You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Signal Flow GraphDocument48 pagesSignal Flow GraphsufyanNo ratings yet
- Tugas No. 1: Pengurutan AngkaDocument11 pagesTugas No. 1: Pengurutan AngkaLia NamikazeNo ratings yet
- FSP150-50LE Is An Industrial Level of Switching Power Supply - SpecificationDocument1 pageFSP150-50LE Is An Industrial Level of Switching Power Supply - SpecificationJohn HallowsNo ratings yet
- Peran Bumdes Dalam Pengelolaan Limbah Kelapa Sawit Di Desa Talang Jerinjing Kecamatan Rengat Barat Kabupaten Indragiri Hulu Provinsi RiauDocument11 pagesPeran Bumdes Dalam Pengelolaan Limbah Kelapa Sawit Di Desa Talang Jerinjing Kecamatan Rengat Barat Kabupaten Indragiri Hulu Provinsi RiauInnaka LestariNo ratings yet
- MikroTik Wireless Wire nRAYDocument3 pagesMikroTik Wireless Wire nRAYddddNo ratings yet
- Lyva Labs Manufacturing Cluster - SME Adoption of Advanced Manufacturing Technologies by Sujita PurushothamanDocument10 pagesLyva Labs Manufacturing Cluster - SME Adoption of Advanced Manufacturing Technologies by Sujita Purushothamansujita.purushothamanNo ratings yet
- Characterization of SPT Grain Size Effects in GravDocument9 pagesCharacterization of SPT Grain Size Effects in Gravstefanus fendisaNo ratings yet
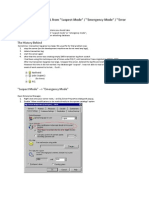
- How To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Document3 pagesHow To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Scott NeubauerNo ratings yet
- GUIDDocument215 pagesGUIDPrakashNo ratings yet
- TS80 Soldering Iron User Manual V1.1Document23 pagesTS80 Soldering Iron User Manual V1.1nigger naggerNo ratings yet
- 9 Android List and MapsDocument13 pages9 Android List and MapsMarichris VenturaNo ratings yet
- BDDocument3,102 pagesBDtedy yidegNo ratings yet
- Intel Inside.Document25 pagesIntel Inside.Rashed550% (1)
- Epayroll System: User ManualDocument66 pagesEpayroll System: User Manualvivek anandanNo ratings yet
- Ghid Automatizari SchneiderDocument372 pagesGhid Automatizari SchneidervalicanNo ratings yet
- IT0089 (Fundamentals of Analytics Modeling) : ExerciseDocument6 pagesIT0089 (Fundamentals of Analytics Modeling) : ExerciseAshley De JesusNo ratings yet
- Ccna MCQ 1 PDFDocument14 pagesCcna MCQ 1 PDFsreesree.b100% (1)
- Water Quality Monitoring Using Iot: Bachelor of EngineeringDocument19 pagesWater Quality Monitoring Using Iot: Bachelor of EngineeringMeghanaNo ratings yet
- Jabra Android SDK Developers GuideDocument12 pagesJabra Android SDK Developers GuideEmilio AlejandroNo ratings yet
- ISTQB Foundation Exam Format andDocument17 pagesISTQB Foundation Exam Format andapi-3806986No ratings yet
- Top 4 Reasons For Node EvictionDocument4 pagesTop 4 Reasons For Node EvictionIan HughesNo ratings yet
- AI QuestionsDocument2 pagesAI QuestionsNarender SinghNo ratings yet
- DeterminantsDocument1 pageDeterminantsJanakChandPNo ratings yet
- Quizlet-Quiz 1 Web Apps in OutsystemsDocument2 pagesQuizlet-Quiz 1 Web Apps in OutsystemsedymaradonaNo ratings yet
- Distributed Object System: Java - Remote Method Invocation (RMI) Remote Method Invocation (RMI)Document22 pagesDistributed Object System: Java - Remote Method Invocation (RMI) Remote Method Invocation (RMI)endaleNo ratings yet
- Foundations of Information Systems in BusinessDocument28 pagesFoundations of Information Systems in BusinessRaheel PunjwaniNo ratings yet
- The Rope Memory-A Permanent Storage DeviceDocument14 pagesThe Rope Memory-A Permanent Storage DevicePaul CultreraNo ratings yet
- Cut Over Activities - Plant Maintenance - SAP Easy Access - SAP BlogsDocument7 pagesCut Over Activities - Plant Maintenance - SAP Easy Access - SAP BlogsOmprakashNo ratings yet
- Gaussian Filtering FpgaDocument7 pagesGaussian Filtering Fpgaakkala vikasNo ratings yet
- Ii. Literature Review: 2.1. Reclamation Bond ProvisionDocument45 pagesIi. Literature Review: 2.1. Reclamation Bond ProvisionRandy SyamNo ratings yet