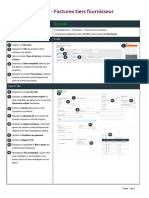
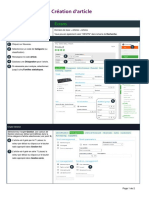
You might also like
- Matrice - Eisenhower - Les 5 Fondamentaux D'une Bonne Gestion Du TempsDocument8 pagesMatrice - Eisenhower - Les 5 Fondamentaux D'une Bonne Gestion Du TempssamirNo ratings yet
- Matrice - Eisenhower - Les 5 Fondamentaux D'une Bonne Gestion Du TempsDocument8 pagesMatrice - Eisenhower - Les 5 Fondamentaux D'une Bonne Gestion Du TempssamirNo ratings yet
- Support Formation Crystal Reports - Sage X3Document46 pagesSupport Formation Crystal Reports - Sage X3aloeveraabdoNo ratings yet
- VMware Vsphere Evaluation Guide 1Document106 pagesVMware Vsphere Evaluation Guide 1thp0001No ratings yet
- Chapitre 01 - Azure Principes de BasesDocument20 pagesChapitre 01 - Azure Principes de BasesAissatou YatteNo ratings yet
- Avantages Et Inconvã©nients de Mac OsDocument5 pagesAvantages Et Inconvã©nients de Mac Oshadjer mehNo ratings yet
- Les Fonctions Et Scripts Avancees Sous Power Shell Version 2Document67 pagesLes Fonctions Et Scripts Avancees Sous Power Shell Version 2kouza0% (1)
- Developpez en .Net Pour SharepointDocument287 pagesDeveloppez en .Net Pour SharepointadresserNo ratings yet
- Ad Windows Elkhadimi-2022Document289 pagesAd Windows Elkhadimi-2022abdou boulifNo ratings yet
- HTMLDocument22 pagesHTMLMERRY PARKERNo ratings yet
- Oracle PLSQLDocument105 pagesOracle PLSQLJhon WalkerNo ratings yet
- J2EE Web TierDocument126 pagesJ2EE Web TierAbdelmadjid BouamamaNo ratings yet
- TP Install Config WinServer MiseAjour PDFDocument36 pagesTP Install Config WinServer MiseAjour PDFBill Louis CharlesNo ratings yet
- Cours S1&S2 ADM Systeme L3 InformatiqueDocument51 pagesCours S1&S2 ADM Systeme L3 InformatiqueAli YussufNo ratings yet
- Support LPIC-201 EcranDocument172 pagesSupport LPIC-201 Ecranزياد بوزيريNo ratings yet
- Chapitre 4 SDNDocument27 pagesChapitre 4 SDNRaja Bensalem100% (2)
- VirtualisationDocument2 pagesVirtualisationTekayaNo ratings yet
- VMware ESXiDocument62 pagesVMware ESXidivictoryNo ratings yet
- Docker EvaluationDocument47 pagesDocker EvaluationPape Mignane FayeNo ratings yet
- TP - 1 SolutionDocument3 pagesTP - 1 Solutionferyal mrd100% (1)
- Exchange Server 2010 Préparation À La Certification MCTS 70-662Document615 pagesExchange Server 2010 Préparation À La Certification MCTS 70-662Stephane HubertNo ratings yet
- CR380 - Cours - 1Document53 pagesCR380 - Cours - 1simoo2010No ratings yet
- VX RailDocument4 pagesVX RailstaojrNo ratings yet
- Documentation Azure Active Directory - Microsoft DocsDocument4 pagesDocumentation Azure Active Directory - Microsoft DocsOussama HlaliNo ratings yet
- Projet Virtualisation Ouassine Elkhabich Lotfi Bougraine RaouziDocument33 pagesProjet Virtualisation Ouassine Elkhabich Lotfi Bougraine RaouziOuassine YounesNo ratings yet
- Install X3 V12 FOR210323Document61 pagesInstall X3 V12 FOR210323Othmane RaisNo ratings yet
- X3 AdonixDocument107 pagesX3 Adonixmivoc29No ratings yet
- TP Instructeur Linux NTDocument59 pagesTP Instructeur Linux NTstrideworldNo ratings yet
- VB.NETDocument352 pagesVB.NETJoseph EdwardsNo ratings yet
