument2 pagesResume Du Module 17 Architecture Et Fonctionnement Dun Reseau InformatiqueyounesrguigNo ratings yet
- Exercices Commandes Ms Dos PDF CompressDocument2 pagesExercices Commandes Ms Dos PDF CompressAvahouin NicaiseNo ratings yet
- Chap6 EntréesSortiesDocument39 pagesChap6 EntréesSortiesJuba MadriNo ratings yet
- Chap3 MémoiresSéquentielles+FIFO+LIFODocument11 pagesChap3 MémoiresSéquentielles+FIFO+LIFOJuba Madri50% (2)
- Cours Systemes EmbarquesDocument66 pagesCours Systemes EmbarquesDesigner BrainNo ratings yet
- La Pagination, La Segmentation Et La Mémoire Virtuelle PDFDocument11 pagesLa Pagination, La Segmentation Et La Mémoire Virtuelle PDFLePrinceNo ratings yet
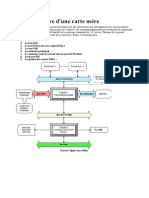
- Structure de Base Dun OrdinateurDocument5 pagesStructure de Base Dun OrdinateurRazi GuemNo ratings yet
- Le ProcesseurDocument10 pagesLe ProcesseuralikaciliNo ratings yet
- 1 Introduction Aux Système D ExploitationDocument6 pages1 Introduction Aux Système D ExploitationEbondjeKilyanDanyNo ratings yet
- Sujets Exposés Architecture Ord AP10 FDocument5 pagesSujets Exposés Architecture Ord AP10 FFatima-ezzahraa Ben bouazzaNo ratings yet
- Architecture Des OrdinateursDocument28 pagesArchitecture Des OrdinateursPop HamdiNo ratings yet
- Le ProcesseurDocument4 pagesLe ProcesseurjamilNo ratings yet
- 00 Architecture Et Maintenance Des Ordinateurs 2020Document151 pages00 Architecture Et Maintenance Des Ordinateurs 2020JoëlNo ratings yet
- Cours Système D'exploitation1Document79 pagesCours Système D'exploitation1saadiNo ratings yet
- Test de Linux Administration - Cic-2021Document1 pageTest de Linux Administration - Cic-2021Dandiégou KOMBATENo ratings yet
- Cours ScriptDocument7 pagesCours ScriptDjo MounirNo ratings yet
- Chipsets Et BusDocument9 pagesChipsets Et BusSellé GueyeNo ratings yet
- Historique Et Structure MachineDocument13 pagesHistorique Et Structure MachineMi MaNo ratings yet
- TP1 ProcessusDocument10 pagesTP1 ProcessusABID HananeNo ratings yet
- TD Maintenance InformatiqueDocument2 pagesTD Maintenance InformatiqueAbraham MusansNo ratings yet
- ProcesseursDocument30 pagesProcesseursalayassirNo ratings yet
- Examen en Maintenance Des OrdinateursDocument4 pagesExamen en Maintenance Des OrdinateursCHAIRMANNo ratings yet
- Chapitre 1Document25 pagesChapitre 1bouk omraNo ratings yet
- Facteurs D'encombrementDocument2 pagesFacteurs D'encombrementRana GhribiNo ratings yet
- TD Systèmes D EXPLOITATIONDocument2 pagesTD Systèmes D EXPLOITATIONmamadou dioufNo ratings yet
- TP N 2-LinuxDocument8 pagesTP N 2-Linuxbouki15No ratings yet
- Efm Afri 2014-2015Document4 pagesEfm Afri 2014-2015elmamoun1No ratings yet
- DEVOIR MAINTENANCE. - CopieDocument2 pagesDEVOIR MAINTENANCE. - CopieCRichard pulsingNo ratings yet
- ARCHITECTURE - DES - ORDINATEURS by AymaneDocument56 pagesARCHITECTURE - DES - ORDINATEURS by AymaneAymane AIT SOULTANANo ratings yet
- INFO 1 Ordinateur Periph Ecran CORRIGEDocument10 pagesINFO 1 Ordinateur Periph Ecran CORRIGEexgouNo ratings yet
- Chapitre 2 - Commandes de Gestion Des FichiersDocument19 pagesChapitre 2 - Commandes de Gestion Des FichiersArij KorkadNo ratings yet
- DéfinitionsDocument15 pagesDéfinitionsDälãs Francïø DylanëNo ratings yet
- SE Gestion MemoireDocument6 pagesSE Gestion MemoireFadwa ZedNo ratings yet
- Carte MèreDocument15 pagesCarte MèreBala BalaNo ratings yet
- TD 2 - Archi - SolDocument4 pagesTD 2 - Archi - SolYoucef BenjillaliNo ratings yet
