You might also like
- ETP48300-C6D2 Embedded Power User Manual PDFDocument94 pagesETP48300-C6D2 Embedded Power User Manual PDFjose benedito f. pereira100% (1)
- Business Plan - Docx 3-Star Hospitality and Tourism Devt Centre in Mbarara - UgandaDocument49 pagesBusiness Plan - Docx 3-Star Hospitality and Tourism Devt Centre in Mbarara - UgandaInfiniteKnowledge100% (9)
- Corephotonics Dual-Camera LawsuitDocument53 pagesCorephotonics Dual-Camera LawsuitMikey CampbellNo ratings yet
- Embedded CoderDocument8 pagesEmbedded Coderجمال طيبيNo ratings yet
- Parallel Processing: Breaking Complex Problems into Smaller PiecesDocument8 pagesParallel Processing: Breaking Complex Problems into Smaller PiecesToobaNo ratings yet
- Artificial IntelligenceDocument12 pagesArtificial IntelligenceHimanshu MishraNo ratings yet
- Computer cluster computing explainedDocument5 pagesComputer cluster computing explainedshaheen sayyad 463No ratings yet
- Parallel ProcessingDocument4 pagesParallel Processingnikhilesh walde100% (1)
- CS02DOS Unit 1UNit - 1 IntroductionDocument6 pagesCS02DOS Unit 1UNit - 1 IntroductionSalar AhmedNo ratings yet
- ACA Assignment 4Document16 pagesACA Assignment 4shresth choudharyNo ratings yet
- Unit-1 OsDocument9 pagesUnit-1 Osbharathijawahar583No ratings yet
- Parallel and Distributed Computing AssignmentDocument5 pagesParallel and Distributed Computing AssignmentUmerNo ratings yet
- Microcomputer: MainframeDocument5 pagesMicrocomputer: MainframejoelchaleNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- Lectures on distributed systems introductionDocument8 pagesLectures on distributed systems introductionaj54321No ratings yet
- Flynn's Classification and Types of Computer ArchitecturesDocument36 pagesFlynn's Classification and Types of Computer ArchitecturesAnujNo ratings yet
- 1 of 1 PDFDocument7 pages1 of 1 PDFpatasutoshNo ratings yet
- PCA Chapter 1: Flynn's Classification and Parallel Processing ModelsDocument61 pagesPCA Chapter 1: Flynn's Classification and Parallel Processing ModelsAYUSH KUMARNo ratings yet
- UNIT 2 cloud computingDocument18 pagesUNIT 2 cloud computingRajput ShreeyaNo ratings yet
- A Taxonomy of Distributed SystemsDocument11 pagesA Taxonomy of Distributed SystemssdfjsdsdvNo ratings yet
- HPC NotesDocument24 pagesHPC NotesShadowOPNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Unit 6 - Computer Organization and Architecture - WWW - Rgpvnotes.inDocument14 pagesUnit 6 - Computer Organization and Architecture - WWW - Rgpvnotes.inNandini SharmaNo ratings yet
- Multi-Core Processors: Page 1 of 25Document25 pagesMulti-Core Processors: Page 1 of 25nnNo ratings yet
- Serial and Parallel First 3 LectureDocument17 pagesSerial and Parallel First 3 LectureAsif KhanNo ratings yet
- Solved Assignment - Parallel ProcessingDocument29 pagesSolved Assignment - Parallel ProcessingNoor Mohd Azad63% (8)
- Parallel Computig AssignmentDocument15 pagesParallel Computig AssignmentAnkitmauryaNo ratings yet
- Cluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKDocument34 pagesCluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKNishshanka CJNo ratings yet
- Advanced Computer ArchitectureDocument28 pagesAdvanced Computer ArchitectureSameer KhudeNo ratings yet
- Multiprocessor Architecture SystemDocument10 pagesMultiprocessor Architecture SystemManmeet RajputNo ratings yet