- Projet de Fin D'études: Implémentation D'une Solution NAC Avec Cisco ISE Anouar ABDALLAHDocument72 pagesProjet de Fin D'études: Implémentation D'une Solution NAC Avec Cisco ISE Anouar ABDALLAHAnouar ABDALLAH85% (52)
- Typo 3Document537 pagesTypo 3Ayoub Lamrani100% (1)
- 1cours VirtualisationDocument3 pages1cours VirtualisationAbdoul Aziz OUATTARANo ratings yet
- Bonnes Pratiques Configuration D'architecture PDFDocument14 pagesBonnes Pratiques Configuration D'architecture PDFKiesgenNo ratings yet
- VirtualisationDocument4 pagesVirtualisationمحمد الشيخاويNo ratings yet
- Linux - Lpi 101 - 1 - Materiel ArchitectureDocument19 pagesLinux - Lpi 101 - 1 - Materiel ArchitectureAmine BoubakeurNo ratings yet
- TP1 - Jasper Server & IreportDocument5 pagesTP1 - Jasper Server & IreportOmrani AchrafNo ratings yet
- NetBackup AdmGuide PDFDocument225 pagesNetBackup AdmGuide PDFMihajamananaNo ratings yet
- VMware iSCSI SAN Configuration Guide PG FRDocument124 pagesVMware iSCSI SAN Configuration Guide PG FRfouaksel100% (1)
- Tuto-IT Cluster VMWareDocument14 pagesTuto-IT Cluster VMWarejentaaoNo ratings yet
- Devenir Administrateur Systèmes - Bases, Installation Et Configuration de Windows Server 2019 - Gandal SmartDocument24 pagesDevenir Administrateur Systèmes - Bases, Installation Et Configuration de Windows Server 2019 - Gandal Smartmoisendiaye245No ratings yet
- CCTP Virtualisation Du SIDocument10 pagesCCTP Virtualisation Du SIBertin Bidias0% (1)
- SBR Demarrer FreemiumDocument14 pagesSBR Demarrer FreemiumFreddy SieweNo ratings yet
- Step by Step Guide of Report-To-Report Interface in BW ReportingDocument319 pagesStep by Step Guide of Report-To-Report Interface in BW Reportings.zeraoui1595No ratings yet
- 2010 - Editions Eni - Windows Powershell (v1 Et 2) - Guide de Référence Pour L'Administration SystèmeDocument477 pages2010 - Editions Eni - Windows Powershell (v1 Et 2) - Guide de Référence Pour L'Administration SystèmeisidroNo ratings yet
- BIRT GuideDocument60 pagesBIRT GuideLassaad Ben HadjNo ratings yet
- Data Domain Operating System 5.5 Administration GuideDocument408 pagesData Domain Operating System 5.5 Administration Guidefreddy_5725247No ratings yet
- NetBackup Troubleshoot GuideDocument356 pagesNetBackup Troubleshoot Guideysf.rootNo ratings yet
- Objectif Virtualisation Point Sur La VirtualisationDocument14 pagesObjectif Virtualisation Point Sur La VirtualisationYayaMamadouSangareNo ratings yet
- Sauvegarde Et Restauration Active DirectoryDocument16 pagesSauvegarde Et Restauration Active Directorycpm_phrhpa100% (1)
- Situation E4 Supervision Eon-NagiosDocument2 pagesSituation E4 Supervision Eon-Nagiosapi-306414104No ratings yet
- La VirtualisationDocument24 pagesLa VirtualisationEmma Mila100% (1)
- De L'infrastructure Virtuelle Au Cloud Privé Et HybrideDocument243 pagesDe L'infrastructure Virtuelle Au Cloud Privé Et HybrideGolinduche100% (1)
- Vsphere Esxi Vcenter Server 701 Setup WSFCDocument47 pagesVsphere Esxi Vcenter Server 701 Setup WSFCMustafa LAAOUIBINo ratings yet
- GlpiDocument261 pagesGlpileonNo ratings yet
- Topologie CPUDocument32 pagesTopologie CPUTitus Kernel MaestriaNo ratings yet