- Chapitre 1: Introduction Aux MicroprocesseursDocument26 pagesChapitre 1: Introduction Aux MicroprocesseursAbir HammamiNo ratings yet
- Les Composants InternesDocument2 pagesLes Composants Interneslibandowski demNo ratings yet
- Système D'exploitation: 1. Généralités Sur Les OSDocument12 pagesSystème D'exploitation: 1. Généralités Sur Les OSexgouNo ratings yet
- Accès Direct À La MémoireDocument2 pagesAccès Direct À La Mémoireesty7534No ratings yet
- ArchitectureDocument12 pagesArchitecturemgsNo ratings yet
- Processeur PDFDocument10 pagesProcesseur PDFyoussefNo ratings yet
- Chapitre 4-1Document4 pagesChapitre 4-1Georges Le Mignon OleNo ratings yet
- TD1 STR Sas 111044Document2 pagesTD1 STR Sas 111044Karasuno GamingNo ratings yet
- Chap 2 Analyse Lexi CaleDocument17 pagesChap 2 Analyse Lexi CaleHarrag MahieddineNo ratings yet
- Electronique Et Loisirs N009Document75 pagesElectronique Et Loisirs N009mechergui100% (5)
- HGDFFDocument39 pagesHGDFFMâ JdåNo ratings yet
- Cour Sur Programmation Et LangagesDocument259 pagesCour Sur Programmation Et LangagesdjagoungraceNo ratings yet
- Documentation BME 2 v1Document30 pagesDocumentation BME 2 v1Aga RioNo ratings yet
- Cours D'initiation Informatique 2Document11 pagesCours D'initiation Informatique 2Bëlmôñd HclNo ratings yet
- ExceptionsDocument288 pagesExceptionsAymènNo ratings yet
- Chapitre 1-Cours de Java PDFDocument22 pagesChapitre 1-Cours de Java PDFmrcutNo ratings yet
- Projet MGL804 Iannick GagnonDocument23 pagesProjet MGL804 Iannick GagnonIaNickNo ratings yet
- Les Virus InformatiquesDocument11 pagesLes Virus InformatiquesisimgNo ratings yet
- Accord de ConfidentialitéDocument10 pagesAccord de ConfidentialitéJean FabriceNo ratings yet
- Projet Sfe Abir Final Abir PDFDocument106 pagesProjet Sfe Abir Final Abir PDFAbir Khriss100% (3)
- Cours InfoDocument42 pagesCours InfoRAMI HELAL100% (1)
- CoursDocument38 pagesCoursAFADNo ratings yet
- TD 3Document1 pageTD 3ossamaNo ratings yet
- ABB FOX515 Installation EnfrDocument37 pagesABB FOX515 Installation EnfrOUSSAMANo ratings yet
- Cours Microprocesseur MicroControleur M1 GI Chap 2Document13 pagesCours Microprocesseur MicroControleur M1 GI Chap 2Hassan MohamedNo ratings yet
- Installation Des Composants Dans Un Systã Me Automatisã©Document68 pagesInstallation Des Composants Dans Un Systã Me Automatisã©214043No ratings yet
- Familiarisation Avec Le Simulateur "8085 Simulator"Document15 pagesFamiliarisation Avec Le Simulateur "8085 Simulator"Med Djameleddine BougrineNo ratings yet
- Med Informatique1an28-AlgorithmeDocument8 pagesMed Informatique1an28-AlgorithmedidineNo ratings yet
- Cours Programmation Avancée Chapitre 2.complexiteDocument19 pagesCours Programmation Avancée Chapitre 2.complexiteDO UANo ratings yet
- MatlabDocument18 pagesMatlabRabeb BayoudhiNo ratings yet
- Cours 1 PL SQLDocument31 pagesCours 1 PL SQLkallelmohamed35No ratings yet
- Info S3 Prof Boukhriss by Ksimo MaureDocument85 pagesInfo S3 Prof Boukhriss by Ksimo MaureLinda ToumiNo ratings yet
- Assurance QualitéDocument62 pagesAssurance QualitéPatrick Ostertag100% (6)
- 1 ExerciceDocument9 pages1 Exercicetriocom223No ratings yet
- Cours LMDDocument57 pagesCours LMDLisa Lisa liliNo ratings yet
- FERHAOUI BouchraDocument66 pagesFERHAOUI BouchraAlex FezeuNo ratings yet
- TP OPNET EtudiantDocument7 pagesTP OPNET EtudiantSuley PatersonNo ratings yet
- Maths Livre 2ndDocument192 pagesMaths Livre 2ndmom77775% (8)