You might also like
- Document SplittingDocument2 pagesDocument SplittingshastrycNo ratings yet
- Cost Object Controlling Variance CalculationDocument49 pagesCost Object Controlling Variance CalculationBhuvaneswaran KannaiyanNo ratings yet
- Cost Object Controlling Variance CalculationDocument49 pagesCost Object Controlling Variance CalculationBhuvaneswaran KannaiyanNo ratings yet
- Cost Object Controlling Variance CalculationDocument49 pagesCost Object Controlling Variance CalculationBhuvaneswaran KannaiyanNo ratings yet
- Cost Object Controlling Variance CalculationDocument49 pagesCost Object Controlling Variance CalculationBhuvaneswaran KannaiyanNo ratings yet
- New GLDocument1 pageNew GLshastrycNo ratings yet
- Idocs BasicsDocument3 pagesIdocs Basicskamran075No ratings yet
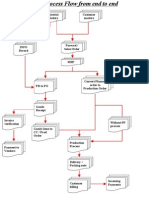
- SAP Process Flow From End To EndDocument1 pageSAP Process Flow From End To EndshastrycNo ratings yet
- Validation For FBTDocument6 pagesValidation For FBTshastrycNo ratings yet
- COPA Report TroubleshootDocument31 pagesCOPA Report TroubleshootshastrycNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- QuadToneRIP User GuideDocument26 pagesQuadToneRIP User Guidecolorestec28No ratings yet
- Auxiliary ProgramsDocument232 pagesAuxiliary Programsyk2brosNo ratings yet
- En ENBSP SDK Programmer's Guide COM With VBDocument45 pagesEn ENBSP SDK Programmer's Guide COM With VBJavier Medina PerezNo ratings yet
- H Sim TutorialDocument22 pagesH Sim TutorialLi Jarmouni IINo ratings yet
- Computer AbbreviationsDocument54 pagesComputer AbbreviationsIrfan KhanNo ratings yet
- HCM ExtractsDocument108 pagesHCM ExtractsMd AhmedNo ratings yet
- HDF5 Users GuideDocument342 pagesHDF5 Users GuideHugo Van RuyskensveldeNo ratings yet
- ANSYS Mechanical APDL Programmers ReferenceDocument398 pagesANSYS Mechanical APDL Programmers ReferenceFelipe QuevedoNo ratings yet
- Oracle WorkflowDocument122 pagesOracle WorkflowHowo4DieNo ratings yet
- Introduction to Oracle Reports DeveloperDocument10 pagesIntroduction to Oracle Reports Developerkaushik4endNo ratings yet
- An Automatic Carving Method For RAR File Based On Content and StructureDocument5 pagesAn Automatic Carving Method For RAR File Based On Content and StructureVicshannNo ratings yet
- Chapter 3 - Data AcquisitionDocument58 pagesChapter 3 - Data AcquisitionAndrew LeiNo ratings yet
- Rc008 Designpatterns OnlineDocument10 pagesRc008 Designpatterns OnlineSo OdetteNo ratings yet
- Csound ManualDocument489 pagesCsound ManualArtist RecordingNo ratings yet
- Cognos 10 Framework ManagerDocument635 pagesCognos 10 Framework ManagerclrhoadesNo ratings yet
- Trainz 2004 Content Creators GuideDocument185 pagesTrainz 2004 Content Creators GuideAndrei ChirilescuNo ratings yet
- WOWvx 3ds Max Plugin Leaflet 13779Document2 pagesWOWvx 3ds Max Plugin Leaflet 13779Marcelo BottaNo ratings yet
- Appendix E-Asset Handover Documents Am200-230Document16 pagesAppendix E-Asset Handover Documents Am200-230Garth GilmourNo ratings yet
- HAMMER Connect EditionDocument892 pagesHAMMER Connect EditionvethoNo ratings yet
- Dorey S J Useful Microsoft Word TechniquesDocument61 pagesDorey S J Useful Microsoft Word TechniquesАлексей ШевченкоNo ratings yet
- 04.1 Software Manual M2 Gen3 V2017 enDocument109 pages04.1 Software Manual M2 Gen3 V2017 enjoseph beckhamNo ratings yet
- CDISC 123 SasDocument12 pagesCDISC 123 SasKatti VenkataramanaNo ratings yet
- Pro Concrete V 18Document641 pagesPro Concrete V 18FrankGuo100% (1)
- Avaya CMS ECHI R14Document76 pagesAvaya CMS ECHI R14miloscosicNo ratings yet
- Understanding Document Accessibility 1579556195 PDFDocument850 pagesUnderstanding Document Accessibility 1579556195 PDFJhinsher TagleNo ratings yet
- AspenHYSYSRefiningV7 2 OpsDocument478 pagesAspenHYSYSRefiningV7 2 Opsnguyennha1211100% (1)
- MODENTDocument62 pagesMODENTsat0112No ratings yet
- Oracle® Retail Store Inventory Management: Operations Guide Release 13.1Document80 pagesOracle® Retail Store Inventory Management: Operations Guide Release 13.1orlandodeabreupNo ratings yet
- Amazon Kindle Publishing GuidelinesDocument62 pagesAmazon Kindle Publishing Guidelinesdand1234No ratings yet
- Pocket JourneyDocument92 pagesPocket JourneyzybotechsolutionsNo ratings yet