- 6 Structure Interne Des ProcesseursDocument10 pages6 Structure Interne Des ProcesseursNabila TouisiNo ratings yet
- Cours 2Document8 pagesCours 2Achraf HouilaNo ratings yet
- Rapport Finale 1Document26 pagesRapport Finale 1Slimen Mohamed SadokNo ratings yet
- Conception Des Systèmes de Mémoire1Document16 pagesConception Des Systèmes de Mémoire1Romaissa MessNo ratings yet
- Cours Calculateurs L2 InfoDocument85 pagesCours Calculateurs L2 InfoBajikila AmandNo ratings yet
- ProcesseurDocument4 pagesProcesseurfonfaron0% (1)
- AAP Chapitre 1Document30 pagesAAP Chapitre 1Gharsellaoui MuhamedNo ratings yet
- Exam CorrDocument5 pagesExam Corrlatifa benidder100% (1)
- Le ProcesseurDocument13 pagesLe ProcesseurCompte PiratéNo ratings yet
- AP Ar Accounting Direct Payment Receipt EntryDocument2 pagesAP Ar Accounting Direct Payment Receipt EntrysamirNo ratings yet
- AP Ar Accounting Bank EntryDocument2 pagesAP Ar Accounting Bank EntrysamirNo ratings yet
- Ap Ar Accounting Bank Entry PDFDocument1 pageAp Ar Accounting Bank Entry PDFsamirNo ratings yet
- Sales Proforma InvoiceDocument2 pagesSales Proforma InvoicesamirNo ratings yet
- AP Ar Accounting Bank ReconciliationDocument2 pagesAP Ar Accounting Bank ReconciliationsamirNo ratings yet
- AP Ar Accounting Bank EntryDocument1 pageAP Ar Accounting Bank EntrysamirNo ratings yet
- AP Ar Accounting Automatic Remittance CreationDocument2 pagesAP Ar Accounting Automatic Remittance CreationsamirNo ratings yet
- AP Ar Accounting Supplier BP InvoicesDocument2 pagesAP Ar Accounting Supplier BP InvoicessamirNo ratings yet
- AP Ar Accounting Bank PostingDocument2 pagesAP Ar Accounting Bank PostingsamirNo ratings yet
- Common Data - Product CreationDocument2 pagesCommon Data - Product CreationsamirNo ratings yet
- Common Data - Product-Site CreationDocument2 pagesCommon Data - Product-Site CreationsamirNo ratings yet
- Purchase Price SearchDocument1 pagePurchase Price SearchsamirNo ratings yet
- Purchase Receipt Creation For Non-Stocked ProductsDocument1 pagePurchase Receipt Creation For Non-Stocked ProductssamirNo ratings yet
- Purchase Order CreationDocument2 pagesPurchase Order CreationsamirNo ratings yet
- Common Data - Product-Site CreationDocument2 pagesCommon Data - Product-Site CreationsamirNo ratings yet
- Purchase InquiriesDocument2 pagesPurchase InquiriessamirNo ratings yet
- Common Data - Product-Site Creation PDFDocument2 pagesCommon Data - Product-Site Creation PDFsamirNo ratings yet
- Installation de L Agent Fusion Inventrory WindowsDocument10 pagesInstallation de L Agent Fusion Inventrory WindowssamirNo ratings yet
- Common Data - Account CreationDocument2 pagesCommon Data - Account CreationsamirNo ratings yet
- Common Data - Product-Site Creation PDFDocument2 pagesCommon Data - Product-Site Creation PDFsamirNo ratings yet
- Common Data - User CreationDocument2 pagesCommon Data - User CreationsamirNo ratings yet
- Common Data - User CreationDocument2 pagesCommon Data - User CreationsamirNo ratings yet
- Common Data - Product-Site CreationDocument2 pagesCommon Data - Product-Site CreationsamirNo ratings yet
- Common Data - User CreationDocument2 pagesCommon Data - User CreationsamirNo ratings yet
