You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Chapter01 ArtDocument25 pagesChapter01 Artapi-3717234100% (1)
- CH03 Image+Enhancement+in+the+Spatial+DomainDocument42 pagesCH03 Image+Enhancement+in+the+Spatial+Domainapi-3717234100% (1)
- CH 14Document33 pagesCH 14api-3717234No ratings yet
- CH 09Document30 pagesCH 09api-3717234No ratings yet
- CH 17Document15 pagesCH 17api-3717234No ratings yet
- CH 07Document17 pagesCH 07api-3717234No ratings yet
- CH 15Document24 pagesCH 15api-3717234No ratings yet
- CH 20Document25 pagesCH 20api-3717234No ratings yet
- CH 18Document19 pagesCH 18api-3717234No ratings yet
- CH 16Document15 pagesCH 16api-3717234No ratings yet
- Software Engineering: A Practitioner's Approach, 6/eDocument18 pagesSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- Software Engineering: A Practitioner's Approach, 6/eDocument42 pagesSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- CH 05Document19 pagesCH 05api-3717234No ratings yet
- Software Engineering: A Practitioner's Approach, 6/eDocument74 pagesSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- CH 06Document18 pagesCH 06api-3717234No ratings yet
- CH 03Document12 pagesCH 03api-3717234No ratings yet
- CH 02Document13 pagesCH 02api-3717234No ratings yet
- CH 04Document17 pagesCH 04api-3717234No ratings yet
- CH 01Document11 pagesCH 01api-3717234No ratings yet
- World Knowledge and Fuzzy Logic-2004Document14 pagesWorld Knowledge and Fuzzy Logic-2004api-3717234No ratings yet
- Fuzzy Probabilities 1984Document10 pagesFuzzy Probabilities 1984api-3717234No ratings yet
- Fuzzy Basics PDFDocument38 pagesFuzzy Basics PDFSoumyadeep BoseNo ratings yet
- JCST Apr05 4Document6 pagesJCST Apr05 4api-3717234No ratings yet
- 37-The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning II-1975Document57 pages37-The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning II-1975Dr. Ir. R. Didin Kusdian, MT.No ratings yet
- Recognizing ConceptDocument8 pagesRecognizing Conceptapi-3717234No ratings yet
- Fuzzy Image RetrievalDocument5 pagesFuzzy Image Retrievalapi-3717234100% (1)
- The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning I-1975Document51 pagesThe Concept of A Linguistic Variable and Its Applications To Approximate Reasoning I-1975api-3717234100% (1)
- NLP NotesDocument31 pagesNLP Notesapi-3717234100% (5)
- Image RetrievalDocument12 pagesImage Retrievalapi-3717234No ratings yet
- Image CategorizationDocument27 pagesImage Categorizationapi-3717234No ratings yet
- Data Modeling Using The Entity-Relationship (ER) ModelDocument62 pagesData Modeling Using The Entity-Relationship (ER) ModelChala GetaNo ratings yet
- HipernateDocument4 pagesHipernateHARISH SNo ratings yet
- FN0038 - Option Button Survey ScoresDocument9 pagesFN0038 - Option Button Survey ScoresM.A.NNo ratings yet
- Retail Analytics - IRMADocument17 pagesRetail Analytics - IRMAKartik KaushikNo ratings yet
- Database Lesson NOtesDocument17 pagesDatabase Lesson NOtesCatherine DalafuNo ratings yet
- Bicc ExtractttDocument4 pagesBicc ExtractttashibekNo ratings yet
- SAP HANA Commvault Best PracticesDocument2 pagesSAP HANA Commvault Best PracticesDevender5194No ratings yet
- Oracle Database 10g: PL/SQL Fundamentals: Volume 2 - Additional PracticesDocument32 pagesOracle Database 10g: PL/SQL Fundamentals: Volume 2 - Additional PracticesvickyNo ratings yet
- Standalone and Rac Database Differences ClassnotesDocument3 pagesStandalone and Rac Database Differences ClassnotesManohar SankarNo ratings yet
- ProcobolDocument500 pagesProcobolRoberto de Gênova100% (1)
- Servicenow Interview QuestionsDocument9 pagesServicenow Interview QuestionsranjithgottimukkalaNo ratings yet
- Backing Up and Restoring Solaris OS with ufsdumpDocument3 pagesBacking Up and Restoring Solaris OS with ufsdumpinayatullah75No ratings yet
- Best Oracle DBA Interview Questions and Answers: Q1) How To Check Opatch Applied or Not in Our Oracle Home?Document15 pagesBest Oracle DBA Interview Questions and Answers: Q1) How To Check Opatch Applied or Not in Our Oracle Home?nassr50No ratings yet
- Database Testing Techniques and Best PracticesDocument21 pagesDatabase Testing Techniques and Best Practicesavumaa22No ratings yet
- Interbase vs. SQL ServerDocument7 pagesInterbase vs. SQL ServerteknograhaNo ratings yet
- SQL - Interview QuestionDocument15 pagesSQL - Interview QuestionDeepanshu SatijaNo ratings yet
- CommCell Performance TuningDocument21 pagesCommCell Performance TuningKunchi Praveena100% (1)
- Growing A Local Datastore From The Command Line in Vsphere ESXi (2002461)Document5 pagesGrowing A Local Datastore From The Command Line in Vsphere ESXi (2002461)MM CvNo ratings yet
- HDFS Interview Questions - Top 15 HDFS Questions AnsweredDocument29 pagesHDFS Interview Questions - Top 15 HDFS Questions Answeredanuja shindeNo ratings yet
- DBMS LaboratoryDocument21 pagesDBMS LaboratoryVijeth NarayanNo ratings yet
- SQL Server Ground To CloudDocument167 pagesSQL Server Ground To CloudPaul ZgondeaNo ratings yet
- DDB Server PDFDocument2 pagesDDB Server PDFnidee_nishokNo ratings yet
- Curs 1 - Arhitectura DB OracleDocument13 pagesCurs 1 - Arhitectura DB OracleManuela MariaNo ratings yet
- SQL Notes by Apna CollegeDocument29 pagesSQL Notes by Apna CollegeSiddhant Kumar100% (2)
- OracleStudy MaterialDocument376 pagesOracleStudy MaterialPriyanka Powar100% (1)
- YouTube SEO PDFDocument17 pagesYouTube SEO PDFMariam GevorgyanNo ratings yet
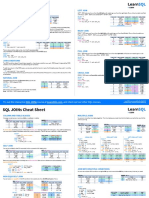
- SQL JOIN Cheat SheetDocument2 pagesSQL JOIN Cheat SheetMOHAN SNo ratings yet
- 3.1 JDBC PrinciplesDocument4 pages3.1 JDBC PrinciplesravicsNo ratings yet
- Dbms Lab Manual23-24Document47 pagesDbms Lab Manual23-24qz5jq94yh2No ratings yet
- 0563 ConfigODBCConnToSAPHANA H2LDocument10 pages0563 ConfigODBCConnToSAPHANA H2Lanon_236308513No ratings yet