- Two criteria and examples of advanced operating systemsDocument27 pagesTwo criteria and examples of advanced operating systemsdevil angelNo ratings yet
- Chapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesDocument41 pagesChapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesraghvendrmNo ratings yet
- A Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)Document8 pagesA Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Parallel Processing in LINUX (PareshDocument13 pagesParallel Processing in LINUX (PareshDIPAK VINAYAK SHIRBHATENo ratings yet
- Unit 1 OsDocument13 pagesUnit 1 OsUma MaheswariNo ratings yet
- Introduction To Parallel Computing: John Von Neumann Institute For ComputingDocument18 pagesIntroduction To Parallel Computing: John Von Neumann Institute For Computingsandeep_nagar29No ratings yet
- ACA UNIT-5 NotesDocument15 pagesACA UNIT-5 Notespraveennegiuk07No ratings yet
- Lecture 1 Thay TuDocument87 pagesLecture 1 Thay Tuapi-3801193100% (1)
- Unit-1 Cloud Computing (Nep) PDFDocument36 pagesUnit-1 Cloud Computing (Nep) PDFbehiro7856100% (1)
- SIMD Vs MIMD With Memory ModelsDocument7 pagesSIMD Vs MIMD With Memory Modelssonal yadavNo ratings yet
- Distributed Computing ExplainedDocument6 pagesDistributed Computing ExplainedMiguel Gabriel FuentesNo ratings yet
- Os TypesDocument43 pagesOs TypesVivek KumarNo ratings yet
- Mca - Unit IiiDocument59 pagesMca - Unit IiiVivek DubeyNo ratings yet
- L2Document27 pagesL2chhabra_amit78No ratings yet
- Parallel Algorithm - Intro and Computational ModelsDocument5 pagesParallel Algorithm - Intro and Computational ModelszololuxyNo ratings yet
- Computer Architecture and OrganizationDocument15 pagesComputer Architecture and OrganizationpoonamNo ratings yet
- PG Cloud Computing Unit IIDocument52 pagesPG Cloud Computing Unit IIdeepthi sanjeevNo ratings yet
- Lecture Week - 2 General Parallelism TermsDocument24 pagesLecture Week - 2 General Parallelism TermsimhafeezniaziNo ratings yet
- Swami Vivekananda Institute of Science &: TechnologyDocument8 pagesSwami Vivekananda Institute of Science &: Technologyamit BeraNo ratings yet
- Distributed SystemDocument53 pagesDistributed SystemAdarsh Srivastava100% (1)
- Jimma University: Jimma Institute of Technology Faculty of ComputingDocument7 pagesJimma University: Jimma Institute of Technology Faculty of ComputingadmachewNo ratings yet
- COME6102 Chapter 1 Introduction 2 of 2Document8 pagesCOME6102 Chapter 1 Introduction 2 of 2Franck TiomoNo ratings yet
- Notes Distributed System Unit 1Document38 pagesNotes Distributed System Unit 1rahul koravNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- PDS Assignment 01Document3 pagesPDS Assignment 01M Shahzaib AliNo ratings yet
- Cloud ComputingDocument27 pagesCloud ComputingmanojNo ratings yet
- Flynn's Taxonomy of Computer ArchitectureDocument8 pagesFlynn's Taxonomy of Computer ArchitectureRajani SurejaNo ratings yet
- Evolution of Operating SystemsDocument3 pagesEvolution of Operating Systemsপ্রাণেশ দেবনাথNo ratings yet
- Models of Network ComputingDocument2 pagesModels of Network ComputingMohammad Waqas JauharNo ratings yet
- 3a FlynnsDocument17 pages3a FlynnsHitarth Anand RohraNo ratings yet
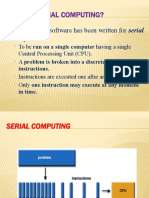
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOperating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Digital Electronics, Computer Architecture and Microprocessor Design PrinciplesFrom EverandDigital Electronics, Computer Architecture and Microprocessor Design PrinciplesNo ratings yet