- Tutoriel FRST - Farbar Recovery Scanner ToolDocument83 pagesTutoriel FRST - Farbar Recovery Scanner ToolsamirNo ratings yet
- Common Data - User CreationDocument2 pagesCommon Data - User CreationsamirNo ratings yet
- 10 Cas Usage AlfrescoDocument15 pages10 Cas Usage AlfrescoPrince Godasse OkitemboNo ratings yet
- Révision Prosit 2 ConvertiDocument46 pagesRévision Prosit 2 ConvertiSarah Ben BelaidNo ratings yet
- ManuelDocument28 pagesManuelÖxygene PurNo ratings yet
- Filiere-Ingenieur-Ingenierie Informatique-Big Data Et Cloud Computing Ii-BdccDocument4 pagesFiliere-Ingenieur-Ingenierie Informatique-Big Data Et Cloud Computing Ii-Bdccwww.toudaliNo ratings yet
- Administration Systeme Unix 1Document17 pagesAdministration Systeme Unix 1Daaray Cheikhoul XadimNo ratings yet
- UE 1 Environnement Systeme ExploitationDocument2 pagesUE 1 Environnement Systeme ExploitationHarold TSOBDJOUNo ratings yet
- TexaDocument20 pagesTexaAndrea FilottoNo ratings yet
- Doro PhoneEasy 612Document74 pagesDoro PhoneEasy 612Ramy LamalyNo ratings yet
- PFA2Document20 pagesPFA2Firas KACHROUDINo ratings yet
- Comment Créer Un Logiciel PortableDocument7 pagesComment Créer Un Logiciel PortableBoussad Nait MessaoudNo ratings yet
- Initiation 2 TIA Portal MS1Document24 pagesInitiation 2 TIA Portal MS1Anbari MehdiNo ratings yet
- H010G Formation Ibm Platform LSF Configuration de Base Et Administration Pour Linux PDFDocument1 pageH010G Formation Ibm Platform LSF Configuration de Base Et Administration Pour Linux PDFCertyouFormationNo ratings yet
- Nouveau Document Microsoft WordDocument2 pagesNouveau Document Microsoft WordHamou WaltNo ratings yet
- Manuel D'utilisation Imprimante HPDocument190 pagesManuel D'utilisation Imprimante HPGérald KouakouNo ratings yet
- Travaux PratiqueDocument58 pagesTravaux Pratiqueelie kabondoNo ratings yet
- Comparatif Des Différents Systèmes D'exploitationsDocument2 pagesComparatif Des Différents Systèmes D'exploitationsAbdoul IslamyNo ratings yet
- Samsung SSD Data Migration User Manual French Revision v6Document21 pagesSamsung SSD Data Migration User Manual French Revision v6Benjamin LangaudNo ratings yet
- Eco Alexa Ecran 02Document14 pagesEco Alexa Ecran 02claudesgetelciNo ratings yet
- Rapport de Stage - SRFCDocument22 pagesRapport de Stage - SRFCMorgan TrémoureuxNo ratings yet
- 01 Cours Complet Apprendre Orchestrateur Kubernetes k8sDocument6 pages01 Cours Complet Apprendre Orchestrateur Kubernetes k8sChristian BiboueNo ratings yet
- SYSTEME - FicheDocument2 pagesSYSTEME - Fichekenza boufamaNo ratings yet
- Catalogue HP ProliantDocument192 pagesCatalogue HP ProliantJean-Pierre KouameNo ratings yet
- Atome Pédagogique 1Document29 pagesAtome Pédagogique 1JoëlNo ratings yet
- Le Port SérieDocument9 pagesLe Port SérierabahNo ratings yet
- TD1 Ordonancement PDFDocument2 pagesTD1 Ordonancement PDFYouSsef YsfNo ratings yet
- Presentation ArduinoDocument16 pagesPresentation ArduinotestNo ratings yet
- Administration en Ligne de Commande Indiquer QuellesDocument3 pagesAdministration en Ligne de Commande Indiquer QuellesradouaneNo ratings yet
- TD TP OS-LinuxDocument10 pagesTD TP OS-LinuxNael Le BayonNo ratings yet