- GFRDDocument9 pagesGFRDLalit NagarNo ratings yet
- CSCE 3110 Data Structures and Algorithms NotesDocument19 pagesCSCE 3110 Data Structures and Algorithms NotesAbdul SattarNo ratings yet
- Auditing For Managers - The Ultimate Risk Management ToolDocument369 pagesAuditing For Managers - The Ultimate Risk Management ToolJason SpringerNo ratings yet
- (DO-CYT-T1-16) - KASSAHUN ComparisionDocument126 pages(DO-CYT-T1-16) - KASSAHUN ComparisionMohammed AdaneNo ratings yet
- November 2022 Examination: Indian Institution of Industrial Engineering Internal Assignment For IIIE StudentsDocument19 pagesNovember 2022 Examination: Indian Institution of Industrial Engineering Internal Assignment For IIIE Studentssatish gordeNo ratings yet
- Engineering Ethics in Practice ShorterDocument79 pagesEngineering Ethics in Practice ShorterPrashanta NaikNo ratings yet
- HR PlanningDocument47 pagesHR PlanningPriyanka Joshi0% (1)
- BR18 Mechanical Engineering Robotics Semester VIDocument2 pagesBR18 Mechanical Engineering Robotics Semester VIPRAVEeNo ratings yet
- Conflict of Laws (Summary Paper)Document13 pagesConflict of Laws (Summary Paper)Anonymous CWcXthhZgxNo ratings yet
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- Mosfet PDFDocument13 pagesMosfet PDFTad-electronics TadelectronicsNo ratings yet
- Power Steering Rack Components and Auto Suppliers Reference GuideDocument12 pagesPower Steering Rack Components and Auto Suppliers Reference GuideJonathan JoelNo ratings yet
- NPTEL Web Course On Complex Analysis: A. SwaminathanDocument19 pagesNPTEL Web Course On Complex Analysis: A. SwaminathanMohit SharmaNo ratings yet
- Emiish Me: Answer BookDocument7 pagesEmiish Me: Answer BookNickNo ratings yet
- AGE-WELL Annual Report 2021-2022Document31 pagesAGE-WELL Annual Report 2021-2022Alexandra DanielleNo ratings yet
- Application For Freshman Admission - PDF UA & PDocument4 pagesApplication For Freshman Admission - PDF UA & PVanezza June DuranNo ratings yet
- Solved Problems: EEE 241 Computer ProgrammingDocument11 pagesSolved Problems: EEE 241 Computer ProgrammingŞemsettin karakuşNo ratings yet
- The Little Book of Deep Learning: An Introduction to Neural Networks, Architectures, and ApplicationsDocument142 pagesThe Little Book of Deep Learning: An Introduction to Neural Networks, Architectures, and Applicationszardu layakNo ratings yet
- Market & Industry Analysis CheckDocument2 pagesMarket & Industry Analysis CheckAndhika FarrasNo ratings yet
- 231025+ +JBS+3Q23+Earnings+Preview VFDocument3 pages231025+ +JBS+3Q23+Earnings+Preview VFgicokobayashiNo ratings yet
- Caf 8 Aud Spring 2022Document3 pagesCaf 8 Aud Spring 2022Huma BashirNo ratings yet
- HOS Dials in The Driver App - Samsara SupportDocument3 pagesHOS Dials in The Driver App - Samsara SupportMaryNo ratings yet
- QA InspectionDocument4 pagesQA Inspectionapi-77180770No ratings yet
- Request For Information (Rfi) : Luxury Villa at Isola Dana-09 Island - Pearl QatarDocument1 pageRequest For Information (Rfi) : Luxury Villa at Isola Dana-09 Island - Pearl QatarRahmat KhanNo ratings yet
- Banaue Rice Terraces - The Eighth WonderDocument2 pagesBanaue Rice Terraces - The Eighth Wonderokloy sanchezNo ratings yet
- Ibad Rehman CV NewDocument4 pagesIbad Rehman CV NewAnonymous ECcVsLNo ratings yet